
并发编程之IO多路复用及几种IO模式
目录:
- I/O多路复用
- 几种I/O模式,阻塞,非阻塞;同步,异步;信号驱动IO
并发是现如今不可忽视的课题,我们主要将并发性看做是一种内核用来运行多个应用程序的策略,但并发性也不仅仅局限于内核,它在应用程序中也扮演重要角色。比如:
- 在多处理器上进行并行运算,包括单服务器多核CPU,或者分布式的服务器;
- 访问慢速I/O设备。当一个应用等待慢速I/O设备的数据时,可以运行其他进程,通过交替执行I/O请求,实现并发性;
- 服务多个客户端,http server之类的;
目前操作系统主要提供三种实现并发程序的方法:
- I/O多路复用;
- 多进程;
- 多线程;
- 协程;
在介绍模型之前,先来看一个普通的IO操作的流程:
Unix系统的几种I/O模式:
- 阻塞式I/O;
- 非阻塞式I/O;
- I/O多路复用(select,poll,epoll...);
- 异步I/O(POSIX的aio_系列函数);
- 信号驱动IO
IO设备主要包括字符设备(键盘,串口等等),块设备(磁盘,软盘等等)以及网络设备。任何一种IO操作都是IO设备和CPU的交互,每个IO操作可以分为数据准备以及数据操作两个步骤。数据准备是将IO设备写入或读入缓冲区,数据操作是完成读或者写操作。下面的阻塞非阻塞或者同步异步也是从整个IO操作过程来说的。
阻塞式I/O
默认情况,socket是阻塞I/O,就拿我上面第一个的例子来说,recv会一直阻塞等待客户端发送数据,在未收到数据前,就一直阻塞,当收到数据后,recv才返回;
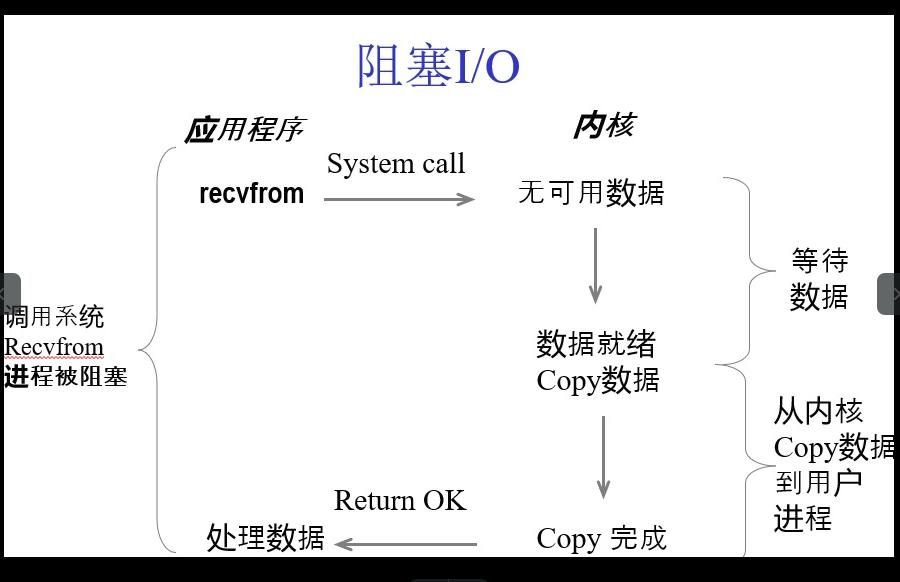
我们都直到Socket操作默认是阻塞的,当我们建立一个Server时,如果不使用多进程或者多线程,一个Server一次只能处理一次请求。如下面例子:
Server
import socket
class BaseSocket(object):
def __init__(self,host,port,trans_type='TCP'):
self.host,self.port = host,port
if trans_type == 'TCP':
self.socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
elif trans_type == 'UDP':
self.socket = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
else:
raise TypeError('the type must be TCP or UDP')
import traceback
from basesocket import BaseSocket
import select
class Server(BaseSocket):
def __init__(self,host,port,trans_type='TCP'):
super(Server,self).__init__(host,port,trans_type)
def run(self,connect_num=1):
self.socket.bind((self.host,self.port))
print 'start server'
self.socket.listen(connect_num)
print 'Server has started successfully!Listening at {0}'.format(self.port)
while 1:
print 'wait client'
try:
clientsock,cliendaddr = self.socket.accept()
except KeyboardInterrupt:
raise
except:
print traceback.print_exc()
continue
print 'Get connection from {0}'.format(clientsock.getpeername())
while 1:
recv_data = clientsock.recv(1024)
if recv_data == 'q':
print 'Client {0} has exited'.format(clientsock.getpeername())
break
print 'Client:{0}'.format(recv_data)
clientsock.sendall(raw_input('Server:'))
clientsock.close()
看服务器的这段代码,当已经有一个客户端建立连接后,再有其他客户端发出请求时,如果已连接的客户端不断开,就不会响应其他客户端。只有一个连接启动一个进程或者线程去解决这个问题。
非阻塞式I/O
对于非阻塞,书中给出定义:“ 进程把一个套接字设置成非阻塞是在通知内核,当所请求的I/O操作非得把本进程投入睡眠才能完成时,不要把进程投入睡眠,而是返回一个错误。 ”这里强调非阻塞只是在数据准备的过程。
如果将socket设置成非阻塞,那么recv总是立即返回,如果数据没有准备好,就会一直发送错误。

我们把第一个代码稍微变动一下,将I/O设置成非阻塞的。
class Server(BaseSocket):
def __init__(self,host,port,trans_type='TCP'):
super(Server,self).__init__(host,port,trans_type)
