
垃圾回收机制的实现(php,python,golang,java)
总结一下各个语言的垃圾回收机制。
1、 Python垃圾回收机制 引用: Python垃圾回收机制--完美讲解!
2、Java回收机制
3、Redis垃圾回收
4、Php垃圾回收;
5、Golang的垃圾回收
.......................................................................................................................................................................
1、Python垃圾回收机制
Python主要用三种GC算法,引用计数算法、标记-清除算法、分代回收。其中,Python主要采用的还是引用计数算法,标记清除算法是辅助算法,主要是用于容器对象,比如列表,元祖,字典等等,分代回收是只是建立在标记清除算法上的对不同代的对象进行回收。为此,对于每一个Python对象,其结构体内部都维护了一个计数器。
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
引用计数应该算是发展最早,被利用也最广泛的一种算法,因为其比较简单。但其也有自己本身的一些缺陷,比较在出现循环引用的情况下,可能会导致有一些对象无法始终无法被回收,尽管它们已经不再使用。
例子:
x = [1,2]
y=[2,3]
z=[4]
m=[5]
x.append(y)
y.append(x)
z.append(z)
y.append(m)
a = x
为了解决容器对象的循环引用问题,Python引入了辅助算法:标记-清除算法。简单来说就是两个大阶段,一是对于所有可达的对象进行标记,二是对于所有不可大的对象进行回收。当然,事实不像说的这么简单。
为了实现该算法,Python维护了两个链表,一个用来存放着需要被扫描的对象(Object to Scan),一个是存放暂时不可达的对象(Unreachble),在进行垃圾回收的过程中,两个表存放的对象是不断变化的。
就拿上面的例子中的循环引用来说。此时 x的计数是2,y是1,z也是1,m也是1
具体流程:
- gc会首先扫描Obejct to Scan中的对象, 会将所有对象所引用的对象都减1.此时上面的x的计数变成1,y变成0,z也变成0,也变成0.
- gc会再次扫描该链表中的对象,它会把所有计数为0的标记为GC_TENTATIVELY_UNREACHABLE,并放到Unreachable的链表中,不为0的就放标记为GC_REACHABLE。此时就解决了循环引用的问题。但此时还存在问题,就是有误伤的情况,y,m被标记为不可达了。别着急,接下来还有。
- 对于可达的点,gc会从该节点点触发,顺藤摸瓜,递归地将其所有可达的结点都标记为GC_REACHABLE,那么此时,y,m的引用计数虽然都为0,但还是会标记可达。并再重新将其放到Object to Scan链表中。
- 此时gc会将所有Unreachable链表中的对象进行垃圾回收。就是上述例子中的z.
比较好的文章: Python内存管理
标记清除解决了循环引用的问题,但其每次都要扫描所有对象,效率一般,且进行垃圾回收时,会产生阻塞,应用程序都要先等待垃圾回收结束之后再进行。因此,针对该问题,Python提出了分代收集。
Python中, 引入了分代收集, 一共有三个代,幼年,青年,老年,根据存活时间划分。
Python根据其生存时间来决定放在哪个代,其生存时间越长就意味着越不可能回收,因此应该减少垃圾回收的频率。生存时间越短,就提高回收频率。但话说回来,这种方法只是在一定程度上提高了垃圾回收的效率,其实也并没有完全解决上述提到的问题。
Python 中, 一个代就是一个链表, 所有属于同一代的内存块都在同一个链表。
代码来源于网络!
