
gunicorn介绍
一直以来都是用的Gunicorn做HTTP server,近期要对Gunicorn的工作原理及源码学习一遍。本文只是对基本工作原理进行一下学习。
我在 Web部署 一文中也对gunicorn做了简单的介绍,当然主要还是侧重如何使用。
Gunicorn是基于 pre-fork worker模型,运行时会产生一个Maste进程和多个子进程。
先说一下pre-fork
pre-fork服务器和fork服务器相似,通过一个单独的进程来处理每条请求。
不同的是,pre-fork服务器会通过预先开启大量的进程,等待并处理接到的请求。
由于采用了这种方式来开启进程,服务器并不需要等待新的进程启动而消耗时间,因而能够以更快的速度处理多用户请求。
另外,pre-fork服务器在遇到极大的高峰负载时仍能保持良好的性能状态。这是因为不管什么时候,只要预先设定的所有进程都已被用来处理请求时,服务器仍可追加额外的进程。
Master进程只用来管理这些子进程,不负责接收客户端请求;而子进程用来处理请求。Master和Worker之间通过信号沟通。 如下图(摘自一位大牛):
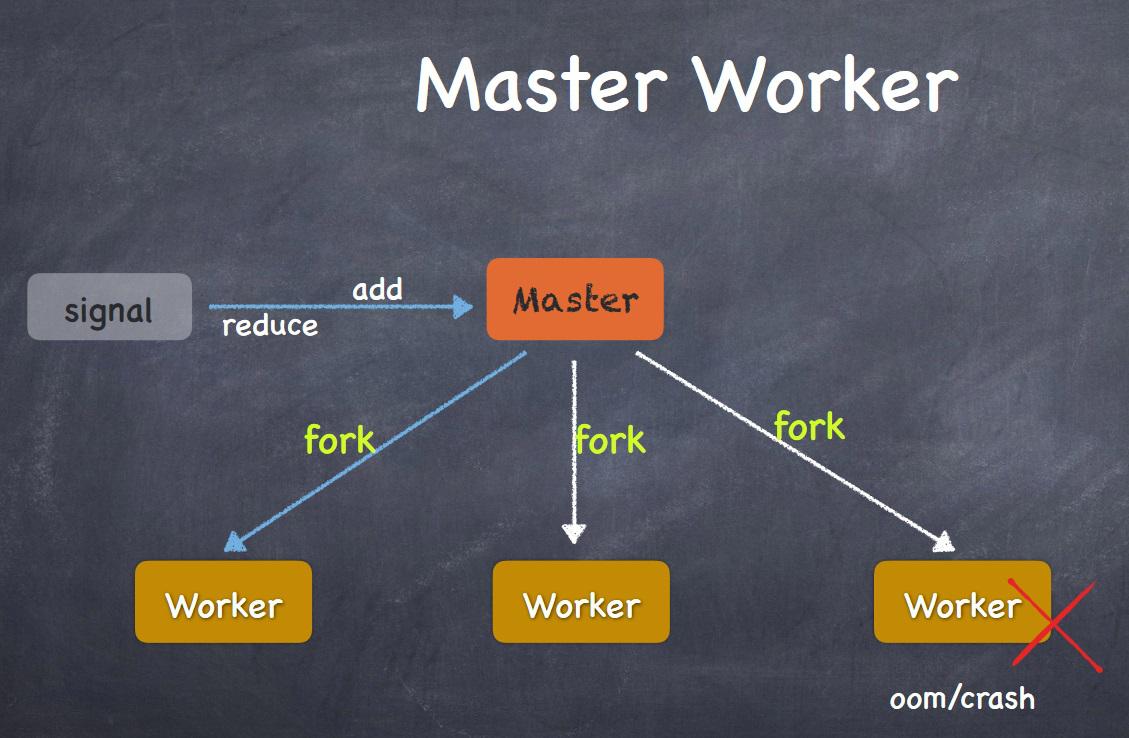
进程之间是通过信号通信,那么信号是至关重要的,gunicorn提供几种不同的信号:
- HUP,重启所有的配置和所有的worker进程
- QUIT,正常关闭,它会等待所有worker进程处理完各自的东西后关闭
- INT/TERM,立即关闭,强行中止所有的处理
- TTIN,增加一个worker进程
- TTOU,减少一个worker进程
- USR1,重新打开由master和worker所有的日志处理
- USR2,重新运行master和worker
- WINCH,正常关闭所有worker进程,保持主控master进程的运行
正常使用gunicorn方法是通过如下命令:
gunicorn dailyblog.wsgi:application -c gunicorn.conf这样gunicorn就运行起来了:
[2017-10-12 09:40:35 +0000] [5597] [INFO] Starting gunicorn 19.6.0
[2017-10-12 09:40:35 +0000] [5597] [INFO] Listening at: http://127.0.0.1:8000 (5597)
[2017-10-12 09:40:35 +0000] [5597] [INFO] Using worker: gevent
[2017-10-12 09:40:35 +0000] [5604] [INFO] Booting worker with pid: 5604
[2017-10-12 09:40:35 +0000] [5605] [INFO] Booting worker with pid: 5605
[2017-10-12 09:40:35 +0000] [5608] [INFO] Booting worker with pid: 5608
[2017-10-12 09:40:35 +0000] [5613] [INFO] Booting worker with pid: 5613先简单说下Gunicorn的工作流程:
-
构建Master Worker的工作模型,Master负责调度Worker进程,通过信号进行增、删、杀、worker进程,而且他还会listen一个端口,或是unix socket上;
-
他用过PIPE传递listen注册上的fd文件描述符 ;
-
真正的worker做的事情很简单,紧紧是通过listening fd不断的accept接受请求而已。 这步中sync.py是这么实现的,如果是gevent thread的gunicorn worker最后要做的事情差不多,只是handler的动作换成了不同的worker调度器而已。
研究一下Gunicorn的源代码,它是如何执行的。
1、首先在setup.py中,有如下代码:
entry_points="""
[console_scripts]
