
缓存的那些事儿
本文目录:
- 缓存的定义和分类
- 缓存的一致性
- 缓存的淘汰策略
- Mysql的缓存机制
- 总结
缓存的定义和分类
缓存的定义
高速缓存,英文名称Cache(发音 cash),是一种高速存储层。其最早是在上个世纪70年代的一篇电子期刊中诞生的概念,主要用来解决CPU处理速度和获取内存数据速度不匹配的问题。通过引入缓存层,可将数据提前加载到缓存中,CPU在获取数据时可首先从缓存中读取,从而减小数据的读取时间。
随着不断的发展,缓存已经不仅仅包括CPU缓存,后续还出现了磁盘缓存,以及应用层方面的缓存,比如客户端缓存、CDN缓存、Nginx缓存、DB缓存等等,甚至于Linux操作系统内部提供的TLB高速缓存。在现如今的互联网领域,缓存无处不在。通过使用缓存,可以在一定程度上协调不同硬件(网络)之间的处理速度差异的问题,增大数据获取的速度,提升系统的响应性能。尤其是数据库缓存,这个应该是我们开发系统时必不可少的。在DB层上方增加一层缓存层,一是可以提升数据读取的速度,二是可以避免大量数据请求落到DB上,减轻数据库的压力。
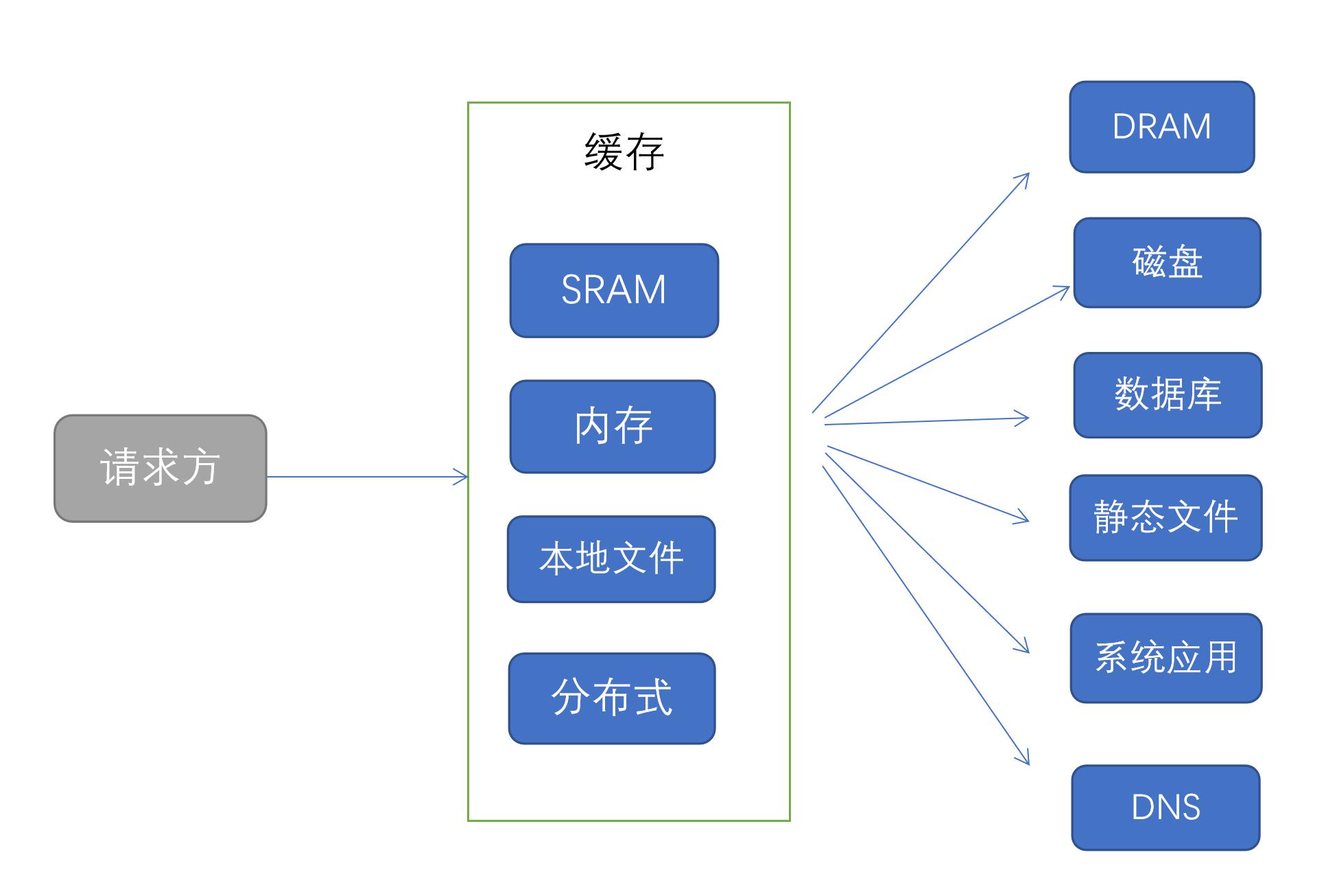
缓存分类
本文主要介绍如下几种缓存:
- CPU缓存
- 磁盘缓存
- CDN缓存
- Nginx缓存
- 客户端缓存
- 数据库缓存
1)CPU缓存 - CPU和主内存之间
应用程序在运行时,所需要的指令和数据会存储在内存中(只是在需要时被加载,否则还是在磁盘中,这里涉及到虚拟内存的概念,暂时不做过多阐述),CPU在执行时首先要从内存中取出,随后再经过译码,执行等过程。在整个过程中,最浪费时间的就是从内存中取指令的过程,通常需要几十个,甚至上百个时钟周期。因此,为了解决CPU处理速度和从内存中读写数据的速率不匹配的问题,在CPU和内存之间加入了高速缓存,以便能够加快CPU读写数据的速度。
在早期,只引入了L1和L2两层高速缓存,随后又引入了L3。其中L1层又分成指令缓存和数据缓存,L2和L3不区分;L1和L2是单核处理器独有的,L3是所有处理器共享的一层。下面示意图展示了一个8核(注意这里说的是物理,不是逻辑的)处理器的缓存结构:
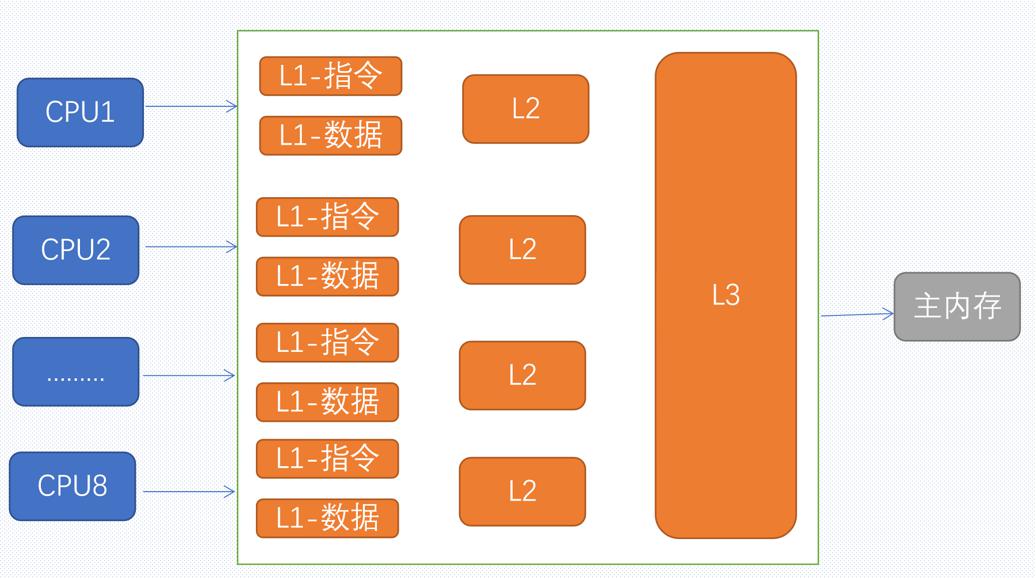
CPU Cache
引入缓存之后,CPU首先从L1中读取数据,如果有则直接返回;如果没有再到L2中读取;如果没有再到L3中读取;如果还没有则再到主内存中读取,随后将目标数据或指令写入到高速缓存中。其中离CPU越近的高速缓存其读取性能就越好,但是其容量也就越小,因此通过设置多级缓存来达到容量和速度的一个平衡。
通过引入高速缓存,可以大大提升读取速度。而之所以高速缓存会提升读取性能,主要得益于所采用的存储技术,比如主存通常使用的DRAM,缓存通常使用SRAM,两种是不同的随机存储技术,这里不做过多阐述。此外,cache利用了程序的局部性原理,可以提前加载数据到内存(预读),局部性包括时间局部性和空间局部性。时间局部性是指同一个数据被访问之后很有可能再次被访问;空间局部性是指被访问的数据附近的位置也有可能被访问。
上面提到了数据会从主存中加载到缓存,那是如何加载的,是一次性加载到内存中吗?还是一个字节一个字节读取?
实际上,数据是按照一个基本单元读取的,大小通常为64字节,叫做缓存行(Cache Line),每次可能会更新多个缓存行。每层Cache也是由多个CacheLine组成。假如现在有一个long型数组 long[] data,长度为50。由于long型为8字节,那么data[0]-data[7]会在同一个缓存行中加载,每个cache line包括tag,数据块和flag三个部分。如果在读取时可以直接从高速缓存中读取,可以大大提高性能。我们在平时的代码编写的时候也应该充分利用cache line。不同的代码可能带来的性能是不一样的。这里举个例子,现在有个需求是计算二维数组的总和。下面是两段不同的执行代码:
代码1:
public long calSum(long[][] longArray){
long sum = 0;
