
MySQL知识积累
一、MySQL中myisam与innodb的区别
MyISAM和InnoDB都是MySQL的存储引擎,服务器通过API和底层存储引擎进行通信,存储引擎API封装了很多的底层函数,使得不对具体的存储引擎相互区分,目前用的最多的就是MyISAM和InnoDB。但两者也有很多不同。
- MyISAM不支持事务,InnoDB支持事务。InnoDB是默认的事务性引擎;这也注定了对于写操作比较多,或者表比较大的情况,最好不用MyISAM。
- MyISAM支持表锁,InnoDB支持行锁。这也注定了在并发性能上,MyISAM的表锁的特性是最大的瓶颈;
- MyISAM不支持外键,InnoDB支持外键;
- MyISAM支持全文索引,InnoDB不支持全文索引;
- InnoDB支持MVCC,MyISAM不支持。
二、mysqldump
mysqldump用来备份数据库还是比较有用的,这里说一下看到的题:
1、要把insert的每一行都单行显示。
只需加上--skip-extened-insert,就可以实现上述功能:
mysqldump -uroot -p app_dailyblog blog_category --skip-extended-insert >cate.sql
2、从mysqldump中恢复某一个库:
mysql -uroot -p blog_category --one-database < blog.sql三、锁
锁可分为行级锁和表锁,InnoDB都支持,那InnoDB是如何实现行级锁的呢?
锁这方面还是比较复杂的,有很多东西要看。我只知道 InnoDB是基于索引来完成行锁例 。
四、MySQL日志类别
错误日志、查询日志、二进制日志、慢查询日志。
- 错误日志;记录启动,停止mysqld出现的错误;
- 查询日志;记录建立的客户端连接以及所有语句,包括错误的;
- 二进制文件,记录所有更改数据的Sql语句,用于主从复制;
- 慢查询,记录所有查询时间超过 long_query_time的查询;
五、模糊匹配
-
如果 REGEXP 模式与被测试值的任何地方匹配,模式就匹配 ( 这不同于 LIKE 模式匹配,只有与整个值匹配,模式才匹配 ) 。
1. 关键字 regexp等于rlike
http://www.sqlines.com/mysql/regexp_rlike MySQL - REGEXP, RLIKE - Guide, Examples and Alternatives
这两条相同:
select * from users where name regexp '傻'
select * from users where name rlike '傻'
2. like 和rlike区别
这两条返回不一样,like匹配整个字串,rlike是匹配部分。
select * from users where name rlike '傻' select * from users where name like '傻'
rlike的返回结果是这样
六、MySQL的drop,delete,truncate
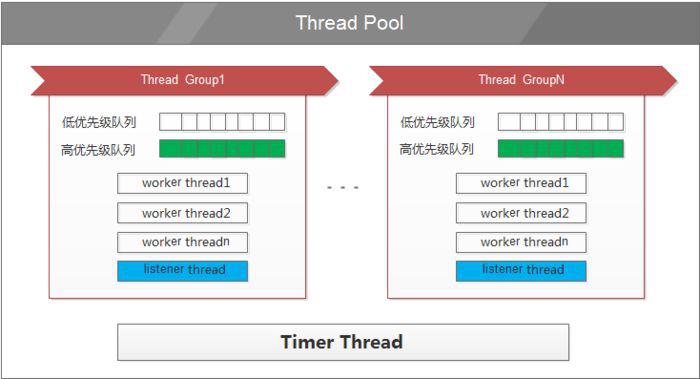
mysql> show variables like 'thread%';
+-------------------------------+-----------------+
| Variable_name | Value |
+-------------------------------+-----------------+
| thread_cache_size | 256 |
| thread_handling | pool-of-threads |
| thread_pool_high_prio_mode | transactions |
| thread_pool_high_prio_tickets | 4294967295 |
| thread_pool_idle_timeout | 60 |
| thread_pool_max_threads | 100000 |
| thread_pool_oversubscribe | 20 |
| thread_pool_size | 40 |
| thread_pool_stall_limit | 50 |
| thread_stack | 196608 |
| thread_statistics | OFF |
+-------------------------------+-----------------+
微信分享/微信扫码阅读