def run(self,connect_num=1):
self.socket.bind((self.host,self.port))
self.socket.listen(connect_num)
while 1:
try:
clientsock,cliendaddr = self.socket.accept()
#将socket设置成非阻塞
clientsock.setblocking(False)
except KeyboardInterrupt:
raise
while 1:
try:
recv_data = clientsock.recv(1024)
except:
print 'Server can not receive data from client data '
continue
print 'Client:{0}'.format(recv_data)
clientsock.sendall(raw_input('Server:'))
clientsock.close()
看上面代码,我们设置成了非阻塞,如果对方没有准备好数据的时候,recv就会返回一个错误,直到Server检测到客户端准备好数据了。它和阻塞的区别是在数据准备阶段不是一直阻塞,而是如果数据没有准备好,会返回一个错误码。然后不断轮询,直到数据准备好。当然将数据拷贝给用户进程空间,同样是阻塞过程。因此本质上也是同步的。
注意这个非阻塞NIO和JAVA中的NIO,完全不是一个概念,JAVA的NIO是New IO是基于下面的多路复用epoll机制实现的一种方式。
I/O多路复用
IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程 。在这种并发编程中,应用程序在一个进程的上下文进行调度,所有的流共享同一套地址空间。
与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
I/O复用,操作系统 通过一种机制,可以监视多个描述符(socket),一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。文件描述符是Linux中的一个概念。在Linux中,一切都是文件,比如一个socket文件。文件描述符表示了打开文件的索引,指向的是对应的文件。文件描述符有系统级的还有进程级的。
一个 Linux 进程启动后,会在内核空间中创建一个 PCB 控制块,PCB 内部有一个文件描述符表(File descriptor table),记录着当前进程所有可用的文件描述符,即当前进程所有打开的文件。
目前机制包括select,poll,epoll等。 虽然他们有所不同,但基本原理都是会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。有时也会被称为事件驱动型IO。
1、select
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
readfd : 监视的可读描述符集合,只要有文件描述符即将进行读操作,这个文件描述符就存储到这。
writefds : 监视的可写描述符集合。
exceptfds : 监视的错误异常描述符集合
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但 是这样也会造成效率的降低。
ulimit -n 可以查勘用户级限制。当然这个值,是可以修改的。但怎么说都是有限制的。具体可以参考: https://zhuanlan.zhihu.com/p/143430585
我用Python实现了select机制,可看如下代码:
注:BaseSocket仍然是上面代码中的基类。
import traceback
from basesocket import BaseSocket
import select
class Server(BaseSocket):
def __init__(self,host,port,trans_type='TCP'):
super(Server,self).__init__(host,port,trans_type)
#读文件描述符,写文件描述符,异常描述符,都是集合
self.readfds, self.writefds, self.exceptfds = [self.socket,], [] ,[]
def run(self,connect_num=1):
self.socket.bind((self.host,self.port))
print 'start server'
self.socket.listen(connect_num)
print 'Server has started successfully!Listening at {0}'.format(self.port)
#循环监听,利用select机制
while 1:
readfds, writefds, exceptfds = select.select(self.readfds,self.writefds,self.exceptfds,3)
#如果此时没有任何的I/O操作,就继续监听
if not readfds or writefds or exceptfds:
print 'IO IDLE'
continue
for sock in readfds:
#如果是新的连接请求,就将其加入读文件描述符中
if sock == self.socket:
try:
clientsock,cliendaddr = self.socket.accept()
print 'Get connection from {0}'.format(clientsock.getpeername())
self.readfds.append(clientsock)
except KeyboardInterrupt:
raise
except:
print traceback.print_exc()
else:
#表示已连接的客户端,接收客户端数据
recv_data = sock.recv(1024)
if recv_data == 'q':
print 'Client {0} has exited'.format(sock.getpeername())
print '{0}:{1}'.format(sock.getpeername(),recv_data)
try:
sock.sendall(raw_input('Server:'))
except:
self.readfds.remove(sock)
if __name__ == "__main__":
server = Server('10.13.27.48',5000)
server.run()
我的实验环境:本地server,本地客户端,局域网另外一个客户端。
测试会发现,当已连接的客户端没有IO操作后,如果有新连接请求,Server会去处理这个新的请求。就这样,通过select机制,实现了并发。
select的缺点很明显,除了上述说的有最大描述符数量限制之外,还有就是需要线性轮询一个文件描述符集合,性能较差。
此外,它需要维护三个集合,存储FD,开销较大。
基于select的种种缺点,出现了poll和epoll。
2、poll
poll和select有些类似, 指定时间轮询 一定数量的文件描述符,检测其中是否有就绪的socket。但和select不同的是 ,poll使用一个 pollfd的指针实现,而不是像select使用三个位图来表示三个fdset的描述符集合。
指针是指向一组fd及其相关信息的指针,因为这个结构包含的除了fd,还有期待的事件掩码和返回的事件掩码,实质上就是将select的中的fd,传入和传出参数归到一个结构之下,也不再把fd分为三组,也不再硬性规定fd感兴趣的事件,这由调用者自己设定。这样,不使用位图来组织数据,也就不需要位图的全部遍历了。按照一般队列地遍历,每个fd做poll文件操作,检查返回的掩码是否有期待的事件,以及做是否有挂起和错误的必要性检查,如果有事件触发,就可以返回调用了。
结构:
struct pollfd {
int fd; // 需要监视的文件描述符
short events; // 需要内核监视的事件
short revents; // 实际发生的事件
};
poll没有select的最大连接限制。
3、epoll
随着描述符的增大,select和poll的性能会不断地下降,因为 每次调用都需要做一次从内核空间到用户空间的拷贝 。
相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,此外其 利用了mmap ,这样在用户空间和内核空间的copy只需一次。
它使用的结构:
struct eventpoll {
...
struct rb_root rbr;
struct list_head rdllist;
...
};
t/daaikuaichuan/article/details/83862311
rb_root是一个红黑树,存储了所有的事件,可以理解为所有的连接;rdlist是一个链表,存储了所有已经就绪的事件。
epoll主要是通过三个方法来实现整个过程:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
在线程启动时,会调用epoll_create创建一个epoll对象,并通过epoll_ctl添加进来的事件红黑树中。当调用epoll_wait时会检查双向链表里是否有数据,如果有数据就执行内核到用户数据的拷贝。没有就sleep,等到了超时时间,没有数据也会返回的。
好了,再说一下,如何向双向链表中添加就绪事件的。
所有已经添加到epoll对象中的事件,都会与设备控制器,设备(如网卡)驱动程序建立回调关系,当有读写事件发生时,其会调用这里的回调方法ep_poll_callback。其会负责将就绪事件添加到epoll对象的双向链表中。
看一下流程图(来自下面参考资料的大神):
epoll高效的原因总结:
1、不必每次都做内存拷贝;
2、不必轮询遍历所有的文件描述符;
epoll的触发方式是水平触发和边缘触发。
LT水平触发的意思就是只有fd有数据可读,就会触发读操作;ET边缘触发是只有新数据到来,才会触发读,因为它每次是要所有数据都读取走的。对于ET来说,就算是缓冲区有未读尽的数据,也不会触发epoll_wait返回的。边缘触发帮我解决了大量我们不关心的读写就绪文件描述符。
简单看一下Netty中的EpollEventLoop:
this.epollFd = epollFd = Native.newEpollCreate();
this.eventFd = eventFd = Native.newEventFd();
try {
// It is important to use EPOLLET here as we only want to get the notification once per
// wakeup and don't call eventfd_read(...).