for (int i=0;i++<longArray.length;){
//按照行读取
for (int j=0;j++<longArray[i].length;){
sum += longArray[i][j];
}
}
return sum;
}代码二:
public long calSum(long[][] longArray){
long sum = 0;
long columLegth = longArray[0].length;
for (int j=0;j++<columLegth;){
//按照列读取
for (int i=0;i++<longArray.length;){
sum += longArray[i][j];
}
}
return sum;
}代码1执行速度要快于代码2.原因就在于缓存是按照行存储的,代码1是按照行遍历,因此更有可能命中缓存;代码2是按照列遍历的,违背了空间局部性的原理。
这里还要提到一个特殊的高速缓存,即TLB,快表。我们都知道现在系统都会为进程分配虚拟地址空间,既然是虚拟的,那就需要将虚拟地址映射到物理地址上,映射的工具就是MMU,内存地址是段页式管理的,所以再查找物理地址时,需要经过多级页表的查询(这个在我之前写的Linux操作系统管理一文中有介绍),而这本身是一个比较耗时的操作,因为页表是存储在主从中的,因此每次都需要经过先获取到物理地址,再法访问数据的过程。因此,CPU会将对应映射关系存储到主存中。
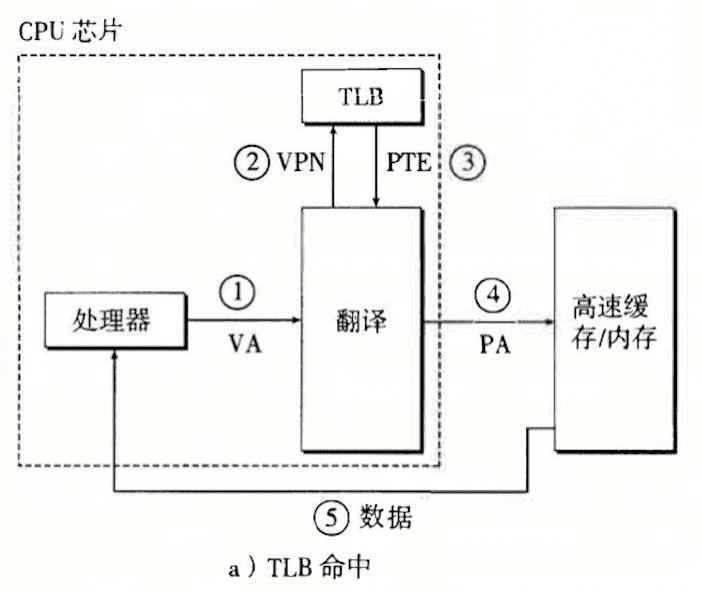
学JAVA的同学注意一下,不要和JVM中的TLAB搞混哈,虽然差一个字母,但差距是大大的(可能我有些多此一举了,应该不会有人搞混吧,哈哈)。这里就顺便介绍一下这个TLAB。
由于对象的实例化要经过对象创建、内存分配、指针应用等过程。所以在多线程下会造成不安全。想解决该问题,我们可以通过同步锁来实现,可能大家都通过著名的DCL;此外,JVM引入了一个TLAB(Thread-Local Allocation Buffers)的概念,他为每个线程在堆上都申请一块内存,不同线程之间是相互独立的,在对象分配内存时尽量在TLAB上分配,不足时再到普通的堆上分配。TLAB比较好的介绍: https://www.cnblogs.com/zhxdick/p/14371562.html
伪共享
上面提到了加载缓存数据是按照CacheLine加载的,如果多个线程访问的数据在同一个缓存行中,且多个线程都试着修改数据,当有个线程成功修改了缓存行中的数据,那么就会将CacheLine置为无效(这个在后面一致性的章节会提到),这就导致其他线程还要从主存中加载数据,从而影响性能,这种现象就叫伪共享。
伪共享可以说是并发编程中的一大隐形bug(叫做隐形杀手可能更合适,因为这不是谁的bug,只是程序可能没有充分利用好计算机的缓存机制)。对于这种现象,其实是可以避免的。比如对于不足64字节的,可以进行字节填充,如long型变量,是8字节,可以在后面补充上7个long型,组成64字节。这在早期的java中也是唯一的解决伪共享的方式,后期引入了Contended注解,该注解可以用在类或者字段上,被该注解装饰的会自动完成字节填充。
2)磁盘缓存 - 磁盘和主内存之间
上面讲到的是主存的缓存,而主存本身也可以作为一种缓存,即磁盘缓存。如果你在实际应用中使用过消息队列如kafka,Rocketmq,经常会听到PageCache这个概念,这并不是消息队列本身的实现,而是Linux操作系统提供的一种磁盘缓存的功能。
磁盘缓存
磁盘IO相对于CPU的执行速度来说,是非常耗时的操作,如果你使用的还是机械硬盘,那对于CPU来讲,磁盘IO的速度慢如老牛。因此为了减少磁盘IO的次数,提高数据读写的速度,在操作系统级别增加了一层磁盘缓存,磁盘文件数据会被加载到内存区域。在读时可直接读取磁盘缓存中的数据;写入时也指写入磁盘缓存中,随后经过某个策略(Write-back,Write-through,一个异步,一个同步)写入到磁盘中。
