
分布式锁
本文带着三个问题来说:
什么是分布式锁?
如何实现分布式锁?
分布式锁会存在哪些问题?如何去解决?
什么是分布式锁?
锁这个概念我们都已经很了解,它是一种在并发场景下保持同步的一种机制,比如JAVA中的内置锁,Lock接口实现类锁,自旋锁,互斥锁,悲观锁,乐观锁,CAS等等。那什么是分布式锁呢?
先看一段英文解释:
A distributed lock manager (DLM) runs in every machine in a cluster, with an identical copy of a cluster-wide lock database. In this way a DLM provides software applications which are distributed across a cluster on multiple machines with a means to synchronize their accesses to shared resources.
简单说,分布式锁的存在就是用来实现分布式系统中不同子系统的同步,控制不同节点对共享资源的同步访问,可以说成是分布式的互斥。

如何实现分布式锁?
分布式锁的种类
1、Mysql数据库锁
2、Redis分布式锁;
3、Zookeeper分布式锁;
1、Mysql数据库锁
是的,Mysql也可以说是提供了分布式锁,这是其天然的优势,通过悲观锁可以实现排他性。可以创建一个记录锁的表,并使用主键或者唯一键,根据独占锁来实现同步。比如下面的一张数据表(借用我崇拜的一个大佬双哥写的)

但是用数据库实现分布式锁性能较查,首先写只能写单点,其次排他锁占用时间较长,会导致线程池耗尽,系统崩溃,再有就是实现复杂的场景,锁超时,中断,可重入、公平锁等比较困难。
2、Redis分布式锁
1)Redis最简单的就是使用set key value ex seconds||px milloseconds nx
ex表示超时时间,nx表示只有不存在的时侯才可以创建成功。
其实在这之前,Redis还有一个是先执行 setnx(不存在时侯创建),然后再执行expire,设置超时时间。但是因为这不是一个原子操作,这意味着如果中间出现各种异常,都会出现错误。比如setnx执行完之后,redis服务挂了,或者网络挂了,总之没执行成功expire,那么这个锁就一直不会释放,假如某个线程执行时间非常长,一直不释放锁,那么整个系统可能会因此出现阻塞。
因为Redis后来又提供了上述的原子操作。可以用redis-cli,python(redis-py)试一下,或者Java。但说实话,python的操作要比Java的操作简单一些,所以如果练习建议用python。
redis-cli:
ip> set test:lock true ex 100 nx
上面就创建了一个锁,超时时间是100
用Java简单操作:
if(redisTemplate.opsForValue().setIfAbsent("test:lock",200,100,TimeUnit.SECONDS)){
log.info("redis testlock设置锁成功,value:200,超时时间为100秒");
}注意,上面在spring-data-redis 2.0版本以后才有,之前的得用execute去执行一下。
redisTemplate.execute(new RedisCallback<Boolean>() {
@Override
public Boolean doInRedis(RedisConnection connection) throws DataAccessException {
JedisCommands commands = (JedisCommands)connection.getNativeConnection();
String result = commands.set(key, value, "NX", "PX", unit.toMillis(timeout));
return "OK".equals(result);
}
});
上面展示了如何简单使用redis加锁。但现在考虑两个问题。
1、假如某个线程成功设置了这个锁,但是由于其业务逻辑执行太久,导致该锁超时被释放了;此时,另外一个线程抢到了这个锁,在这个线程执行的过程中,之前的线程突然执行完了,它最后的操作可能是要释放锁,那它就会把后来的线程锁给释放了,从而引发各种问题。这种情况该怎么解决呢?
其实很好解决,就是为锁的key设置不同的value,在线程中就是创建一个只属于该线程的随机数。这样在释放锁的时侯,如果该锁的value和自己一样,就释放,否则直接退出。简单逻辑是先用get方法取出该key的value,如果它和自己之前设置的value一致就执行del命令,删除。否则就直接退出。
2、上面的get匹配和删除也不是一个原子操作,同样存在上面说的问题。目前redis并没有提供这样的原子命令。但Redis可以使用lua脚本,使用lua可以轻松实现上面的原子操作。
下面的一个简单释放锁的例子:
@Component
public class RedisLock {
@Autowired
private ActivityRedisDao activityRedisDao;
@Autowired
private RedisTemplate redisTemplate;
public void addSimpleLock(){
Integer value = 200;
String key = "test:lock";
//加锁,并设置超时时间
if(redisTemplate.opsForValue().setIfAbsent(key,value,100,TimeUnit.SECONDS)){
log.info("redis testlock设置锁成功,value:200,超时时间为100秒");
}
try {
Thread.sleep(30000L);
}finally {
//释放锁
String luaScript = "local ret = redis.call('get',KEYS[1])\n" +
"if ret == ARGV[1] then \n"
+ "return redis.call('del',KEYS[1])\n"
+"else return 0\n"+
"end";
List<String> keys = new ArrayList<>();
keys.add("test:lock");
Object ret = activityRedisDao.runLuaScript(luaScript,keys,value);
}
}
}上面是Redis分布式锁的简单使用场景,如果更复杂的,可以使用Reddison,这也是Redis官网推件的客户端,其支持可重入、读写锁、信号量,底层基于Netty,性能强劲。更重要的是保证了锁的安全性。那怎么保证安全性呢?