Native.epollCtlAdd(epollFd.intValue(), eventFd.intValue(), Native.EPOLLIN | Native.EPOLLET);
} catch (IOException e) {
throw new IllegalStateException("Unable to add eventFd filedescriptor to epoll", e);
}
this.timerFd = timerFd = Native.newTimerFd();
try {
// It is important to use EPOLLET here as we only want to get the notification once per
// wakeup and don't call read(...).
Native.epollCtlAdd(epollFd.intValue(), timerFd.intValue(), Native.EPOLLIN | Native.EPOLLET);
} catch (IOException e) {
throw new IllegalStateException("Unable to add timerFd filedescriptor to epoll", e);
}
success = true;
此外,还要注意一点,I/O复用本质上还是同步I/O,也分为阻塞和非阻塞,但这里强调的阻塞和非阻塞是在select,poll等调用上。
Nginx采用的是多进程+IO多路复用的方式, 其中IO多路复用采用epoll机制,
上面已经说了很多I/O复用,多路复用的阻塞不是在I/O上,而是select,poll等系统调用上。通过复用可以实现非阻塞。
上面的三种模式本质上都是同步的,因为在第二阶段,即内核空间到用户进程的环节都是阻塞的。
还有另外一种模式叫异步IO。
异步IO
异步IO不同于同步IO,其整个IO操作的过程都是异步的。用户应用程序首先会利用aio_read(或者aio_write)发起一个IO请求,然后就去做其他的事情,后续的数据准备,以及从内核拷贝到用户空间的两个过程都由系统来做,整个过程都是异步的。当然上面的请求也是需要进入队列排队的,如果排队成功了会返回0,失败了会返回1.
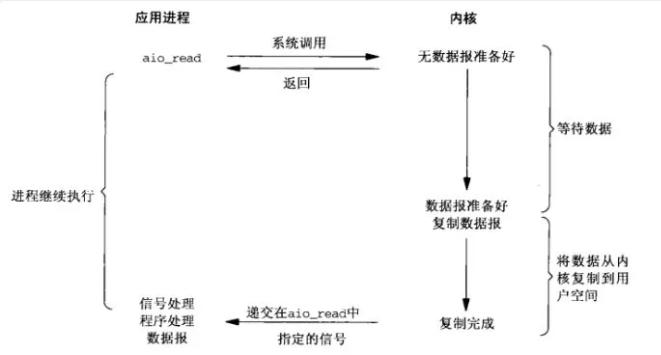
好了,上面的IO操作是完全异步了,但是还是需要一种机制来保证内核完成操作时可以通知我们用户程序的。实际上是可以通过信号,即给进程发信号通知我处理完了,或者回调函数来实现。
但现在Linux的异步IO好像并不是完全成熟,主要它会使用O_DIRECT 的方式来读IO设备,这个模式是绕过缓冲区高速缓存,直接IO。使用直接IO主要有一下的几种限制:
- 用于传递数据的缓冲区,其内存边界必须对齐为块大小的整数倍
- 数据传输的开始点,即文件和设备的偏移量,必须是块大小的整数倍
- 待传递数据的长度必须是块大小的整数倍。
很多的成熟框架也没有直接应用系统的异步IO。目前大多数采用的模式都是通过epoll以及事件驱动的模式来实现异步非阻塞操作。不过像Nginx,自0.8版本开始就支持native aio。Mysql5.6 Innodb开始也支持aio。主要是用在异步IO线程上,用于进程数据文件的读写,用于read ahead以及write操作。
Linux的文件预读readahead,指Linux系统内核将指定文件的某区域预读进页缓存起来,便于接下来对该区域进行读取时,不会因缺页(page fault)而阻塞。因为从内存读取比从磁盘读取要快很多。预读可以有效的减少磁盘的寻道次数和应用程序的I/O等待时间,是改进磁盘读I/O性能的重要优化手段之一。
show engine innodb status;
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
mysql> show variables like 'innodb_use_native_aio';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_use_native_aio | ON |
+-----------------------+-------+
同步 IO和异步 IO的区别
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。POSIX的定义是这样子的:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。