之前我在Linux零拷贝技术浅谈 中介绍过PageCache对性能的提升,这里不再赘述。
Linux可以使用free查看内存情况:
free -m
total used free shared buffers cached
Mem: 8192 1710 6481 0 0 601
-/+ buffers/cache: 1208 6983上面有个Buffer和Cache,表示的是Buffer Cache和PageCache,网上一大堆讨论这两者区别的,其实在Linux2.4以后,两者是放到一起的,下面的”-/+ buffers/cache“就说明了这一点。如果一定要区别,则是PageCache是逻辑概念,表示页缓存,缓存是按照页存储的,每页大小默认是4KB;BufferCache是对应的是块设备,如果我们在回写时,PageCache是要经过BufferCache回写到磁盘中的,下面的图是参考资料中的一篇文章中的,我认为比较清晰介绍了两者的区别和联系。
上面讲述了磁盘缓存在性能提升所带来的效果,但看到这里,是否会想到一个问题?如果数据是想写入PageCache,并标记dirty,那回写之前如果机器down了,数据不会丢吗?答案是会的,如果在回写到磁盘之前断电了,写入的数据是存在丢失的可能的。可以通过更改回写频率来尽量去减少这种事情发生的可能性,或者直接就同步刷盘,不过会影响性能。可以通过下面命令查询当前的回写时机:
sysctl -a|grep dirty
vm.dirty_expire_centisecs = 3000 #超过多长时间,触发刷盘
vm.dirty_ratio = 20 #脏页比例,如果脏页达到可用内存的一定比例,会触发同步写
vm.dirty_writeback_centisecs = 500 #定时多久刷一次盘
应用缓存 - 磁盘和网络之间,网络和网络之间
3)CDN缓存
CDN,全称Content Delivery Network,内容分发网络。主要用来分布存储静态文件,使得用户可以访问最近的节点数据,从而提高用户的响应时间。当我们输入一个地址进行访问时,中间要经历很多的过程,首先要通过DNS解析,随后找到目标Server,Sever处理后将响应数据返回给客户端。而整个过程会受到带宽、分布距离的影响。通过设置CDN,不同地区的用户可以直接访问距离最近的节点数据,这样一是提升了数据的获取速度,也减轻了服务器的压力,服务器可以只处理动态数据。通过CDN的使用可以实现文件、下载、音频视频等静态内容的加速。
现在CDN技术比较成熟,国内也有很多CDN服务提供商,阿里,腾讯都有,不需要应用开发者自己部署CDN节点,省去大量成本。只需我们在域名解析中增加一条CNAME记录,指向CDN服务上提供的CNAME域名即可。
4)Nginx缓存
作为一款反向代理软件,Nginx的应用流行度已经远超Apache,因为其性能优越,小巧,安装配置简单。其提供的功能比较丰富,其中缓存功能就是其中之一。Nginx可以开启缓存功能,从而缓存静态文件到本地,避免请求打到后端的服务器。本地缓存可以使用内存和磁盘存储。
其开启缓存功能比较简单,下面是一个例子:
proxy_cache_path用来设置缓存的路径和配置,
proxy_cache用来启用缓存。
proxy_cache_path /path/to/cache levels= 1 : 2 keys_zone=my_cache:10m max_size=10g inactive=60m
server {
location / {
proxy_cache my_cache;
proxy_pass my_upstream;
}不过如果使用Nginx缓存,最好还是使用商业付费版,其缓存清除的功能更加强大。
5)客户端缓存
这里主要介绍浏览器缓存。浏览器在同一个会话过程中会检查一次并确定缓存数据是否足够新。在浏览过程中,比如前进或后退,访问到同一个图片,这些图片可以从浏览器缓存中调出而即时显现。
感兴趣的可以看我之前写的一篇介绍HTTP缓存的文章:千与千寻-HTTP缓存
4)数据库缓存
