
Elasticsearch学习初篇
工作了好几年,一直也都没有用上Elasticsearch,周边的同事有的已经用了,但我们却没有机会用。
自己在做的网上商城有商品搜索功能,所以我希望借此机会好好地学习一下Elasticsearch。
官网的教程还是挺细致的,没有必要在这里重新写一遍了,就是下面参考资料的权威指南。
可以选择docker安装,也可以直接在主机下载压缩包安装。压缩包里有启动脚本,单机的比较好操作。当然单机只适合学习,因为它本身就是一个分布式存储引擎,在实际应用中不可能用单机的。
ES的高性能主要得益于其特殊的数据存储结构:倒排索引,一种单词-文档的数据结构。文档是ES中比较基础的内容,相当于一条记录的数据。
这里说下倒排索引的产生过程。比如说,现在某个索引下的文档数据如下:
| 文档1 | 年度目标 |
| 文档2 | AI技术生态部的年度目标 |
| 文档3 | AI市场的年度目标 |
其产生的倒排索引如下:
| 单词ID | 单词 | 逆向文档频率 | 倒排列表 |
|---|---|---|---|
| 1 | 目标 | 3 | (1;1;<1>),(2;1;<5>),(3;1;<4>) |
| 2 | 年度 | 3 | (1;1;<2>),(2;1;<4>),(3;1;<3>) |
| 3 | AI | 2 | (2;1;<1>),(3;1;<1>) |
| 4 | 技术 | 1 | (2;1;<2>) |
| 5 | 生态 | 1 | (2;1;<3>) |
| 6 | 市场 | 1 | (3;1;<2>) |
倒排列表的含义就是 在第几个文档,出现过几次,在第几个单词。
搜索后,会根据匹配情况,返回命中的结果。比如:
curl -XPOST http://localhost:9200/haibo/_search?pretty=true -H 'Content-Type:application/json' -d' {
"query" : { "match" : { "content" : "向中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
'
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.315783,
"hits" : [
{
"_index" : "haibo",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.315783,
"_source" : {
"content" : "如果有一天DD有国家向中国发起了战争,一定会有很多人勇往直前"
},
"highlight" : {
"content" : [
"如果有一天DD有国家<tag1>向</tag1><tag1>中国</tag1>发起了战争,一定会有很多人勇往直前"
]
}
},
{
"_index" : "haibo",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9186288,
"_source" : {
"content" : "中国是个好地方"
},
"highlight" : {
"content" : [
"<tag1>中国</tag1>是个好地方"
]
}
}
]
}
}
搜索的结果中包含了匹配的结果,每个数据都有评分,倒序排列。
上面所说的倒排索引使得基于Lucene的ES查找速度更快。简单说它的思想是尽量将数据放在内存中,减少磁盘读取此书,并通过各种压缩技术,提高内存使用率。
上面的例子中,单词是Term,而后面的列表存储的是文档列表,其被称为Posting list。
此外,还有一个Term Dictorary的概念,其目的就是将Term排序,提高检索效率。其存储的就是元数据信息。
为了提高查询效率,希望将Term Dictorary放到内存中,然而实际上,Term Dictorary可能很大,没办法全部都放到内存中,因为出现了Term Index,其存储了倒排索引文件。Term Index在内存中是以FST(finite state transducers)存储实现的,思想就是使用字节存储所有的term index,非常节省内存,具体的可以看下面的参考资料。
目前,对于ES的客户端很多,官方对于不同语言都有相应的推荐,甚至都可以自己写,因为可以通过http访问。对于Java,使用官方推荐的 high level rest client,(不用springboot的spring-data-redis-elasticsearch)。
就介绍简单的使用。
引入:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>就算使用高阶API client,也要引入其他两个,因为高阶的也依赖基础的操作。
基本操作:
@Configuration
public class EsConfiguration {
@Value("${spring.elasticsearch.host}")
public String host;
@Value(("${spring.elasticsearch.port}"))
public int port;
@Value("${spring.elasticsearch.scheme}")
public String scheme;
@Bean
public RestHighLevelClient restHighLevelClient(){
return new RestHighLevelClient(
RestClient.builder(
new HttpHost(host, port, scheme)
)
);
}
}
@Component
public class HighRestClientDao {
@Autowired
RestHighLevelClient restHighLevelClient;
public boolean createIndex(String indexName, Map<String,Map<String,Object>> properties) throws Exception {
// XContentBuilder xContentBuilder = XContentFactory.jsonBuilder();
// xContentBuilder.startObject();
