
网站介绍
该网站利用Django框架搭建,前端采用Bootstrap框架。
之前在应用汇实习的时候接触了Django,他们的Web站就是用Django开发的。不过那时决定先从Flask入手,而且觉得Django太重了,所以就没碰Django。自己一直用Flask。直到工作了,我觉得如果学Python,不学Django,总感觉缺点什么。虽然晚了一些,但Better late than never。因为有了网站开发经验,再加上Django基本不需要安装其他第三方框架及模块,所以开发得比较快。
这个网站我已经维护了一年多了,目前博客支持的功能有:
1、文章的分类浏览,文章的分权限查看;
2、用户的注册、登录。注销、更改密码、忘记密码重置等;
3、dashboard。个人登录用户提供后台管理平台:
- 文章的统计,文章的修改,删除等;
- 个人信息的查看,修改;
- 工作信息查看(目前只有站长我自己有权限,只对我自己开放。)该部分是服务器定期执行爬虫,本网站提供API,post到我网站服务器数据库上的。
4、网站评论系统
自己写了网站评论系统,采用了前后端分离的方法。
本网站用到的技术:
- 系统管理及部署:Nginx + supervisor + gunicorn + fabric (已经接近完成docker部署的调试,近期会用docker重新部署);
- 后端: Django + celery + MySQL + Memcached + Redis;
- 前端:Bootstrap + Javascript + jquery + Vue + Datatables + Highcharts等。
1、文章
文章支持按分类浏览,标签浏览两种方式,同样,支持关键词搜索文章(主要检索题目,正文等)。
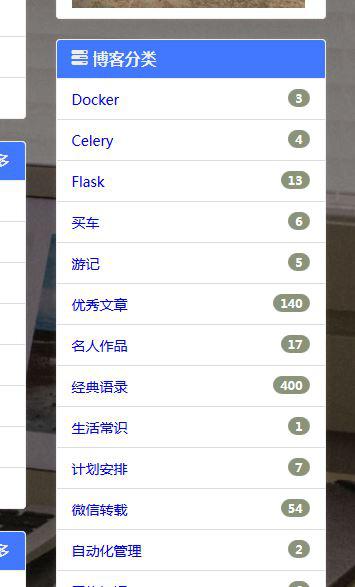
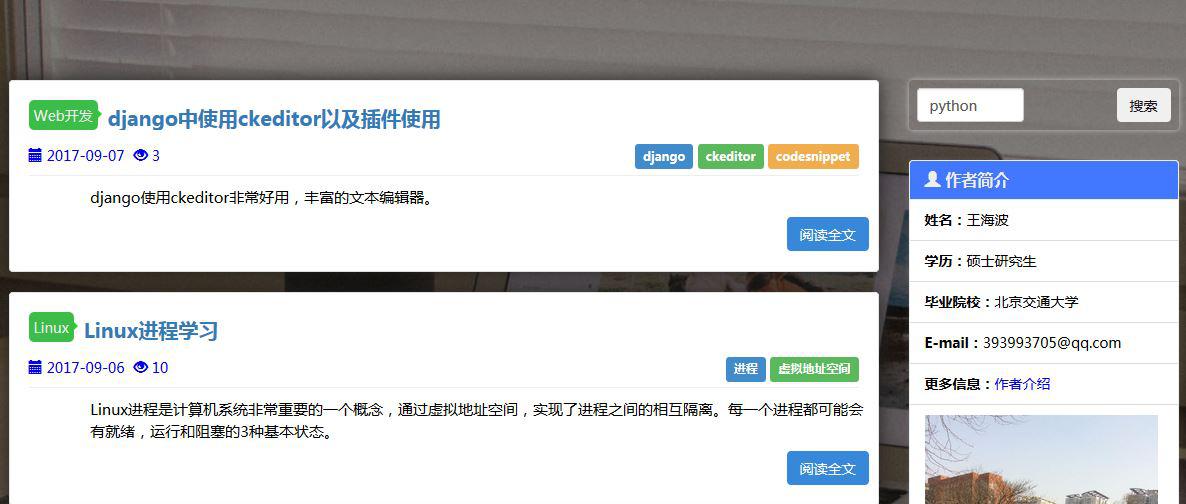
文章设置了访问权限,分普通用户可浏览、登录用户可浏览、管理员可浏览等等。
2、用户
- 采用ajax实现post数据进行登录;
- 采用邮箱验证流程;
- 忘记密码,进行重置;
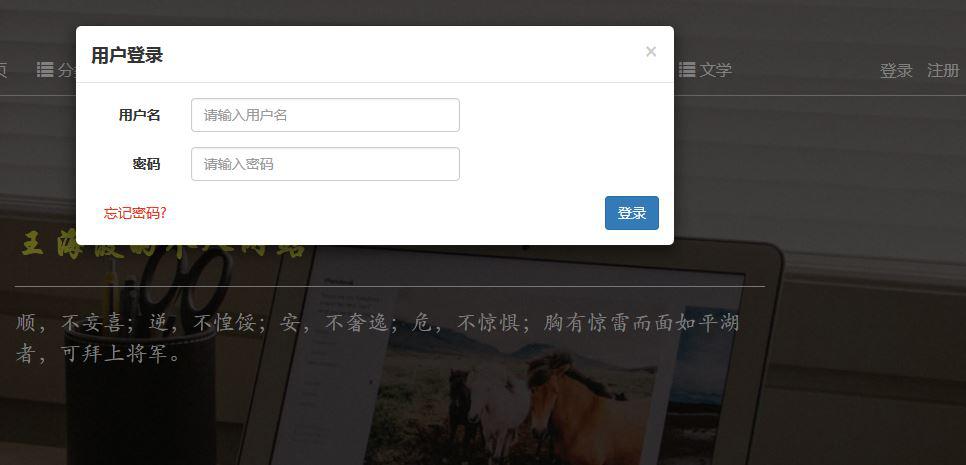
3、个人后台管理。
- 修改个人信息、修改密码;