struct gc_generation {
PyGC_Head head;
int threshold; /* collection threshold */ // 阈值
int count; /* count of allocations or collections of younger
generations */ // 实时个数
};
#define NUM_GENERATIONS 3
#define GEN_HEAD(n) (&generations[n].head)
// 三代都放到这个数组中
/* linked lists of container objects */
static struct gc_generation generations[NUM_GENERATIONS] = {
/* PyGC_Head, threshold, count */
{{{GEN_HEAD(0), GEN_HEAD(0), 0}}, 700, 0}, //700个container, 超过立即触发垃圾回收机制
{{{GEN_HEAD(1), GEN_HEAD(1), 0}}, 10, 0}, // 10个
{{{GEN_HEAD(2), GEN_HEAD(2), 0}}, 10, 0}, // 10个
};
PyGC_Head *_PyGC_generation0 = GEN_HEAD(0);
Python触发垃圾回收机制的情况包括:
- gc.collect()手动触发;
- 程序退出触发;
- 达到阈值触发。
2、Redis的垃圾回收机制(强行乱入)
Redis的垃圾回收机制比较简单,就是使用了引用计数算法。
Redis的每个对象都使用一个结构体来表示,即RedisObject。
#define LRU_BITS 24
typedef struct redisObject { // redis对象
unsigned type:4; // 类型,4bit
unsigned encoding:4; // 编码,4bit
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */ // 24bit
int refcount; // 引用计数
void *ptr; // 指向各种基础类型的指针
} robj;refCount存储了对象引用的次数。那么可能这时候要问了,Redis如何解决循环引用的问题。哈哈,那是因为Redis中根本不会出现循环引用的场景,所有对象的创建和维护都是Redis自己做的,这种情况不会存在。
那么Redis的垃圾回收的触发主要有定时删除和惰性删除,使用的策略就是主要的那几种,比如LRU,TTL等等。具体如下:
# volatile-lru -> remove the key with an expire set using an LRU algorithm
# allkeys-lru -> remove any key according to the LRU algorithm
# volatile-random -> remove a random key with an expire set
# allkeys-random -> remove a random key, any key
# volatile-ttl -> remove the key with the nearest expire time (minor TTL)
# noeviction -> don't expire at all, just return an error on write operations
Redis默认使用的是noeviction.
说一下上面的LRU,Redis中的LRU是采用惰性删除的执行方式,当进行一个操作时,如果超出了最大内存限制,就随机选择5个key(选择什么样的key取决于配置的策略时volatile还是allkeys;选择几个还要根据配置来server.maxmemory_samples),然后淘汰最旧的key。如果内存还超,就继续执行上面的操作,直到低于最大限制。Redis之所以选择这种方式是为了减少额外的消耗。
一篇比较好的文章: redis
用Python实现的一个简单的LRU:
"""
Python实现简单的LRU算法
"""
class HbnnLRU:
def __init__(self, size):
#最大容量
self.max_size = size
#LRU 时钟,每个存储的对象都有一个自己的时钟,这个就是和Redis中 redisObject的lru一样
self.clock = 1
#lru字典以及实际数据字典 lru存储lru每个key的时钟
self.lru = self.data = {}
def get(self, key):
if key in self.data:
self.lru[key] += 1
return self.data[key]
return None
def set(self, key, value):
if self.should_del_oldest_key():
del_key = min(self.lru, key=lambda item_key: self.lru[item_key])
self.data.pop(del_key)
self.lru.pop(del_key)
self.data[key] = value
self.clock += 1
self.lru[key] = self.clock
def should_del_oldest_key(self):
return len(self.data) >= self.max_size上述的也是一种惰性删除的思想,在进行写操作的时侯,如果容量已经超了,那么就开始进行就数据回收。其实Python还有一个更好的实现,是OrderedDict,可以记录插入顺序的字典,可参考: LRU Cache in Python . 看下其内置插入运算符,它也是专门维护了一个双向链表。
class OrderedDict(dict):
