
分布式事务
分布式系统之间要保持事务的特性,目前是比较重要的,也是非常普遍的一种现象,现在毕竟是微服务时代。各个系统之间要保证各个逻辑和状态的一致性。此外,由于分库分表导致的跨库事务也需要通过分布式事务实现。
一个典型的例子,银行之间的转账属于典型的联机交易,从账户A转到账户B,可能就需要跨系统实现,账户A的出账以及账户B的入账就是两个独立的业务,为了保证联机交易的一致性,就必须引入分布式事务。
对于事务,大家都知道其需要具备ACID特性,即原子性、一致性、隔离性、持久性,那分布式事务也应该满足这几点,只是有些特性的条件可以放宽。
- 原子性:必须严格遵循,要么成功,要么失败,是事务最基本的特性;
- 一致性:事务完成后的一致性严格遵循;事务中的一致性可适当放宽,目前分布式事务实现的都是最终一致性;
- 隔离性:并行事务间不可影响;有些分布式事务模式的隔离性其实较差,和本地事务比较差;
- 持久性:必须严格遵守,需要持久化到数据库中;
当前的分布式事务模式解决方案:
- XA事务模式。需要依赖于数据库提供的XA事务管理能力;
- AT事务模式。这种是类似于XA,但不是数据库本身的能力,而是应用实现的,如Seata所实现的。
- SAGA模式。
- TCC模式。
- 本地消息表
- 消息队列
分布式事务,一是涉及到分布式系统,二是涉及到事务。分布式系统就避不开CAP理论,CAP是一种理论上的约定,但实际上,我们经常用的是BASE,即只能实现最终一致性,而非强一致性。分布式事务就是这样,在分布式事务中我们只能保证事务的最终一致性。
1、XA事务
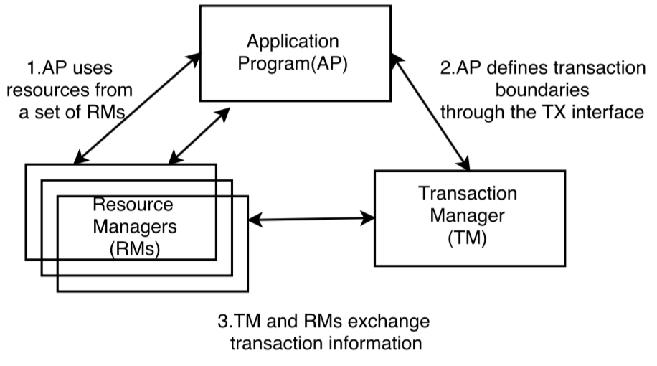
XA事务属于典型的两阶段提交,2PC。适用于不同的系统使用的仍然是同一个数据源。Mysql提供了较好的XA事务管理。
它主要分为预备和提交阶段,然后有一个或者多个资源管理器,以及事务管理器去管理整个过程。
第一阶段,事务管理器会轮询所有资源管理器,让所有资源管理器只在本地执行事务,但不commit,如果失败或异常,就直接返回失败;如果ok就返回自己已经Ready的状态;
第二阶段,如果所有的都是Ready状态,事务管理器就发送Commit命令给每个资源管理器,让他们执行Commit;如果有任何一个返回失败,事务管理器就会发送RollBack命令,告诉每个资源管理器回滚本地事务。
Mysql支持外部的XA事务管理。资源管理器可以是不同的数据源,事务管理器Transation Manger负责管理整个事务。
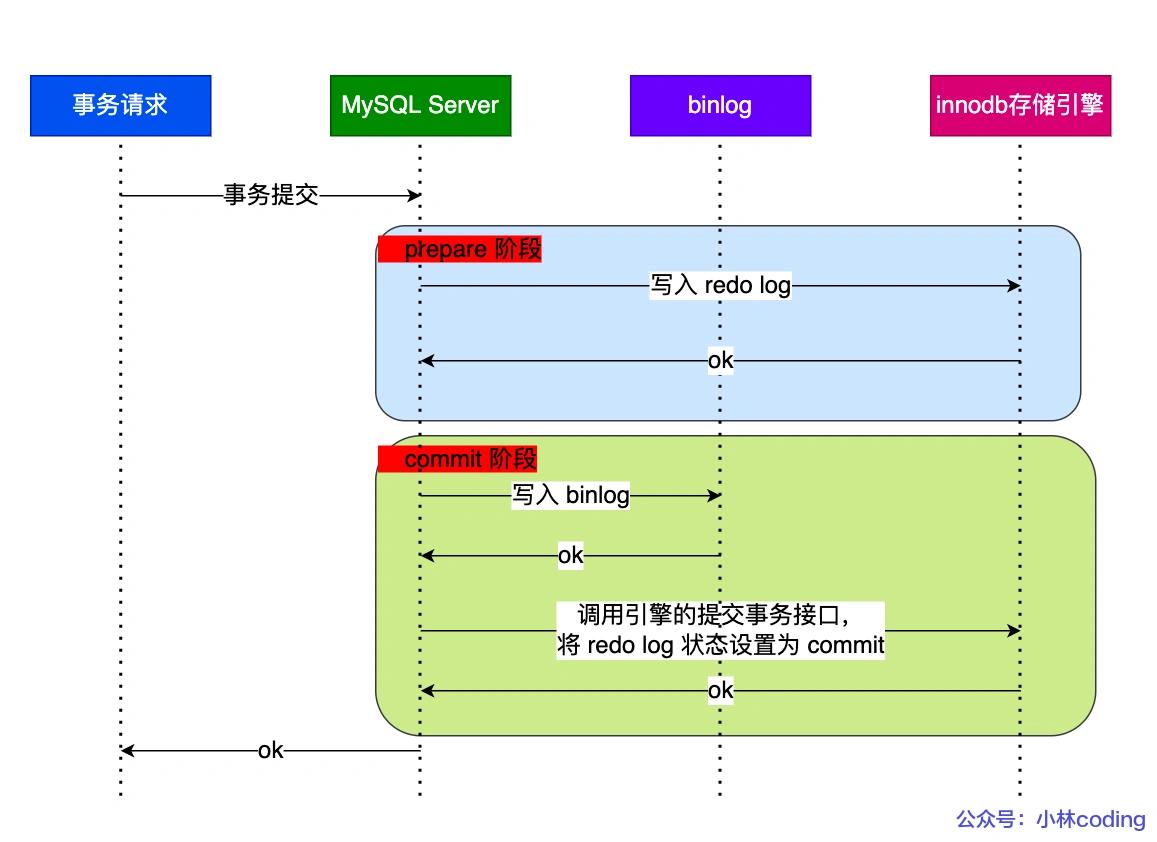
Mysql内部也实现了XA事务,主要是用于redo log和Binlog日志,从而确保服务器崩溃恢复的一致性。
其流程:
1、开启XA事务,生成XID;
2、将XA事务写入到redo log,设置为prepare,并刷盘;
3、写入binlog,刷盘;
4、调用事务提交接口,将redo log中的事务状态commit;
5、刷盘;
XA机制本身存在很多的缺点,比如同步阻塞问题,单点故障问题、数据不一致问题等等。其最严重的还是同步阻塞问题,上面所有的过程都是同步阻塞的,因此是完全无法适应高并发的场景的。
数据不一致的情况会出现在执行第二阶段的过程。事务管理器再向各个资源管理器发送Commit命令的过程中,如果出现宕机,就可能有一部分系统没有执行,从而引起数据不一致的情况。
2、TCC Try-Confirm-Cancel
实际上TCC也是属于两阶段协议的范畴,他是在应用层面实现的一种方式。
Try就是锁住,冻结所有需要修改的资源,如果执行成功就往下走;
Confirm就是开始执行确认提交的操作。比如用户下单了,开始提交订单,扣减库存啊等等。
Cancel就是假如在Confirm阶段有一个失败了,就开始执行对于已经提交事务的逆向取消操作。
TCC好文: 大规模SOA系统中的分布事务处理 Atomic Distributed Transactions: a RESTful Design
该机制最大的缺点是开发成本高,因为这几个阶段需要业务开发自己去实现,所以可以找开源框架结合去做,目前像Seata,hmily等都支持TCC模式,实现思路就是我们需要按照框架的接口开发,try,cofirm,cancel等方法。
但是就我在银行的工作经验来说,TCC实际上有些复杂的,虽然隔离性相当于SAGA模式来说更好,但他引入了冻结,确认,取消等步骤,如果涉及到的节点非常多的情况下,会出现很多我们意料不到的问题。
3、SAGA模式
SAGA模式和TCC模式的区别是,他没有预占的操作,第一步直接操作提交,当遇到异常时直接执行回滚;
众所周知,SAGA模式存在的一个最大问题是,缺少隔离性,即在整个分布式事务完成之前,某个资源的修改是可以被其他事务看得到的;此外,有可能导致,补偿操作失败。比如现在有一个分布式事务:先给账户A充值,再给账户B扣减余额。如果,
A充值后,再执行B扣减时失败,当需要回滚时,发现A充值的钱已经被A取走了。
在银行行业,SAGA模式是使用最多的,但为了避免上述的例子发生,银行必须要从银行的角度出发,避免造成银行的损失,比如上述的例子,一定是先扣减B,再去充值A。
正如在Seata中提到的,流程设计时遵循“宁可长款, 不可短款”的原则, 长款意思是客户少了钱机构多了钱, 以机构信誉可以给客户退款, 反之则是短款, 少的钱可能追不回来了。所以在业务流程设计上一定是先扣款。
3、本地消息表
通过一个消息表的状态,大家统一来进行操作。相当于一个信号量。