同步IO意味着当我在进行IO操作时,即使是非阻塞I/O,还是需要进程不断地check,不断地询问数据包是否准备好,看上面的例子也可以直观地看到。
而异步I/O则不同,进程会将I/O操作交给内核做,自己可以去做其他的工作,直到内核完成了数据从内科空间到用户空间的拷贝,通过发出信号告诉进程已经完成,再执行其他操作。
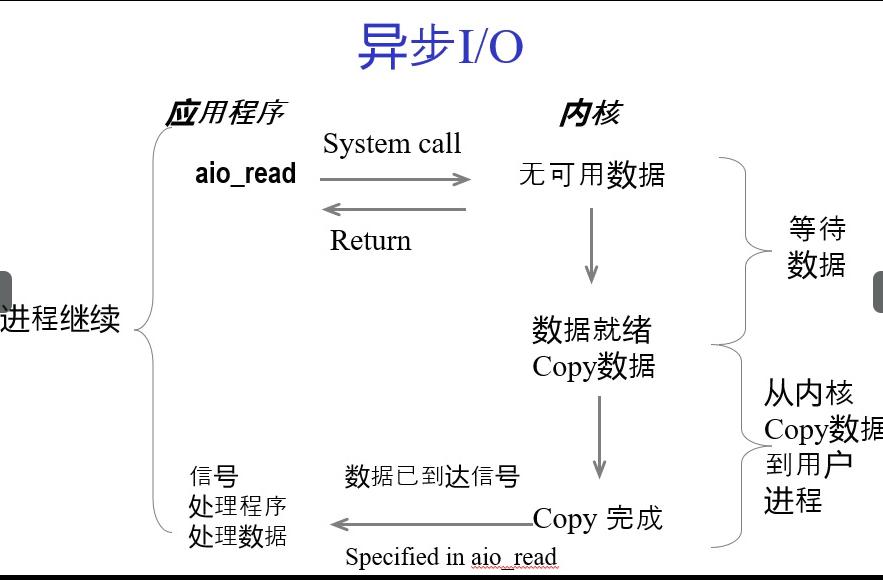
后续我会利用Python进程异步编程。
信号驱动IO
套接字使用信号驱动主要需要进程执行三步:
- 建立 SIGIO 信号处理程序
- 建立套接字属主
- 开启该套接字的信号驱动式 I/O
大体流程:

信号驱动式会通过系统调用先建立 SIGIO 的信号处理函数, 立即返回, 当内核准备好数据, 向用户进程发送 SIGIO 信号, 此时进程可以开始使用 recvfrom 系统调用, 将数据从内核空间拷贝到用户空间。
在Python3中已经有实现好的Selectors:
Classes hierarchy:
BaseSelector
+-- SelectSelector
+-- PollSelector
+-- EpollSelector
+-- DevpollSelector
+-- KqueueSelector
它都在selectors.py这个文件中实现了,我就全部粘贴过来吧。
"""Selectors module.
This module allows high-level and efficient I/O multiplexing, built upon the
`select` module primitives.
"""
from abc import ABCMeta, abstractmethod
from collections import namedtuple
from collections.abc import Mapping
import math
import select
import sys
# generic events, that must be mapped to implementation-specific ones
EVENT_READ = (1 << 0)
EVENT_WRITE = (1 << 1)
def _fileobj_to_fd(fileobj):
"""Return a file descriptor from a file object.
Parameters:
fileobj -- file object or file descriptor
Returns:
corresponding file descriptor
Raises:
ValueError if the object is invalid
"""
if isinstance(fileobj, int):
fd = fileobj
else:
try:
fd = int(fileobj.fileno())
except (AttributeError, TypeError, ValueError):
raise ValueError("Invalid file object: "
"{!r}".format(fileobj)) from None
if fd < 0:
raise ValueError("Invalid file descriptor: {}".format(fd))
return fd
SelectorKey = namedtuple('SelectorKey', ['fileobj', 'fd', 'events', 'data'])
SelectorKey.__doc__ = """SelectorKey(fileobj, fd, events, data)
Object used to associate a file object to its backing
file descriptor, selected event mask, and attached data.
"""
if sys.version_info >= (3, 5):
SelectorKey.fileobj.__doc__ = 'File object registered.'
SelectorKey.fd.__doc__ = 'Underlying file descriptor.'
SelectorKey.events.__doc__ = 'Events that must be waited for on this file object.'
SelectorKey.data.__doc__ = ('''Optional opaque data associated to this file object.