为了减轻数据库的压力,提高数据读写读取,在实际系统开发中我们都会为数据库增加一级或多级缓存,主要包括进程内缓存、本地文件缓存以及分布式缓存。实际比较常用的就是进程内缓存和分布式缓存。
数据库缓存分类
进程内缓存
应用程序会将缓存数据存储在内存中,但应用程序如果下线,缓存数据将会消失。学习Java的应该都知道进程内缓存主要包括堆内缓存和直接内存缓存。
Java开发可以直接使用WeakHashMap,ConcurrentHashMap缓存数据,但如果希望实现自动的缓存回收、过期清除等更丰富的功能,还要使用第三方库,比如Guava,Encache等。其中Guava比较简洁,但只能实现堆缓存,Guava主要借鉴了ConcurrentHashMap的思想。堆缓存最大的问题就是容易引起GC,如果缓存数据过多,频繁的GC会影响整个应用系统;
考虑到堆缓存的问题,还可以使用直接内存,直接内存处于堆外,主要和主机内存有关,不会触发JVM的GC。要想使用直接内存缓存可以使用Encache,Encache支持多种类型的缓存,内部的实现机制是BigMemory特性,感兴趣的可以看下官网。
进程内缓存是直接、最简单的缓存方式,但使用需谨慎,因为进程内缓存主要使用的是主机的内存,如果缓存数据过多且未及时清理,可能会引起OOM。
分布式缓存
分布式缓存主要借助中间件实现,中间件会以独立的方式部署,和应用处于不同的网络节点,从而实现了和应用系统完全隔离,避免了进程内缓存的弊端。目前比较常用的是Redis、Memcached等。更流行的还是Redis,因为其能够提供更丰富的数据结构以及支持持久化。
多级缓存
在实际应用中,我们通常会件进程内缓存和分布式缓存结合着来用,进程内缓存可以存储一些热点数据,从而能够进一步提升响应速度。
缓存模式
目前比较常用数据库缓存模式主要包括:
- Cache-Aside
- Cache-SOR
Cache-Aside
Cache-Aside也叫旁路缓存,也是比较常见的缓存策略,基本上很多使用缓存的地方都会采用这种模式。其基本思想就是,首先从缓存中获取数据,如果没有则再读取数据库,并件从数据库中读取的速度写入到缓存中。
下面代码是一个简单的示例:
public static final Cache<String, Object> wallectClientCache = CacheBuilder
.newBuilder()
.expireAfterWrite(60 * 60 * 3, TimeUnit.SECONDS)
.maximumSize(6000).build();
public List<Wallet> getWalletByClientId(String clientId) throws BizError {
//从缓存中读取
Object ret = wallectClientCache.getIfPresent(clientId);
//没有则从DB中读取
if (Objects.isNull(ret)){
List<Wallet> walletList = getWalletFromDb(clientId);
ret = GsonUtils.toJson(walletList);
//写入缓存
wallectClientCache.put(clientId,ret);
}
return GsonUtils.parsonJsonList(ret.toString(),Wallet.class);Cache-SOR
Cache-SOR和Cache-Aside区别就是业务代码不需要操作后方的数据库,而读取写入工作完全由缓存层去做,可以把缓存层当作一个代理,业务方不直接和数据库交互。
当业务方读取Cache数据时,如果缓存层没有,缓存层会自动触发读取数据库数据流程,并将结果回写到缓存中;
当业务方写入数据时,只需要将数据写入Cache,Cache负责将数据写入到数据库中。
可以看到,Cache-SOR简化了业务方的交互流程,使用更加方便。Encache就提供了类似的功能,但还是要自实现Loader。
数据库缓存的常见问题
热点数据