// xContentBuilder
// .startObject("mapping")
// .field("properties",properties)
// .endObject()
//// .startObject("settings")
// ;
// xContentBuilder.endObject();
// CreateIndexRequest createIndexRequest = new CreateIndexRequest(indexName).source(xContentBuilder);
CreateIndexRequest createIndexRequest = new CreateIndexRequest(indexName);
Map<String,Object> mapping = new HashMap<>();
mapping.put("properties",properties);
createIndexRequest.mapping(mapping);
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
log.info("get create index,request:{} response:{}",createIndexRequest,createIndexResponse);
return createIndexResponse.isAcknowledged();
}
public boolean isExistIndex(String indexName) throws Exception{
GetIndexRequest getIndexRequest = new GetIndexRequest(indexName);
getIndexRequest.humanReadable(true);
getIndexRequest.includeDefaults(false);
getIndexRequest.local(false);
return restHighLevelClient.indices().exists(getIndexRequest,RequestOptions.DEFAULT);
}
public boolean deleteIndex(String indexName) throws Exception {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(indexName);
deleteIndexRequest.timeout("1m");
return restHighLevelClient.indices().delete(deleteIndexRequest,RequestOptions.DEFAULT).isAcknowledged();
}
}
关于文档的删除操作:
Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更。但是API是有删除或改动的。
磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段。
对于更新操作。在新的文档被创建时,Elasticsearch会为该文档指定一个版本号。当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
刚开始学习,看到number_of_shards以及replicas的概念,不是很懂。看了文档才理解。
在Lucence中,分片是index的实例,一个索引会有一个或者多个分片。
通过在集群中设置多个分片,有点分而治之的意思,在进行查询时,多个分片会同时进行,最后将所有分片的数据进行整合。分片数默认是5个。当一个节点的数据量过多时,ES会自动做负载均衡,将数据分配在不同的分片上。然而,ES的一个好处是,多个分片对于用户是无感知的,不用考虑其复杂性。
作者将分片数量设置5个也是综合考量了数据增长的可能性与分片查询带来的开销。
副本:就是主分片的副本,主分片挂掉后,副本会自动成为主分片。
正常情况下,一个集群的节点数量是 分片数 * (副本数+1),因为副本和主分片一样,占用资源。
对于副本,在写入的时候,可以设置所有副本都同步成功了,才返回给客户端;在请求的时候,根据轮询算法,在主分片和副本中选择一个进行读请求,从而实现负载均衡。
有了分片,带来一个最直观的问题就是查询时,正常会查询所有分片,然后等待所有分片查询后,将所有结果进行合并。这势必带来了一定的开销。因此ES中有一个概念叫做路由。
如果我们在插入时,指定了使用什么路由,那么在查询时,也可以根据我们设定的路由来查询,根据路由,ES会到指定的shard上进行查询,而不用查询所有分片。
分片默认算法:
shard_num = hash(_routing) % num_primary_shards
_routing可以指定。
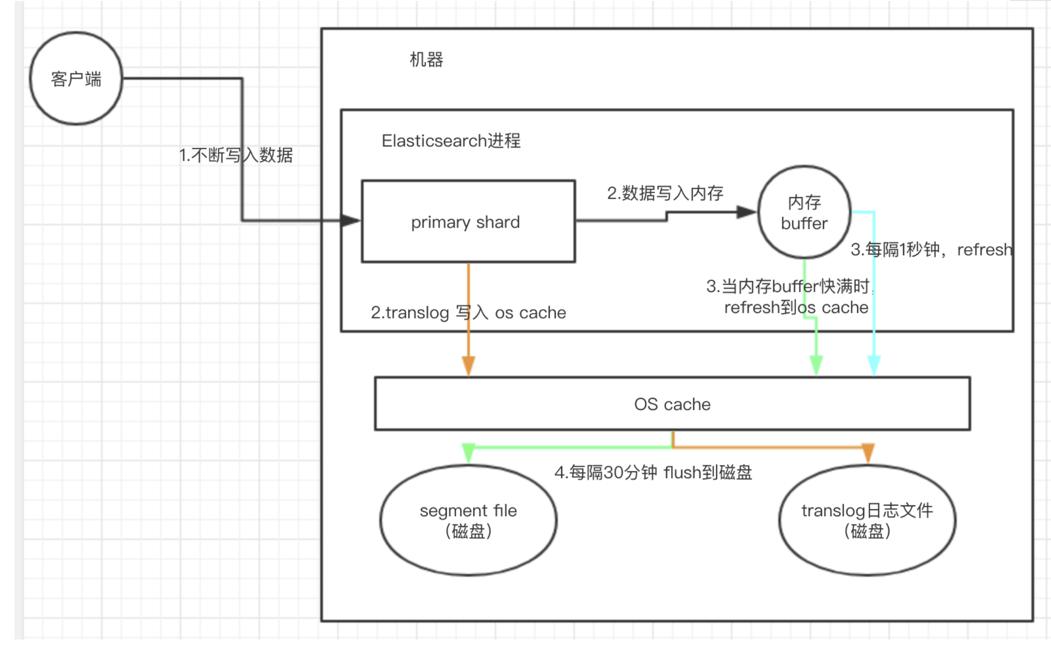
再说下ES的近乎实时的搜索机制,实时搜索指的是数据写入之后可近乎实时搜索到数据。
ES在写入时数据会先写入到进程buffer里,随后数据会copy到PageCache中,随后1s中会定时刷盘。
此外,为了避免宕机后,数据丢失,ES增加了一个用于崩溃回复的日志,transferlog。ES使用translog来记录所有的操作,我们称之为WAL,当新增一条记录时,es会把数据写到translog和buffer中。类是一个索引分片层级的组件,这个日志的作用就是将没有提交的索引操作记录下来。但是,这并不能说明,有了tanslog就不会造成数据丢失,这还要和操作系统的pagecache有关。因为数据首先会写入到pagecache,然后定时(默认5s)刷盘的,因此如果写入到pageCache后,如果在刷盘前断电了,还是会出现数据丢失的,但这个问题是所有文件写入都会遇到的,这个是不可控的。所以tansferlog在一定程度上避免因为ES进程本身挂掉导致的数据丢失。
下面示意图是ES的一个写入流程图:
参考资料:
Elasticsearch原理学习--为什么Elasticsearch/Lucene检索可以比MySQL快?
Day 7 - Elasticsearch中数据是如何存储的
掌握它才说明你真正懂 Elasticsearch - ES(三)
微信分享/微信扫码阅读