For example, this could be used to store a per-client session ID.''')
class _SelectorMapping(Mapping):
"""Mapping of file objects to selector keys."""
def __init__(self, selector):
self._selector = selector
def __len__(self):
return len(self._selector._fd_to_key)
def __getitem__(self, fileobj):
try:
fd = self._selector._fileobj_lookup(fileobj)
return self._selector._fd_to_key[fd]
except KeyError:
raise KeyError("{!r} is not registered".format(fileobj)) from None
def __iter__(self):
return iter(self._selector._fd_to_key)
class BaseSelector(metaclass=ABCMeta):
"""Selector abstract base class.
A selector supports registering file objects to be monitored for specific
I/O events.
A file object is a file descriptor or any object with a `fileno()` method.
An arbitrary object can be attached to the file object, which can be used
for example to store context information, a callback, etc.
A selector can use various implementations (select(), poll(), epoll()...)
depending on the platform. The default `Selector` class uses the most
efficient implementation on the current platform.
"""
@abstractmethod
def register(self, fileobj, events, data=None):
"""Register a file object.
Parameters:
fileobj -- file object or file descriptor
events -- events to monitor (bitwise mask of EVENT_READ|EVENT_WRITE)
data -- attached data
Returns:
SelectorKey instance
Raises:
ValueError if events is invalid
KeyError if fileobj is already registered
OSError if fileobj is closed or otherwise is unacceptable to
the underlying system call (if a system call is made)
Note:
OSError may or may not be raised
"""
raise NotImplementedError
@abstractmethod
def unregister(self, fileobj):
"""Unregister a file object.
Parameters:
fileobj -- file object or file descriptor
Returns:
SelectorKey instance
Raises:
KeyError if fileobj is not registered
Note:
If fileobj is registered but has since been closed this does
*not* raise OSError (even if the wrapped syscall does)
"""
raise NotImplementedError
def modify(self, fileobj, events, data=None):
"""Change a registered file object monitored events or attached data.
Parameters:
fileobj -- file object or file descriptor
events -- events to monitor (bitwise mask of EVENT_READ|EVENT_WRITE)
data -- attached data
Returns:
SelectorKey instance
Raises:
Anything that unregister() or register() raises
"""
self.unregister(fileobj)
return self.register(fileobj, events, data)
@abstractmethod
def select(self, timeout=None):
"""Perform the actual selection, until some monitored file objects are
ready or a timeout expires.
Parameters:
timeout -- if timeout > 0, this specifies the maximum wait time, in
seconds
if timeout <= 0, the select() call won't block, and will
report the currently ready file objects
if timeout is None, select() will block until a monitored
file object becomes ready
Returns:
list of (key, events) for ready file objects
`events` is a bitwise mask of EVENT_READ|EVENT_WRITE
"""
raise NotImplementedError
def close(self):
"""Close the selector.
This must be called to make sure that any underlying resource is freed.
"""
pass
def get_key(self, fileobj):
"""Return the key associated to a registered file object.
Returns:
SelectorKey for this file object
"""
mapping = self.get_map()
if mapping is None:
raise RuntimeError('Selector is closed')
try:
return mapping[fileobj]
except KeyError:
raise KeyError("{!r} is not registered".format(fileobj)) from None
@abstractmethod
def get_map(self):
"""Return a mapping of file objects to selector keys."""
raise NotImplementedError
def __enter__(self):
return self
def __exit__(self, *args):
self.close()
class _BaseSelectorImpl(BaseSelector):
"""Base selector implementation."""
def __init__(self):
# this maps file descriptors to keys
self._fd_to_key = {}
# read-only mapping returned by get_map()
self._map = _SelectorMapping(self)
def _fileobj_lookup(self, fileobj):
"""Return a file descriptor from a file object.
This wraps _fileobj_to_fd() to do an exhaustive search in case
the object is invalid but we still have it in our map. This
is used by unregister() so we can unregister an object that
was previously registered even if it is closed. It is also
used by _SelectorMapping.
"""
try:
return _fileobj_to_fd(fileobj)
except ValueError:
# Do an exhaustive search.
for key in self._fd_to_key.values():
if key.fileobj is fileobj:
return key.fd
# Raise ValueError after all.
raise
def register(self, fileobj, events, data=None):
if (not events) or (events & ~(EVENT_READ | EVENT_WRITE)):
raise ValueError("Invalid events: {!r}".format(events))
key = SelectorKey(fileobj, self._fileobj_lookup(fileobj), events, data)
if key.fd in self._fd_to_key:
raise KeyError("{!r} (FD {}) is already registered"
.format(fileobj, key.fd))
self._fd_to_key[key.fd] = key
return key
def unregister(self, fileobj):
try:
key = self._fd_to_key.pop(self._fileobj_lookup(fileobj))
except KeyError:
raise KeyError("{!r} is not registered".format(fileobj)) from None
return key
def modify(self, fileobj, events, data=None):
try:
key = self._fd_to_key[self._fileobj_lookup(fileobj)]
except KeyError:
raise KeyError("{!r} is not registered".format(fileobj)) from None
if events != key.events:
self.unregister(fileobj)
key = self.register(fileobj, events, data)
elif data != key.data:
# Use a shortcut to update the data.
key = key._replace(data=data)
self._fd_to_key[key.fd] = key
return key
def close(self):
self._fd_to_key.clear()
self._map = None
def get_map(self):
return self._map
def _key_from_fd(self, fd):
"""Return the key associated to a given file descriptor.
Parameters:
fd -- file descriptor
Returns:
corresponding key, or None if not found
"""
try:
return self._fd_to_key[fd]
except KeyError:
return None
class SelectSelector(_BaseSelectorImpl):
"""Select-based selector."""
def __init__(self):
super().__init__()
self._readers = set()
self._writers = set()
def register(self, fileobj, events, data=None):
key = super().register(fileobj, events, data)
if events & EVENT_READ:
self._readers.add(key.fd)
if events & EVENT_WRITE:
self._writers.add(key.fd)
return key
def unregister(self, fileobj):
key = super().unregister(fileobj)
self._readers.discard(key.fd)
self._writers.discard(key.fd)
return key
if sys.platform == 'win32':
def _select(self, r, w, _, timeout=None):
r, w, x = select.select(r, w, w, timeout)
return r, w + x, []
else:
_select = select.select
def select(self, timeout=None):
timeout = None if timeout is None else max(timeout, 0)
ready = []
try:
r, w, _ = self._select(self._readers, self._writers, [], timeout)
except InterruptedError:
return ready
r = set(r)
w = set(w)
for fd in r | w:
events = 0
if fd in r:
events |= EVENT_READ
if fd in w:
events |= EVENT_WRITE
key = self._key_from_fd(fd)
if key:
ready.append((key, events & key.events))
return ready
class _PollLikeSelector(_BaseSelectorImpl):
"""Base class shared between poll, epoll and devpoll selectors."""
_selector_cls = None
_EVENT_READ = None
_EVENT_WRITE = None
def __init__(self):
super().__init__()
self._selector = self._selector_cls()
def register(self, fileobj, events, data=None):
key = super().register(fileobj, events, data)
poller_events = 0
if events & EVENT_READ:
poller_events |= self._EVENT_READ
if events & EVENT_WRITE:
poller_events |= self._EVENT_WRITE
try:
self._selector.register(key.fd, poller_events)
except:
super().unregister(fileobj)
raise
return key
def unregister(self, fileobj):
key = super().unregister(fileobj)
try:
self._selector.unregister(key.fd)
except OSError:
# This can happen if the FD was closed since it
# was registered.
pass
return key
def modify(self, fileobj, events, data=None):
try:
key = self._fd_to_key[self._fileobj_lookup(fileobj)]
except KeyError:
raise KeyError(f"{fileobj!r} is not registered") from None
changed = False
if events != key.events:
selector_events = 0
if events & EVENT_READ:
selector_events |= self._EVENT_READ
if events & EVENT_WRITE:
selector_events |= self._EVENT_WRITE
try:
self._selector.modify(key.fd, selector_events)
except:
super().unregister(fileobj)
raise
changed = True
if data != key.data:
changed = True
if changed:
key = key._replace(events=events, data=data)
self._fd_to_key[key.fd] = key
return key
def select(self, timeout=None):
# This is shared between poll() and epoll().
# epoll() has a different signature and handling of timeout parameter.
if timeout is None:
timeout = None
elif timeout <= 0:
timeout = 0
else:
# poll() has a resolution of 1 millisecond, round away from
# zero to wait *at least* timeout seconds.
timeout = math.ceil(timeout * 1e3)
ready = []
try:
fd_event_list = self._selector.poll(timeout)
except InterruptedError:
return ready
for fd, event in fd_event_list:
events = 0
if event & ~self._EVENT_READ:
events |= EVENT_WRITE
if event & ~self._EVENT_WRITE:
events |= EVENT_READ
key = self._key_from_fd(fd)
if key:
ready.append((key, events & key.events))
return ready
if hasattr(select, 'poll'):
class PollSelector(_PollLikeSelector):
"""Poll-based selector."""