根据二八定律,经常被访问的数据可能很少,尤其是在电商中,有些爆品会有更高的访问量,比如茅台抢购,有品的茅台抢购接口峰值QPS达到过8万+,全站达到22万+。对于热点数据不做特殊处理的话,会导致所有流量都打到相同的节点上,导致某个节点压力骤增,延迟增大。
还是拿茅台举例,对于商品属性等数据可以短暂的保存在本地缓存中,这样服务集群中的每个集群都会缓存热点商品属性数据,请求不会请求到Redis以及数据库中;此外对于库存数据,可以根据某种规则,将总库存分散到不同的分片上,从而分散库存扣减请求压力。如总库存是10万瓶,可以根据用户群分成多个组,不同的用户群的用户会将请求分散到对应的分片节点。key可以是 sku:actId:usergroup1;sku:actId:usergroup2。。。。。
数据空间消耗
缓存由于容量有限,要尽量用较小的空间存储更多的数据。比如我们想统计每天在线用户数,如果一个网站的用户数较多,采用普通的Redis存储可能计算比较慢。可要是使用位图,可以较快地完成技术统计。此外,它非常节省空间。
比如你有1亿的数据,那么它需要的空间是:
100 000 000 / 8 / 1024 /1024 = 11.92M。
1亿数据只需要11.92M的空间,Amazing!
位图的主要命令列表:
- SETBIT
- GETBIT 获取某个偏移量的值
- BITCOUNT 返回是1的数量
- BITPOS
- BITOP
- BITFIELD
位图的主要应用场景包括统计用户是否在线,用户每天的签到情况,每日的用户数,活跃数等等。
相比于bitmap,还有占用空间更小的数据结构,比如roaringbitmap,该数据结构是在2016年被提出来的,其内部不仅含有bitmap,还有array。感兴趣的可以看下面的参考资料。
缓存雪崩
缓存雪崩是指在同一时间,大量缓存全部失效,导致请求全部打到数据库上。这个比较好解决,只要将不同的缓存key的时间设置的随机一些,不同的Key会有不同的过期时间,避免缓存在同一时间失效。
缓存击穿
缓存击穿是指某个热点key缓存失效了,且有大量请求过来,导致所有的请求全部落到数据库上。其实这个和缓存雪崩引起的结果是一致的,只不过原因不同,这个强调的是单个热点key失效引起的大量请求,缓存雪崩强调的是大面积key的缓存失效。
缓存击穿的问题也比较好解决,对于热点数据,我们完全可以设置永不过期,或者有自动续期机制。此外,也可以考虑在失效时,加入一把分布式互斥锁,在写入缓存时,其他读请求阻塞住,当然这种做法比较影响系统性能。
缓存穿透
缓存穿透指的是访问了一个实际不存在的数据,每次都要查询数据库。其描述的是打到数据库的很多请求都是无效的。比如在查询一个用户信息时,可能这个用户根本没在系统注册过,但还是请求了数据库。如果无效的请求比较多的时候,也会一定程度上增大数据库的压力。
解决缓存穿透的方法比较常见的有了两种:
1、将不存在的数据同样存储在缓存中,但缓存的是空值,即一个无效值。当从缓存中发现该数据是空值,就证明不存在;
2、使用布隆过滤器(可以参考上面的位图,可以经过两次到三次的hash散列避免冲突),将所有存在的key存储到布隆过滤器中,如果在查询时,某个数据在布隆过滤器不存在,则该数据就一定不存在。当然布隆过滤器会存在误判,即计算出存在,可能是因为hash冲突导致其他数据计算出的散列值。但如果hash散列计算函数不是特别的差,冲突概率会比较小。对于布隆过滤器的详细介绍,可以看下面的参考资料。
上面这两种方案,虽然都可以在一定程度上避免缓存穿透的问题,但最大的问题是都不能保证强一致性,除非自实现分布式锁,但性能上还是有影响的。所以只要能实现最终一致性就可。
缓存的一致性如何保证?
引入高速缓存之后,带来性能提升的同时,最大的问题就是会出现数据不一致的问题。无论是CPU cache还是我们在实际应用中设计的各种缓存。本文主要介绍CPU缓存的一致性以及数据库缓存的一致性问题。
CPU缓存一致性
上面见到,CPU cache包括L1,L2和L3,其中L1和L2是每个处理器独有的,也就是说同一份数据会在每个处理器的高速缓存中存储一份缓存数据。在多任务场景下,可能会出现缓存不一致的问题。那是如何解决的呢?