- 后台管理文章(添加、修改、删除);
如下图:
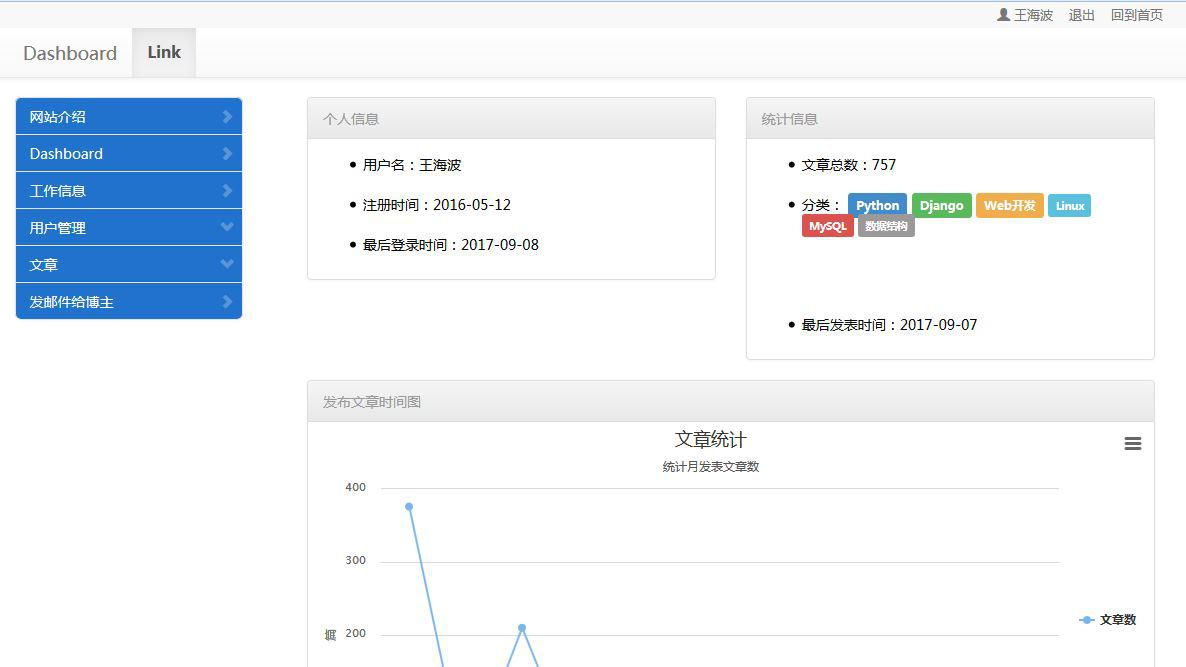
文章列表采用了DataTable插件,该插件的确特别好用,集成排序,搜索等功能。
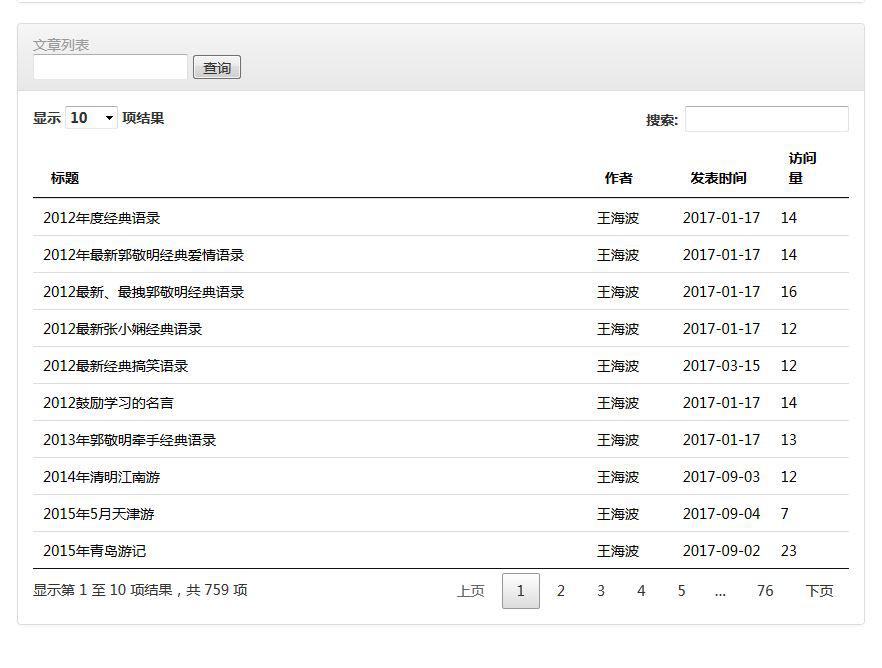
4、工作信息列表。
爬虫使用了Scrapy和requests写的,具体请见我博客上的scrapy介绍。
爬虫也放在了云服务器上,每天定时执行任务,执行完后,会通过API接口POST数据到网站数据库。
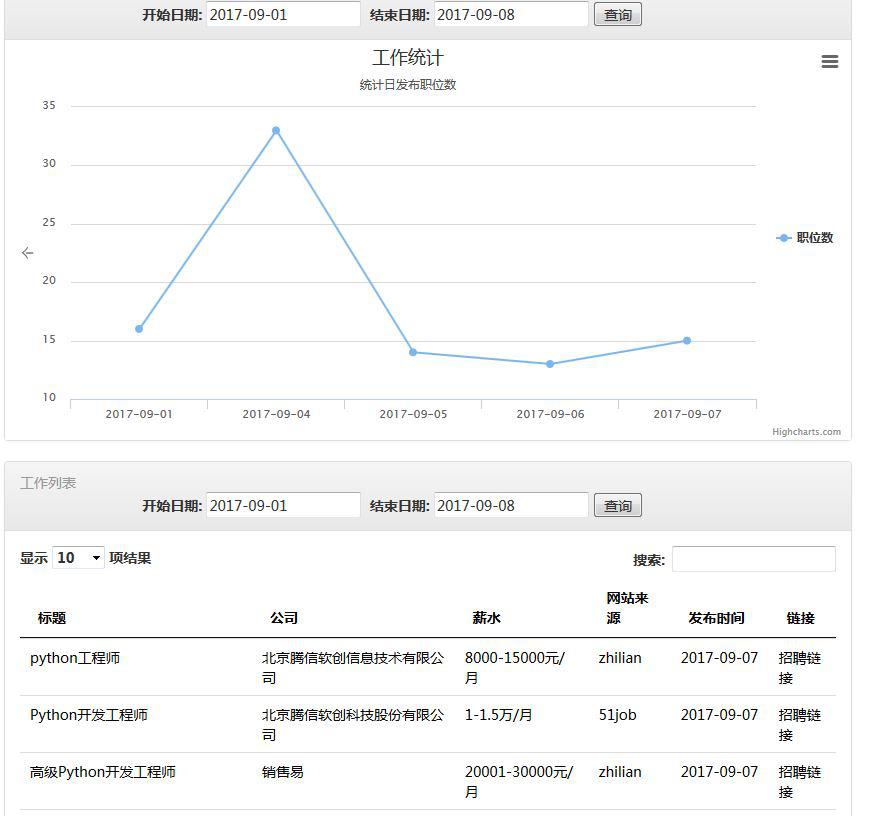
工作列表同样是利用DataTable插件。图表采用的Highcharts插件。
我现在的数据还没有进一步的处理和分析,我的计划是对数据进行详细地分析,比如一个公司在一段时间发了多少工作,一段时间内有多少家公司发布了类似的职位等等。
5、网站评论系统
本网站使用了Vue+JS等技术,实现了前后端的完全分离,这是一种比较好的尝试,哈哈。具体可看我的文章: 网站评论系统的设计 。
微信分享/微信扫码阅读