gunicorn=gunicorn.app.wsgiapp:run
gunicorn_paster=gunicorn.app.pasterapp:run
在PYPI上传过代码的人应该都知道这段话的含义了,相当于Linux命令。
关键的是gunicron.app.wsgiapp.run,顺藤摸瓜,找到了run函数:
def run():
"""\
The ``gunicorn`` command line runner for launching Gunicorn with
generic WSGI applications.
"""
from gunicorn.app.wsgiapp import WSGIApplication
WSGIApplication("%(prog)s [OPTIONS] [APP_MODULE]").run()
WSGIAPPLication是一个子类,或者孙类,哈哈。最终我们找到父类BASEAPPLICATION,发现最终调用的是基类的run方法:
def run(self):
try:
Arbiter(self).run()
except RuntimeError as e:
print("\nError: %s\n" % e, file=sys.stderr)
sys.stderr.flush()
sys.exit(1)先说一点,Gunicorn在启动时,首先要读取配置文件的,这里就不讲了。
看Arbiter类是最终的执行类,arbiter英文意思是管理者之类的。好了,到现在我们算是找到了幕后boss了,来一探究竟吧。
Arbiter类有几个重要的方法:
-
start
start 方法负责这些初始化工作:
-
创建 pid 文件。 gunicorn 通过
Pidfile来管理进程的 pid 文件。 -
注册信号事件。通过
init_signals方法实现。 -
创建
LISTENERS
看源代码你会发现,如果已经主进程,这也不会报错,而是会再为主进程取一个新名字。你可以多次运行gunicorn启动命令,会看到有几个主进程,源代码:
def start(self):
"""\
Initialize the arbiter. Start listening and set pidfile if needed.
"""
self.log.info("Starting gunicorn %s", __version__)
# 如果系统中已经存在了一个主进程
# 那么该主进程就要起个新名字
if 'GUNICORN_PID' in os.environ:
self.master_pid = int(os.environ.get('GUNICORN_PID'))
self.proc_name = self.proc_name + ".2"
self.master_name = "Master.2"
2.init_signals
Master 和worker 之间的通信是通过信号来进行的。Master接受到的信号都会放到一个队列中去。一旦队列满了,就不在对信号做出任何反应。见
signal
方法的实现。
signal
方法是除了
SIGCHLD
信号之后的 handler。
def signal(self, sig, frame):
if len(self.SIG_QUEUE) < 5:
self.SIG_QUEUE.append(sig)
self.wakeup()
self.wakeup()
会根据信号名字动态的调用具体的信号处理函数。例如
handle_int
方法就是处理
SIGINIT
的 handler。
3.create_sockets
方法位于 `gunicorn/sock.py'。创建一个监听 socket 的列表,gunicorn 里面叫做 listeners. 用我上面的例子运行,这里只会创建一个 socket。
4. manage_workers :
def manage_workers(self):
"""\
Maintain the number of workers by spawning or killing
as required.