上面的例子就是Redis最简单的一种加锁方式,在单例中完全没问题,但实际应用中,Redis不可能只是以单例部署,部署方式都会采用哨兵或者Redis-Cluster等集群模式。在集群模式下,上面的方法是存在极大的不安全性。
比如在哨兵集群中,某个时刻加了一把锁,但是正巧注节点挂掉了,而此时由于主从同步延迟,锁还没有来得及同步到从节点。从节点成为主节点,但它并没有这把锁,此时别的线程是完全可以再接着加锁的。
基于此,Redis发布了一种加锁算法:RedLock.
其实也是基于上面的基本思想。然后在整个集群中,通过同时加锁,达到目的。具体思想:
假设现在有N个master节点,这几个节点相互独立,不存在主从复制,其实就是目前比较稳定的Redis-Cluster。
获取锁:
1、首先获取当前时间戳,毫秒级;
2、客户端轮流地从所有实例中获取锁,直到成功地从超过一半(N/2+1)个实例中获取了锁为止;
3、此时这个锁的有效时间是最初始设置的有效时间减去获取锁的消耗时间。
4、假如客户端轮询完整个集群的实例之后,依然没有获得半数以上的锁,那么就要把所有之前已经获得的锁释放掉,整个流程也以失败告终。
5、如果获取了半数以上的锁,且最后的过期时间有效,那么就认为获取锁成功。
注意第二点中,客户端与每个节点都会有一个最大设置锁时间,如果超时就不再该节点建立锁,避免消耗太常时间。
此外,如果客户端没有获取到锁之后,也不要立即重试,否则会出现多个客户端申请同一把锁,然后导致谁也没成功。应该经过一段随机时间之后再重试。
释放锁,释放锁是遍历集群所有master节点,不管它实际上有没有锁。
好了,现在考虑这样一个场景。假如现在Redis集群有5个节点,一个客户端有了1,2,3三个节点的锁。
此时,突然服务器宕机了(不是执行Restart命令),那么此时还没有进行AOF,可能这台机器重启时就没有该锁了,而恰好另外一个客户端又申请了锁,那么此时就会造成两个客户端同时申请了锁。
这种情况目前最好的解决办法是等锁过期再重启,当然这种势必带来性能的下降。
看一下python中的实现:
class Redlock(object):
def lock(self, resource, ttl):
retry = 0
val = self.get_unique_id()
# Add 2 milliseconds to the drift to account for Redis expires
# precision, which is 1 millisecond, plus 1 millisecond min
# drift for small TTLs.
drift = int(ttl * self.clock_drift_factor) + 2
redis_errors = list()
while retry < self.retry_count:
n = 0
start_time = int(time.time() * 1000)
del redis_errors[:]
#遍历所有节点
for server in self.servers:
try:
if self.lock_instance(server, resource, val, ttl):
n += 1
except RedisError as e:
redis_errors.append(e)
elapsed_time = int(time.time() * 1000) - start_time
validity = int(ttl - elapsed_time - drift)
if validity > 0 and n >= self.quorum:
if redis_errors:
raise MultipleRedlockException(redis_errors)
return Lock(validity, resource, val)
else:
for server in self.servers:
try:
self.unlock_instance(server, resource, val)
except:
pass
retry += 1
time.sleep(self.retry_delay)
return False
def unlock(self, lock):
redis_errors = []
for server in self.servers:
try:
self.unlock_instance(server, lock.resource, lock.key)
except RedisError as e:
redis_errors.append(e)
if redis_errors:
raise MultipleRedlockException(redis_errors)不过,RedLock还是存在很大弊端的,不能完全保证准确性。此外它还严格依赖时钟,比如一个服务器时钟异常,锁提前被释放了、比如执行过程中发生较长时间GC,导致锁过期释放,GC结束之后,又来执行业务逻辑等等,具体可以看看文章: RedLock问题
总结Redis分布式锁,实现起来比较简单,但可能会在集群模式下出现数据不一致的问题。而且RedLock算法虽然一定程度上保证了安全性,但却损失了性能。注意,只是一定程度上,RedLock没有全部解决安全性。接下来看另外一种分布式锁,zookeeper分布式锁。
Zookeeper分布式锁
zookeeper分布式锁的优越性完全得益于其自身机制。
相比于Redis,zk分布式锁实现中,在获得锁之前不需要不断地重试,只需要监听即可(利用Watch);在持有锁的服务器宕机之后,也不用等到过期后释放锁,zookeeper会自动将其摘除。
其主要使用了ZK的几个功能:
1、ZK可以创建临时有序节点;
2、节点down之后,可以将临时节点删除;
3、watch监听机制
获取锁的基本流程:
1、客户端创建子节点,并编号,******-01,最早得编号为1,以此累加;
2、客户端判断自己是不是最早的那个子节点(有序节点),如果是就获取锁成功;如果不是,就监听上一个节点,比如编号2监听1,编号3监听2等等。
3、执行完业务代码直接释放锁。
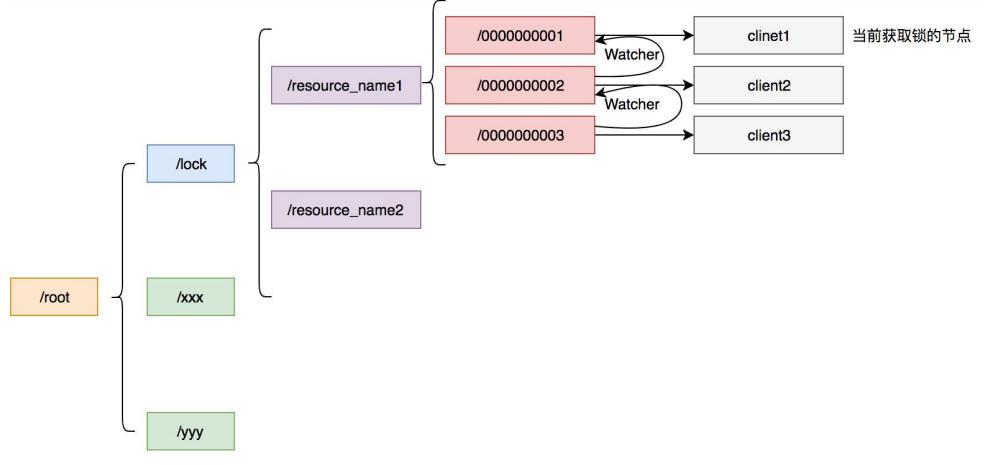
ZK的节点分为持久节点、有序持久节点、临时节点、临时有序节点。实现分布式锁用的是临时有序节点。ZK也经常用于中心,将暴露的服务url注册到ZK上。
Watch监听是ZK比较重要的一个机制,它可以避免惊群效应(这个接触过多进程的应该都熟悉,一次可能会唤醒所有进程,但实际上只能有其中一个执行)。Watch的思想就是客户端注册watch事件到ZK,随后当事件发生后,会回调客户端注册的事件,当前一个节点持有锁且释放了(临时节点删除),客户端感知到就会执行获取锁的过程。
ZK作为一个完美的分布式协调方案,其可靠性要高于Redis,因为zookeeper不用担心突然宕机的问题,因为当某节点出现问题后,会自动摘除该节点,也就意味着自动释放了锁。所以现在很多人都推荐使用ZK分布式锁。但
curator客户端实现了分布式锁,它实现了多种类型的锁,包括互斥锁,读写锁,信号量等。可以直接用,感兴趣的可以看一下源代码。
基于ETCD实现的分布式锁
ETCD是K8s的衍生品,在K8s中发挥关键的作用,主要用于分享配置和服务发现,是用Go写的,现在也经常用来作为分布式锁。不过显然没有上述几种分布式锁常见,说实话我也是今年才接触的,主要是公司让我写一篇专利,我就选题就订了这个。现在市面上好用的ETCD分布式锁客户端也是用golang写的,Java也有,但我认为并不是特别成熟。而且,现在基本上只支持ETCD的互斥锁,没有读写锁等类似于Redisson客户端实现的复杂方案。因此我写的专利就是提出如何基于ETCD实现分布式读写锁,且支持写锁降级、读锁升级等。专利还在受理中,内容不能公布。只能先贴一个我画的一张图,主要展示了我在创建锁的过程中创建的key:
ETCD集成了Redis的高性能(采用K-V存储方式),又借鉴了ZK的高可靠性,但不同于ZK通过自研的ZAB实现强一致性,ETCD通过raft协议来实现一致性,且采用基于HTTP2的grpc实现通信,因此性能要比ZK更好。
和ZK一样,ETCD也有Watch机制,不同的是,其还存在Prefix,Lease以及Revision机制。
- Watch机制:一种监听机制,通过该机制可以对系统内的某个key或者节点进行监听,当监听对象发生变化时,系统会主动给listener发送节点变更事件通知,该机制减少了轮询导致的资源消耗,避免惊群效应。常用于Redis的事务监听、ZK的节点监听、ETCD的key监听。
- Prefix机制:ETCD提供的一种前缀匹配机制,可通过前缀寻找到当前已存在的所有key列表。
- Revision机制:对于ETCD的每一个key,ETCD都会维护一个全局的Revision列表,每新增一个事务,revision自动加1。
- Lease 机制:支持有效期,且可以续期。
总结上面提到的几种分布式锁,现在做一下对比。
从性能上来看,Redis>ETCD>ZK>Mysql,Redis做为一个NoSQL中间件,性能不可比拟,Mysql最差。
从可靠性来看:ETCD>ZK>Redis>Mysql
从实现难易来看:ZK>ETCD>Redis>Mysql。
说句实话,目前我用的比较多的还是Redis。
好文:
微信分享/微信扫码阅读