目前我们公司有一个地方就使用了该技术。订单和优惠,订单是Golang开发的,优惠是Java开发的。优惠的活动库存、购买库存以及订单服务之间需要保持在一个事务中,这就是分布式。其采用就是消息表的思想。该表用来记录单一资源的状态。订单服务调用优惠进行结算时,如果涉及到库存,优惠首先初始化一个资源数据,并进行锁定,然后开始进行库存的扣减,结算后返回给订单服务,订单服务开始创建订单。如果在这个过程没有异常。订单会返回确认提交信息。优惠从消息表获取到该资源,修改其状态未已提交;如果订单服务出现异常,优惠开始回滚,具体流程是根据订单查找本地消息表找到对应资源。然后根据资源详细信息,开始进行回滚操作,比如加回库存等等操作。
4、消息队列
一个生产者,一个消费者。通过业务场景去做具体的生产-消费。这种就是对于实时性要求不高。比如下单支付了,通知后续的扣积分啊,发货啊等等,只要达到最终一致性的要求即可。消息队列的内容可以移步到 消息队列分类中。目前适用于消息队列的包括 Kafka,RabbitMQ,RocketMQ,NSQ,Redis等等。
5、应用层实现类似数据库的XA
目前,我们公司使用的场景是订单优惠结算的时侯。订单在下单时,会调用优惠的服务。那此时就需要两边要保持一致,比如下单失败了,优惠应该能够执行正常事务的回滚,执行归还优惠券库存等等操作。
具体思路:
首先,当开始执行优惠结算的时侯,订单调用优惠的服务,优惠服务首先会向资源表中写入订单的唯一资源并进行锁定,唯一键是资源id+资源类型。资源id是调用优惠时,随机生成的UUID.randomUUID,同时会存储订单号和商品sku_id;同时,会将资源锁定(根据status字段实现);
接下来,如果订单正常执行下单或者结算操作,会调用优惠的commit接口,优惠服务会将属于该订单的资源表commit,其实也是修改status字段;
如果订单在执行过程中出现问题,那么必须调用优惠的服务进行回滚,优惠要将资源表回滚,也是改状态,然后根据具体优惠类型进行具体回滚操作,比如回滚活动库存等。
两个问题,一是订单实际成功了,但调用优惠commit之前意外down掉了;第二个就是订单实际失败了,调用rollBack之前down掉了。
当然,调用的所有接口都支持重试,且都是幂等的。
阿里也提出了比较优秀的分布式事务解决方案。就是将数据层面的XA移到了应用层。 https://segmentfault.com/a/1190000018057083
补充:目前比较火的是阿里的seata事务,应用得比较广泛,经过考验的: seata官网
阿里: https://segmentfault.com/a/1190000018057083
https://yq.aliyun.com/articles/582282
微信分享/微信扫码阅读