CPU缓存的一致性的解决主要是依靠MESI协议。MESI由四个状态组成,并制定了相应的状态流转以及事件的规则。四种状态分别为:
M,modify,表示修改状态;
E,Exclusion,表示独占状态;
S,Shared,表示共享状态;
I,Invalid,表示无效状态;
下面来演示一下内存读取,更新的过程。图片来源于一个MESI演示网站
1、现在有三个处理器。
2、现在CPU1先读取地址a0数据,此时CPU1的缓存状态变成E。
3、 此时CPU2也读取a0,则CPU1和CPU2的缓存状态都变为S。
4、CPU2修改地址a0数据,此时,CPU2的缓存变为E状态,CPU1的缓存状态变为I,无效。CPU2更改后的数据回写到内存中。
5、CPU1再读取a0,发现缓存数据是无效,会直接从内存中读取。
以上过程演示了如果一个处理器修改了本地缓存中的数据,是如何确保其他处理器缓存中数据的的一致性过程。如果所有的指令都是严格按照上述约定执行,那么缓存一致性就可以完美解决了。但是现实却不是这样的,因为MESI协议依赖总线控制实现,串行处理,效率非常低,这对于如今的高并发场景来说是不可忍受的。因此,现如今的计算机是通过存储缓存(Store Buffer)以及失效队列来实现MESI协议,这里不过多解释这两点,只要知道通过存储缓存和失效队列,将依赖总线控制的MESI协议所实现的强一致性变成了最终一致性。这大大提高了计算机的处理性能。
可最终一致性能满足我们实际的业务需求吗?对于高并发的场景来说是绝对不行的。那该如何实现呢?针对该问题,CPU又引入了一个概念,叫内存屏障,其包括读屏障和写屏障。屏障是以指令的形式存在的,从字面上去理解它,屏障即在你做一件事前设置一个障碍。就像马路上的路障,只有路修完了,你才能继续走。读屏障简单理解就是在执行读屏障指令时,必须要等到其他处理器的缓存行都变为失效状态才可以,这时保证数据内存数据可见性的根本。另外一个是写屏障,其要达到的目的是只有等到写成功之后才可以执行后续的写操作。
总结一下CPU缓存一致性,首先通过总线控制的MESI协议来实现缓存一致性,但因为其本身效率较低,又引入了存储缓存,但由于其实现的是最终一致性,不能满足对一致性要求较高的场景,因此后续又引入了内存屏障。
说完CPU缓存一致性,不得不提另外一件实现内存可见性的知识点。
如果是Java开发者的话,一定对volatile不陌生。volatile一共有两个内存语义,一是保证内存可见性,二是禁止重排序。
JAVA是运行在虚拟机上的,JAVA内存模型也提供了工作内存和主内存,其中主内存对应的就是计算机上的物理内存,工作内存对应的是计算机的寄存器或者高速缓存。那JAVA是如何通过volatile实现内存的可见性的呢?
对于具有volatile修饰的变量,赋值后会多执行一个lock操作,这个指令就相当于内存屏障,它可以保证在写入volatile变量时,JMM将修改后的值刷新会主内存中;其他CPU在读取volatile变量时,此时本地CPU缓存的状态是无效的,因此会直接从主内存中读取最新的数据,从而保证了内存可见性。
数据库缓存一致性
上面讲到了计算机的缓存一致性的实现,而在我们实际应用中比如数据库缓存,是需要我们开发者自己去保证的缓存一致性的。比如Redis保存了商品属性的缓存,如果数据库进行了update,Redis中的数据该如何保证数据的一致性?
提到一致性,首先要确认是强一致性,弱一致性还是最终一致性?对于一致性的不同需求会影响系统的设计。还是拿商品属性 缓存举例。缓存保存着商品名称缓存。现在运营要修改商品名称,与此同时有大量的并发读请求。那该如何实现三种不同的一致性?
强一致性
强一致性是要求最高的,即数据库如果更新了数据,那么所有客户端读到的数据一定是最新的。网上有很多关于缓存一致性的解决方案,但都不是强一致性的解决方案。比如现在比较流行的包括”先更新数据,再删除缓存“、”先删除缓存,再更新数据库“、”先更新数据库,再更新缓存“、”先删除缓存,再更新数据库,再删除缓存“。他们都只是在一定程度上减少缓存不一致的持续时间,而不是真正地实现了强一致性。
如果想实现强一致性,首先想到的就是分布式锁,即通过加互斥锁实现强一致性。当有写入请求时,其他所有的读写请求都要阻塞,可以自旋一直等到写锁释放。这和JAVA里的读写锁的思想比较类似。
虽然通过分布式锁可以达到强一致性的目的,但在操作写入的过程中,其他请求都会被阻塞,这就是导致性能比较差。如果写入操作比较少的情况下,还可以容忍;如果写入操作比较频繁,那我们的设计就是灾难,同时也失去了缓存本身存在的意义。
实际业务中,既然引入了缓存,就证明了我们可以容忍缓存出现短暂的不一致的情况。不仅仅是缓存,只要在分布式系统中,BASE最终一致性和弱一致性是实际应用的多数选择,而强一致性只是分布式系统CAP的理论概念。就像我们实现的分布式事务,现在大多数使用的都是TCC这种做法,而不需要XA这种两阶段提交的强一致性做法。
最终一致性
最终一致性指的是只要最终能保证缓存和数据库的一致性,而达到最终的一致性是可以存在延迟的。
实现最终一致性的手段比较多,这里说两种可参考方案。
1、通过订阅数据库的binlog,实现数据库的增量同步。
通过监听数据库的binlog,来完成缓存的数据更新。阿里开发的cannal就提供了一套成熟的同步方案。cannal把自己伪装成mysql的slave,数据库出现数据更新后,会将变化发送给cannal,cannal再负责发送到下游,如Redis,MQ,ES等等。
2、RocketMQ异步更新缓存
在数据库完成数据更新后,可以将修改数据发送到MQ,随后由独立的任务异步将数据更新到缓存。用MQ的好处在于,消费者只有成功消费了才会返回ACK,否则MQ可以不断重试(当然,重试次数要取决于消费的模式,是并发还是orderly)。而对于前面提到的先更新数据库,直接删除或者更新缓存,是存在操作缓存失败的场景,可能不能实现最终一致性。