# An inherited dict maps keys to values.
# The inherited dict provides __getitem__, __len__, __contains__, and get.
# The remaining methods are order-aware.
# Big-O running times for all methods are the same as regular dictionaries.
# The internal self.__map dict maps keys to links in a doubly linked list.
# The circular doubly linked list starts and ends with a sentinel element.
# The sentinel element never gets deleted (this simplifies the algorithm).
# The sentinel is in self.__hardroot with a weakref proxy in self.__root.
# The prev links are weakref proxies (to prevent circular references).
# Individual links are kept alive by the hard reference in self.__map.
# Those hard references disappear when a key is deleted from an OrderedDict.
def __setitem__(self, key, value,
dict_setitem=dict.__setitem__, proxy=_proxy, Link=_Link):
'od.__setitem__(i, y) <==> od[i]=y'
# Setting a new item creates a new link at the end of the linked list,
# and the inherited dictionary is updated with the new key/value pair.
if key not in self:
self.__map[key] = link = Link()
root = self.__root
last = root.prev
link.prev, link.next, link.key = last, root, key
last.next = link
root.prev = proxy(link)
dict_setitem(self, key, value)类似地,在Java中其实也有,LinkedHashMap中也是可以记录插入顺序的Hash Map,它专门维护了一个双向链表来记录插入顺序。在每次插入操作之后都要执行afterNodeInsertion方法,源码:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}其中removeEldestEntry就是判断是否应该移除老元素的方法。这个默认是false。可以自己Override。
3、PHP的垃圾回收机制
php是C语言开发的,我草,C语言真强!其变量的存储结构是个结构体,如下:
struct _zval_struct {
union {
long lval;
double dval;
struct {
char *val;
int len;
} str;
HashTable *ht;
zend_object_value obj;
} value;
zend_uint refcount__gc; //引用计数
zend_uchar type; //变量类型
zend_uchar is_ref__gc; //是否引用变量
};
从上面的数据结构可以看出来,PHP采用的也是循环引用的计数算法。具体的不用介绍了,在上面也已经说过了。但这势必还会出现循环引用的问题,会又内存泄漏的问题。
php5.3为了解决上述的问题,以及不断扫描所有对象带来的性能问题,引入了新的算法:同步回收算法。该作者的文章: Concurrent Cycle Collection in Reference Counted Systems
具体的算法,我感觉我不用写出来了,直接看官网介绍:php官方介绍: php Manual
但说实话,其思想我觉得和Python的标记清除差不多把。只不过是Python使用了两个链表;而PHP使用的是颜色标记的思想。首先将可能的垃圾放到根缓冲区(缓冲区是一个双向链表),并把其标记为紫色(在Python中是放到Objecy to scan链表),然后如果满了的话,默认是10000(Python中是分代设置了不同的阈值),开始进行垃圾回收过程。注意,放到根缓冲区的变量只包括:其refCount的值在减少,但不是0的这些可能垃圾放到根缓冲区中。这个和Python是不同的,Python是把所有可达的对象都放到Object to Scan中。这也就说明PHP更有效率。,它更有针对性,就是解决可能的循环引用的问题。