_selector_cls = select.poll
_EVENT_READ = select.POLLIN
_EVENT_WRITE = select.POLLOUT
if hasattr(select, 'epoll'):
class EpollSelector(_PollLikeSelector):
"""Epoll-based selector."""
_selector_cls = select.epoll
_EVENT_READ = select.EPOLLIN
_EVENT_WRITE = select.EPOLLOUT
def fileno(self):
return self._selector.fileno()
def select(self, timeout=None):
if timeout is None:
timeout = -1
elif timeout <= 0:
timeout = 0
else:
# epoll_wait() has a resolution of 1 millisecond, round away
# from zero to wait *at least* timeout seconds.
timeout = math.ceil(timeout * 1e3) * 1e-3
# epoll_wait() expects `maxevents` to be greater than zero;
# we want to make sure that `select()` can be called when no
# FD is registered.
max_ev = max(len(self._fd_to_key), 1)
ready = []
try:
fd_event_list = self._selector.poll(timeout, max_ev)
except InterruptedError:
return ready
for fd, event in fd_event_list:
events = 0
if event & ~select.EPOLLIN:
events |= EVENT_WRITE
if event & ~select.EPOLLOUT:
events |= EVENT_READ
key = self._key_from_fd(fd)
if key:
ready.append((key, events & key.events))
return ready
def close(self):
self._selector.close()
super().close()
if hasattr(select, 'devpoll'):
class DevpollSelector(_PollLikeSelector):
"""Solaris /dev/poll selector."""
_selector_cls = select.devpoll
_EVENT_READ = select.POLLIN
_EVENT_WRITE = select.POLLOUT
def fileno(self):
return self._selector.fileno()
def close(self):
self._selector.close()
super().close()
if hasattr(select, 'kqueue'):
class KqueueSelector(_BaseSelectorImpl):
"""Kqueue-based selector."""
def __init__(self):
super().__init__()
self._selector = select.kqueue()
def fileno(self):
return self._selector.fileno()
def register(self, fileobj, events, data=None):
key = super().register(fileobj, events, data)
try:
if events & EVENT_READ:
kev = select.kevent(key.fd, select.KQ_FILTER_READ,
select.KQ_EV_ADD)
self._selector.control([kev], 0, 0)
if events & EVENT_WRITE:
kev = select.kevent(key.fd, select.KQ_FILTER_WRITE,
select.KQ_EV_ADD)
self._selector.control([kev], 0, 0)
except:
super().unregister(fileobj)
raise
return key
def unregister(self, fileobj):
key = super().unregister(fileobj)
if key.events & EVENT_READ:
kev = select.kevent(key.fd, select.KQ_FILTER_READ,
select.KQ_EV_DELETE)
try:
self._selector.control([kev], 0, 0)
except OSError:
# This can happen if the FD was closed since it
# was registered.
pass
if key.events & EVENT_WRITE:
kev = select.kevent(key.fd, select.KQ_FILTER_WRITE,
select.KQ_EV_DELETE)
try:
self._selector.control([kev], 0, 0)
except OSError:
# See comment above.
pass
return key
def select(self, timeout=None):
timeout = None if timeout is None else max(timeout, 0)
max_ev = len(self._fd_to_key)
ready = []
try:
kev_list = self._selector.control(None, max_ev, timeout)
except InterruptedError:
return ready
for kev in kev_list:
fd = kev.ident
flag = kev.filter
events = 0
if flag == select.KQ_FILTER_READ:
events |= EVENT_READ
if flag == select.KQ_FILTER_WRITE:
events |= EVENT_WRITE
key = self._key_from_fd(fd)
if key:
ready.append((key, events & key.events))
return ready
def close(self):
self._selector.close()
super().close()
# Choose the best implementation, roughly:
# epoll|kqueue|devpoll > poll > select.
# select() also can't accept a FD > FD_SETSIZE (usually around 1024)
if 'KqueueSelector' in globals():
DefaultSelector = KqueueSelector
elif 'EpollSelector' in globals():
DefaultSelector = EpollSelector
elif 'DevpollSelector' in globals():
DefaultSelector = DevpollSelector
elif 'PollSelector' in globals():
DefaultSelector = PollSelector
else:
DefaultSelector = SelectSelector
参考资料:
高性能IO模型分析-Reactor模式和Proactor模式(二)
微信分享/微信扫码阅读