这里顺便还要提一下Redis6的一个新特性,client-side-caching。这个主要适用在多级缓存的场景下,Redis缓存有更新时,会及时通知到本地Server,告诉他缓存失效了,应用程序可以自行清除本地的缓存,从而实现了最终一致性。其基本流程是当客户端get数据时,Redis会缓存这个客户端和key的map,当key发生变化时,会自动通知该客户端。Redis6提出的client-side-caching解决了Redis曾经的pub/sub的比较耗资源的做法。感兴趣的可以看官网介绍
弱一致性
弱一致性表示在数据库更新之后,不保证缓存中的数据现在或者未来的时间内是最新的。其实最终一致性也属于弱一致性的范畴。
对于弱一致性,系统上的实现比较简单了。最简单的是为缓存加失效时间即可(不同的key要加随机的时间,避免缓存雪崩),其次使用上面提到的几种数据库和缓存的几种操策略中的任何一个即可。
”先更新数据,再删除缓存“
”先删除缓存,再更新数据库“
”先更新数据库,再更新缓存“
”先删除缓存,再更新数据库,再删除缓存“
缓存的淘汰策略?
缓存的淘汰对于一个完整的缓存系统来说是至关重要的。因为缓存的容量是有限的,且我们也希望缓存中尽可能存储较少的数据。如操作系统,应用程序(Mysql,Redis),JAVA,凡是使用到有限内存的地方都会使用一定的内存淘汰策略。
缓存的淘汰主要包括两个方面,一是淘汰的数据范围,即是在所有缓存数据中进行淘汰,还是只是对已经过期的数据进行淘汰;二是淘汰的算法,可能大家经常会听到LRU,LFU,FIFO等。这几种算法是目前缓存淘汰中比较重要的几个算法。比如在CPU高速缓存中、内存物理页置换、磁盘缓存等场景也都使用了以上几种算法。
如果你使用过Redis,会在其配置文件看到如下几个配置:
# volatile-lru -> remove the key with an expire set using an LRU algorithm
# allkeys-lru -> remove any key according to the LRU algorithm
# volatile-random -> remove a random key with an expire set
# allkeys-random -> remove a random key, any key
# volatile-ttl -> remove the key with the nearest expire time (minor TTL)
上面的几个配置分别说明了该淘汰哪些数据以及所采用的不同的淘汰算法。
还是要说一句,不要把Redis的内存淘汰策略和Redis的过期删除机制搞混哈,两者不是一回事。
FIFO:
最简单的算法,根据先入先出来决定淘汰,但这种算法并不能反映真实的业务场景,它不会考虑哪些数据是热点,哪些数据比较冷门。通常通过链表和队列即可实现FIFO。
LRU:Least Recently Used
最近最少使用,该算法会淘汰最近没有被访问到的数据。Java中的LinkedHashMap就实现了LRU,即每次get数据后,将数据放在链表尾部,删除数据时会在链表头部删除。
下面是借助Java的LinkedHashMap实现的LRU:
class LRUCache {
private int capacity;
private LinkedHashMap<Integer,Integer> map;
public LRUCache(int capacity) {
this.capacity = capacity;
this.map = new MyLinkedHashMap(capacity,0.75f,true);
}
public int get(int key) {
Integer value = this.map.get(key);
if(null == value) return -1;
return value;
}
public void put(int key, int value) {
this.map.put(key,value);
}
static class MyLinkedHashMap<K,V> extends LinkedHashMap<K,V> {
private int capacity;
public MyLinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity,loadFactor, accessOrder);
this.capacity = initialCapacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
#当数量超过初始化容量,就会触发删除表头操作
return this.size() > this.capacity;
}
}
}LRU是使用比较多的算法,不过其存在的最大问题是新数据容易把较热点的数据挤掉,即缓存污染。比如某一段时间访问的都是新数据或冷门数据,这种数据在LRU算法中也不会被删除。
对于这种问题,Linux,Mysql是,Redis都有不同的实现来避免。
Linux
linux回收的数据范围是文件页和匿名页,回收的算法也是改进的LRU算法。
针对这两种不同的页,分别维护了两个链表,一个是活跃链表(active_lists),一个是不活跃链表(inactive_list),这是一种改进的LRU算法。如果访问数据不在链表中,则直接加入到不活跃链表中,如果数据第二次被访问到,会加入到活跃链表。在进行内存淘汰时,直接淘汰不活跃链表的数据即可。
通过两张链表可以有效避免了预读失效和缓存污染的问题。