具体流程:
- 首先进行深度优先遍历,对所有root可以遍历的对象进行计数减去1,并标记为灰色,主要防止被多次减去1,又时一个对象可能被多个root对象引用。还要说一下,它减1不是所有的都减1,假如当前节点中的某个元素又有指向其节点本身的才会减1,这也是和Python不同的,Python是一把梭哈,然后再二次遍历复原。
- gc再次遍历,算法仍然还是深度优先,然后对计数是0的标记为蓝色,计数不是0的计数值再加1,就是恢复原有值,并标记为黑色。
- 回收所有蓝色标记的节点。
触发机制:
根缓冲区满时自动触发。
4、Golang垃圾回收机制
最初golang的垃圾回收(1.5之前)就是简单的标记清除,性能比较low,俗称STW,在标记清除进行的过程中啥都不能干,任何应用程序都必须停止,只能等着。这对服务端开发简直是不能忍受的。后来又把标记和清除分离,标记的时侯需要STW,然后清除的过程可以单开协程执行,效率得到了提升。
后来又采用了三色标记法(V1.5),且不必扫描所有对象,其具体流程:
1、首先将所有对象都设置为白色;
2、从root对象出发,将所有引用的对象都标记为灰色; 此时时stop the world
3、对于灰色对象再将其引用的对象变为灰色,其本身变为黑色。 此时 start the world
4、如此反复,直到没有灰色对象为止;
5、将所有白色的对象回收。
关键之处:root对象指的是哪些?golang中的root对象包括全局变量和当前时刻运行的栈都是root对象。
但上述还是存在一个问题的,就是在标记的时侯有可能没有被引用的对象,同时被重新被新对象引用了,那么该对象可能就会误被标记为白色,最后被清除。
后来,golang引入了混合屏障。其思想就是在开始标记前开启写屏障,保证有内存操作的时侯可以直接将对象入队,从而进行上述的标记操作。标记之后,回收之前会关闭写屏障。
写屏障采用的算法:
1、Steele算法 当发现黑色对象指向白色对象,那么就把黑色对象变成白色,然后重新扫描;
2、汤浅算法 对于新生成的对象就直接标记为黑色;对于引用的变更,该算法的写入屏障是记录指针删除的操作,当有指针删除的操作的时候,并且被删除的指引指向的是白色的对象,那么我们就把这个白色的对象给标记成灰色。
其实,golang的垃圾回收机制虽然没有Java那么成熟,但是不断优化的,未来可期。
触发机制:
1 、达到阈值。但阈值会不断变大。
2、定时触发。
go的垃圾回收不是立即回收,而是待内存紧张的时侯才回收,这么做主要还是考虑性能吧,和Java类似。因此,综上几点,go占用的内存是不断增大的。
好的文章: GO GC 垃圾回收机制 golang垃圾回收 Golang内存管理
5、Java垃圾回收
JVM的虚拟模型主要包括程序计数器、方法区、JVM栈、本地方法栈、堆等等,其中只有程序计数器是没有内存泄漏的问题,其他的都会涉及到这个问题。具体的关于上述几大部分的介绍可以看这篇文章:
我之前在网上看到一个图,关于JVM垃圾回收的,感觉挺牛逼的,把涉及到的知识点都囊括了。可以点进去看一下: 深入理解JVM垃圾收集机制(JDK1.8)
本文主要介绍JAVA的垃圾回收机制。
目前存在的GC算法:
- 引用计数法;
- 标记-整理算法;
- 标记-清除算法;
- 分代收集算法;
其中引用计数法是一种比较传统粗糙的算法,Java并没采用。剩下的三种在Java中都有涉及,但不是单纯采用某种算法,因为这三种算法都存在一定程度的缺点。JVM将内存划分成代,分情况进行垃圾回收,也就是著名的分代收集算法。
划分情况:
新生代(Young Genaration) MinorGC 采用复制算法 ,其又还划分出Edge suvivor1 suvivor2。
老年代(Old Genaration)
在MinorGC中采用了标记和复制算法。当有可回收对象时,会被标记,并将可用对象移到S1或者S2,然后将标记对象进行清除,此时edge以及(S1或者S2)就空闲出来了。那么问题来了,一个对象如果生命周期较长,要是一直让他在新生代来回复制,必然降低效率。因为针对这个问题,JVM规定一个对象每次移动一个区,年龄+1,当达到一定阈值后,就会被移动到老年代。一般新生代年龄达到15(记录的空间只有4位),就可以移到老年代。Edgen和SUivor的比例是8:1:1,Eden设置大主要是因为大部分对像都会被回收。
对于老年代的GC一般称为Major GC,或者Full GC.网上很多人说两者有区别,也有说没区别的。其实我是觉得怎么说都不为过。Full GC可以包括Minor GC,所以说Full GC范围更广,但Minor GC在Full GC中不是必需的,一般情况下Full GC就是对老年代/永久代的回收。
下面对象说明了触发Full GC的其中一种情况,即要晋升老年代的对象大于老年代的内存空间,会触发Full GC。
下面的图说明了GC的主要过程:
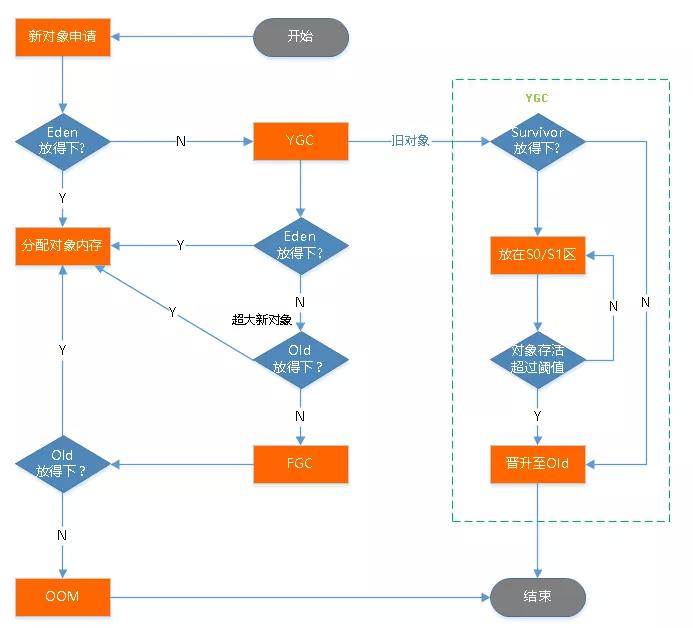
除了上述所说的老年代空间不足时会触发FullGC之外,还有就是当PermanetGeneration空间满时也会触发。
上面说了很多的GC算法,有个问题是,哪些是可回收对象?其实在其他语言种已经都说了,从GC ROOT对象开始,如果没有任何引用链的都是不可达,可回收。那么在Java中哪些是GC ROOT对象呢?