"""
if len(self.WORKERS.keys()) < self.num_workers:
self.spawn_workers()
workers = self.WORKERS.items()
workers = sorted(workers, key=lambda w: w[1].age)
while len(workers) > self.num_workers:
(pid, _) = workers.pop(0)
self.kill_worker(pid, signal.SIGTERM)
def spawn_worker(self):
self.worker_age += 1
worker = self.worker_class(self.worker_age, self.pid, self.LISTENERS,
self.app, self.timeout / 2.0,
self.cfg, self.log)
self.cfg.pre_fork(self, worker)
pid = os.fork()
if pid != 0:
self.WORKERS[pid] = worker
return pid
如果worker数小于配置的worker总数,就会spawn出新的worker;如果大于,就会kill掉一些首端进程。
spawn_worker用来生成新的worker ,就是通过pre_fork模式,具体的worker类型有很多种,有默认的syncworker,ggvent,gthread等等。具体生成哪个当然看你配置的类型了。一般采用gevent可大大提高性能。
对于一个使用gevent的gunicorn, gunicorn 会启动一组 worker进程 , 所有worker进程公用一组listener,在每个worker中为每个listener建立一个wsgi server。每当有HTTP链接到来时,wsgi server创建一个协程来处理该链接,协程处理该链接的时候,先初始化WSGI环境,然后调用用户提供的app对象去处理HTTP请求。
Gunicorn同样会杀掉未用的,空闲的进程。
def murder_workers(self):
"""\
Kill unused/idle workers
"""
if not self.timeout:
return
workers = list(self.WORKERS.items())
for (pid, worker) in workers:
try:
if time.time() - worker.tmp.last_update() <= self.timeout:
continue
except (OSError, ValueError):
continue
if not worker.aborted:
self.log.critical("WORKER TIMEOUT (pid:%s)", pid)
worker.aborted = True
self.kill_worker(pid, signal.SIGABRT)
else:
self.kill_worker(pid, signal.SIGKILL)
5.run
run 是一个入口函数,也是
Master
的主要循环所在。
- 调用 start() 做初始化工作。
-
调用 manage_workers,维持一个固定数量的
worker进程。 -
检查信号队列
SIG_QUEUE。如果队列为空,进程sleep。 所谓sleep就是通过操作系统IO复用,等待前面注册的管道PIPE可写事件。一旦可写,就从信号队列弹出一个信号。并且找到相应的处理函数handler并且执行。 -
每一次循环都通过
murder_workers和manage_workers维持固定熟练数量的 worker。 -
至此,master 进程的工作过程已经比较清晰了。
看一下run方法的源代码(删除部分代码):
def run(self):
"Main master loop."
self.start()
util._setproctitle("master [%s]" % self.proc_name)
try:
self.manage_workers()
while True:
self.maybe_promote_master()
sig = self.SIG_QUEUE.pop(0) if len(self.SIG_QUEUE) else None
if sig is None:
self.sleep()
self.murder_workers()
self.manage_workers()
continue
signame = self.SIG_NAMES.get(sig)
handler = getattr(self, "handle_%s" % signame, None)
handler()
self.wakeup()
上面说到了创建处理链接请求的worker,那worker是如何监听的呢,如何作为http server来调取应用的呢?咱就拿syncworker来说吧。
创建一worker进程后,
- 首先会调用init_process方法,即初始化进程,包括创建管道;
- 然后会加载定义的应用,是你django,flask或其他框架写的app;
- 执行run方法,开始在指定socket监听;
- 一旦有连接后会调用handle方法处理请求。
每个worker都会实例化响应的app对象,app对象也是相互独立、互不干扰的。
那到底是如何实现wsgisever功能的基本要素的呢?如何将解析到的数据发给Django应用的?如何定义start_response回调函数的呢?还有,gevent到底是如何实现并发的?下篇文章要好好研究一下。
微信分享/微信扫码阅读