预读失效:我们都知道,程序具备局部性原理,在读取存储器数据时,是以页或者块为单位进行读取的,一次会读取连续空间的数据,即时有些数据本次不会用到,Linux默认的页是4KB ,当然页可以配置大页( Huge pages,2MB或者1G),Mysql页(Innodb)的大小是16KB。但在极端情况下,可能会出现一个问题,就是预读的数据永远都不会被访问到。如果是利用传统的LRU,访问就加到链表头部的话,可能会导致很多热点数据被挤到链表尾部,导致热点数据可能会被淘汰。当然,还要提到一点,由于局部性原理,预读失效的概率并不大。
Linux通过两个队列,首先将数据预读数据放到不活跃链表,尽可能缩短了不活跃的预读数据缓存时间,首先被淘汰。
缓存污染:缓存污染指的是大量数据占据了链表头部,导致热点数据被淘汰。其实也是预读引起的。对于上面的链表,预读出来的数据是放到不活跃链表,如果被访问到就直接放到活跃链表中,就仍然存在缓存污染的危险。针对这个问题,linux的做法是只有第二次被访问到,才会被加入到活跃链表中,即提高了加入活跃链表中的门槛。在一定程度上,有效地降低了缓存污染的问题。
Redis
通过老新代两个链表实现的,也可以采用LFU算法。Redis4.0以后就新引入了LFU算法。
LFU:Least Frequency Used
在一段时间内,每访问一次,数据的访问次数就加1,LFU会淘汰访问次数较少的数据。相比于LRU,避免了LRU可能会导致新节点覆盖热点数据的问题,对热点数据较友好。
可以基于双哈希表来实现,一个hash表存储实际的k-v一个存储k和访问频次(用python实现的)。
class HbnnLRU:
def __init__(self, size):
#最大容量
self.max_size = size
#一个存储实际的值,一个存储访问次数
self.lfu = self.data = {}
def get(self, key):
if key in self.data:
self.lfu[key] += 1
return self.data[key]
return -1
def set(self, key, value):
if self.should_del_oldest_key():
del_key = min(self.lru, key=lambda item_key: self.lru[item_key])
self.data.pop(del_key)
self.lfu.pop(del_key)
self.data[key] = value
self.lru[key] = 0
def should_del_oldest_key(self):
return len(self.data) >= self.max_sizeMysql缓存机制介绍
上面提到我们在开发中,会在数据库前加一层缓存用以提高读写性能,实际上,Mysql内部也有缓存,InnoDB存储引擎内部是通过Buffer Pool实现的。
Mysql是以页为单位进行缓存的,BufferPool是由多个BufferPool 实例组成的,每个实例是由多个chunk组成,单个chunk是以一段连续的内存空间划分。示意图:
每个buffer pool中都有三个链表:空闲列表,脏页链表,LRU链表。
空闲链表存储的所有空闲页,这个就像JVM在内存分配时使用的空闲内存列表一样。
脏页链表存储的是已经被修改或删除,但还未被刷到磁盘上的数据。
LRU链表主要用来进行内存淘汰。这个后面会具体说。
Mysql读操作过程:
1、首先从缓存中获取对应数据,如果命中,直接取出,返回。如果没有命中,往下走;
2、从磁盘中加载数据到内存;如果Free list空闲列表有足够数据页则使用,如果没有就需要走第三步;
3、LRU执行缓存数据淘汰。
加速写:
首先会写到缓冲区的redo buffer中,不直接同步刷盘。刷磁盘同步操作由其他后台线程处理。
Mysql的内存淘汰
从名称LRU list就可以看出,它不是简单的LRU策略。因为其要保证热点数据不会被淘汰(缓冲区污染),此外要解决预读失效的问题。它将整个LRU 链表分成了新生代和老年代。
新生代和老年代首尾相连,老年代是可能被淘汰的数据,数据是排序的,链表尾部先被淘汰。新生代和老年代的比例可以人为配置。

当有新数据进入时,首先会插入到老年代的头部,且淘汰尾部。当是已在缓存中的数据,直接将页放到新生代的头部。
Mysql解决缓冲区污染的方法是当新生代中的数据被访问时,不会立即将其加入到新生代中,它设置了一个停留时间窗口T,只有被访问且在停留时间大于T的才会被访问。
预读失效
Mysql预读就是预先读取一些可能将来被访问的数据到缓存,其利用的是我们经常说的局部性原理,即时间局部性和空间局部性。但可能也有预读失败的,即提前缓存的数据永远不会访问到。Mysql用新生代和老生代,使得刚进来的数据不会直接插入到链表头部,而是只插入到老生代的头部。
其实Mysql的思想和Linux内存回收的思想还是比较类似的,不同之处首先是其使用一个链表,只不过是分出了young区和old区。此外,old区域进入young区的门槛提高了,Linux是只有被访问到第二次就会加入到活跃链表;Mysql的做法是如果第二次被访问和第一次被访问的时间小于1秒,不会移动到young区;如果超过1秒,才会移动到young区。
总结
本文主要介绍了在互联网领域不同种类的缓存,包括CPU缓存、磁盘缓存以及应用缓存等,此外也分别阐述了不同的缓存的特点,以及缓存中应该注意的问题。
我们也可以开发一套缓存系统,从而满足定制化的需求 ,就像Mysql一样,避开PageCache,自实现了一套缓存机制。但设计缓存其实是一件很复杂的事,提升读写性能是重要的指标,但却不是唯一的指标。想要设计一个合格的缓存系统需要注重以下几点:
- 性能
- 占用空间
- 数据一致性
- 淘汰策略
- 预读机制
所以,对于我们实际开发者,操作系统级别缓存不需要我们过多关注,而应用级别的缓存最好也不要重复造轮子,而是使用成熟的中间件或者框架。
微信分享/微信扫码阅读