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等;
- 在方法区中类静态属性引用的对象,譬如 Java 类中引用类型的静态变量;
- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用;
- 在本地方法栈中的 JNI(即 Native 方法)引用的对象;
- Java 虚拟机内部的引用,如基本数据类型对应的 Class 对象,一些常驻的异常对象(如 NullPointException,OutOfMemoryError 等)及系统类加载器;
- 所有被同步锁(synchronized 关键字)持有的对象;
- 反应 Java 虚拟机内部情况的 JMXBean,JVMTI 中注册的回调,本地代码缓存等。
上面说的都是一些GC算法,而实现这些算法的叫做垃圾收集器,JVM的收集器有很多种。
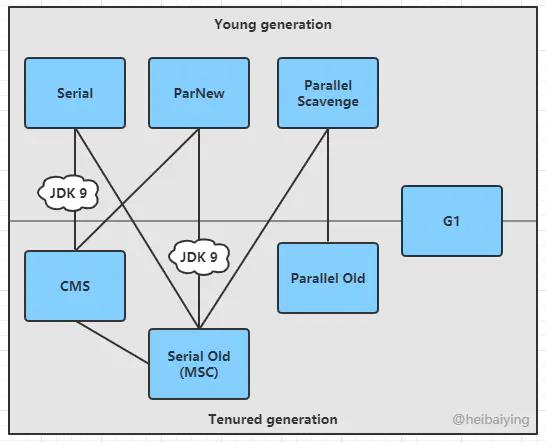
1) Serial 收集器
这种是最古老的一种收集器了,它是单线程版本,在最早的新生代收集中都采用这种算法。这种单线程收集意味着当要进行GC时,就会发生STW。但是,也正因为是单线程,不会存在线程切换的开销,效率很高,且STW的时间一般不长,尤其是对于单CPU的情况。如果GC频率不高,还是很优秀的,这也是为什么现在很多的虚拟机依然把它当作新生代默认的收集器。
该收集器在新生代采用复制算法,老年代采用标记-整理算法。
2) ParNew 收集器
它是Serial收集器的多线程版本,其余完全没区别。因此在多CPU的情况下,它比Serial收集器更高效。
3)Parallel Scavenge 收集器
这是一个新生代收集器,它追求的目标是达到更高的吞吐量。它可以自适应调整参数。
其余几个不说了,主要说下CMS和G1.
CMS收集器
它的目标就是尽可能的所端STW的时间,从而提高GC效率。是老年代的一种收集器。是、也为后续的G1和ZGC奠定了基础。
CMS全称Cocurrent Mark Sweep,它的意思已经很清晰明了了,并发标记清除,其主要经历以下几个过程:
- 标记;
- 并发标记;
- 重新标记;
- 并发清除。

1、初始标记
初始标记会标记所有与GC Root直接关联的对象,这个过程会STW,但耗时较短;
2、并发标记
并发标记所有与GC ROOT有关联的对象,不一定是直接关联的。耗时长,但因为是并发,所以不影响用户进程。
3、重新标记;
重新标记是因为在上述过程中,可能会有新产生的对象,这个过程会STW,但因为新产生的也不会很多,因此耗时也不会很长。
4、并发清除
标记后,开始并发清除,这个过程耗时也相对长一些,但同样是因为并发,并不会出现STW。
上述就是CMS的整个过程,优点很明显,提高了效率,但缺点也很明显,一是它采用标记-清除算法,会产生很多的内存碎片;其次就是在并发清除时,用户进程仍然会产生很多需要清除的垃圾,这部分CMS是无法处理的,这部分被称作是浮动垃圾。
G1收集器
G1收集器是从JDK1.7开始使用的,它的产生很好解决了CMS所产生的碎片化的问题,它是基于标记-整理算法进行垃圾回收。
G1不再像传统的收集器那样,把整个内存区域分成固定的新生代,老年代和永久代。而是把整个区域分成固定大小的区,叫做region,这个region彼此之间是逻辑连续的。且也都较做Eden、Survivor 、Old、Humongous .
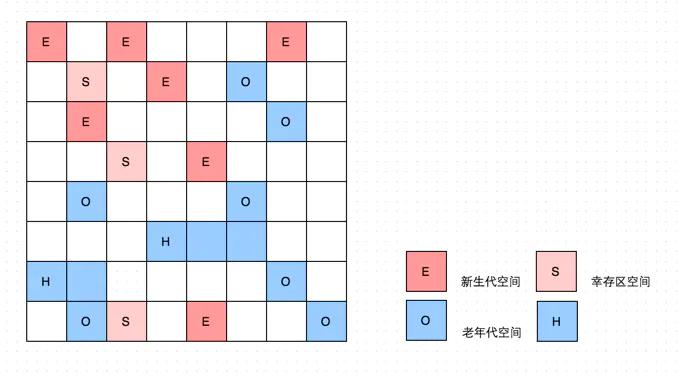
新生代GC:
简单描述其思想就是当Edgen空间耗尽时,会触发 Young GC,Edgen区域可用对象移动到Survivor空间,如果Survivor空间不足,就会移动Old空间。这样Eden空间就空了。
那么对于G1,它是否需要扫描整个老年代对象来标记的。答案是否定的,G1通过记录堆和堆的引用关系来避免扫描整个老年代。每一个region都会记录old->yound的引用,称为RSet。因此扫描时,只需要扫描新生代的区域即可,这样就大大提高了效率。
老年代GC:
也叫MixGC,其实它不止时清理老年代,Young也会清理.官网描述的过程:Initial Mark(STW) -> Root Region Scan -> Cocurrent Marking -> Remark(STW) -> Copying/Cleanup(STW && Concurrent)
简单说下,哪些对象会进入老年代:
1、大对象,会直接进入老年代;
2、拿到阈值年龄的对象,会进入老年代,一般默认是15岁。每经历一次MinorGC且没被回收的,都会增长一岁。
3、在Survivor空间中相同对象年龄的所有对象的大小之和超过了整个Survivor空间的一半,那么所有大哥这个年两的对象都会放到老年代中。
具体可见下面参考资料。
ZGC收集器
是G1的变种,在G1的基础上做了演进。
ZGC把整个堆分成了三种不同粒度的页面,小,中,大。不同页面存储不同大小的页面,从而可以更加细粒度控制内存的分配。
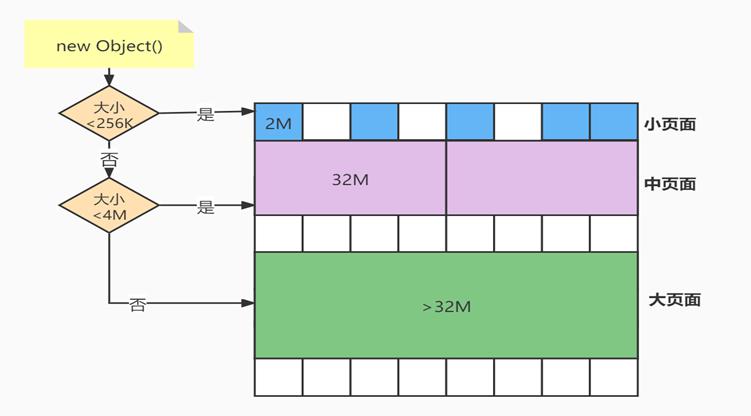
其主要特点是:
-
停顿时间不超过10ms(JDK16 已经达到不超过 1ms);
-
停顿时间不会随着堆的大小,或者活跃对象的大小而增加;
-
支持8MB~4TB级别的堆,JDK15 后已经可以支持 16TB。
其得益于以下几种技术:
1、着色技术。不再像之前三色标记一样,要在对象头MarkWord中做标记,而是使用独立的内存保存指针。
2、内存管理。
参考资料:
《深入理解 JAVA 虚拟机》第三版(2019.12)读书笔记
微信分享/微信扫码阅读

