
消息队列介绍
我最早使用消息队列应该是在2013年,之前没用过,那时候要使用Celery实现分布式任务,其内部集成了RabbitMQ,通过RabbitMQ来实现任务的发布和消费。后续又逐步接触了Kafka,RocketMQ,我们公司自研的Talos,Notify等等。
目前消息队列的应用比较广泛,主要得益于如下特性:
1、非实时性
一些业务并不需要实时处理;
2、异步
不需要同步进行处理不同业务,可异步去处理;
3、解耦
将不同业务进行分离,生产者和消费者相互独立。
4、流量削峰,限流缓解高并发
比如在秒杀中,经常会用到消息队列进行排队,缓解高并发压力。
目前常用的消息队列:
- Kafka
- RabbitMq
- RocketMQ
- ActiveMQ
- NSQ
我们公司主要使用了基于Kafka的talos、以及RabbitMQ,还有自研的notify。马上要开始大范围使用Rocketmq,talos主要用于存储日志。从订单开始,要开始切为Rocketmq。
对于消息队列,可能要考虑到的问题包括:
- 消息顺序
- 消息重复/消息幂等
- 消息丢失
- 消息事务
- 消息延迟
- 消费优先级
- 消费持久化
- 消息回溯
现在对这几种我接触过的消息队列进行对比,其余的没接触过的这里就不列举了。
|
RocketMQ |
Kafka |
Rabbitmq |
||
|
消息重复/幂等 |
不保证消息重复,需要在消费端自行实现。 但商业版好像可以实现 Exactly once |
不保证消息重复,需要在消费端自行实现。 公司基于Kafka开发了一个talos,它避免了消息重复。基本思想是在生产者生产一个序列号,同样的序列号,使得broker不会再继续处理;在消费端,先查redis缓存,看是否已经处理同样的序列号,如果已处理,就不再继续处理。 |
不保证消息重复,需要在消费端自行实现 |
|
|
消息丢失 |
可以保证at least once ,因此不会丢失。 在生产端,只有broker回复SUCCESS,生产端才人为投递成功; 在消费端,只有回传SUCCESS给broker,才被认为消费成功。 当然,发送模式应该是同步活异步,如果发送模式选择oneway则不保证。 但有一种情况可能出现丢失:broker集群收到消息了,但是采用异步刷盘的话,可能在落盘之前,整个集群都挂掉了,当然发生概率会很低。 |
同理,也可保证消息不丢失 |
可以保证不丢失 但是 队列和消息都要配置持久化 |
|
|
消息持久化 |
支持,持久化到文件 |
支持,持久化到文件 |
需要配置队列和消息的持久化。 |
|
|
消息顺序 |
在同一个逻辑队列中,可以实现消息的顺序。全局也可以,但是效率较差。 当使用顺序消息时,消费端同样要改成顺序消费,否则默认是并发消费。 |
同一个partation下的可以实现消息顺序 |
同理,将要顺序消费的消息放在一个Queue |
|
|
消息延迟 |
支持延迟,延迟实现的方式是时间轮,一个有18个级别的定时。 在到时之前投递在一个专门的TOPIC下。 |
不支持 |
不支持 |
|
|
消息回溯 |
由于最后文件是写到磁盘文件,是支持消息回溯的。但过期删除的查看不了。 |
支持回溯 |
不支持,当消息被消费之后,就会被删除。 |
|
|
消息事务 |
支持在生产者和broker之间的半事务。具体流程可参考官网。简单说就是通过双方的commit,以及事务状态回查来实现。 在事务完全提交之前,是个半事务消息,也不会消费。 |
自0.11开始,kafka就支持了事务 |
虽然Rabbitmq事务机制,但感觉其并非为了支持分布式事务,而只是一种支持At least once的保证机制。 |
|
|
消费重试 |
集群模式下,如果未成功消费,可以重试,超过一定次数进入死信队列; 广播模式下,不支持重试 |
|||
|
消费模式 |
本质上都是PULL模式。其push也是长轮询进行pull |
主要是Push,其也有pull,但性能较差 |
||
|
高可用 |
设置NameServer集群,每个节点都会存储全部的路由和topic信息。 broker集群:多master+多slave 且 broker有专门负责master到slave的同步 |
有主队列和镜像队列,可以保证高可用。 |
||
|
高性能 |
高性能 |
性能一般,主要其采用Push模式 |
||
|
可扩展 |
broker可以实现水平扩展。 |
|||
|
生产流程 |
Broker启动后会和其中一个Nameserver维持长连接,30s发送心跳,保存tocpi信息和broker的地址; Producer会和其中一个NameServer建立长连接。 Consumer也会其中一个NameServer建立长连接。 |
下面是一个基本的消息队列的结构对比图。本文可能会花更多篇幅介绍Kafka和RabbitMQ。
一、系统架构
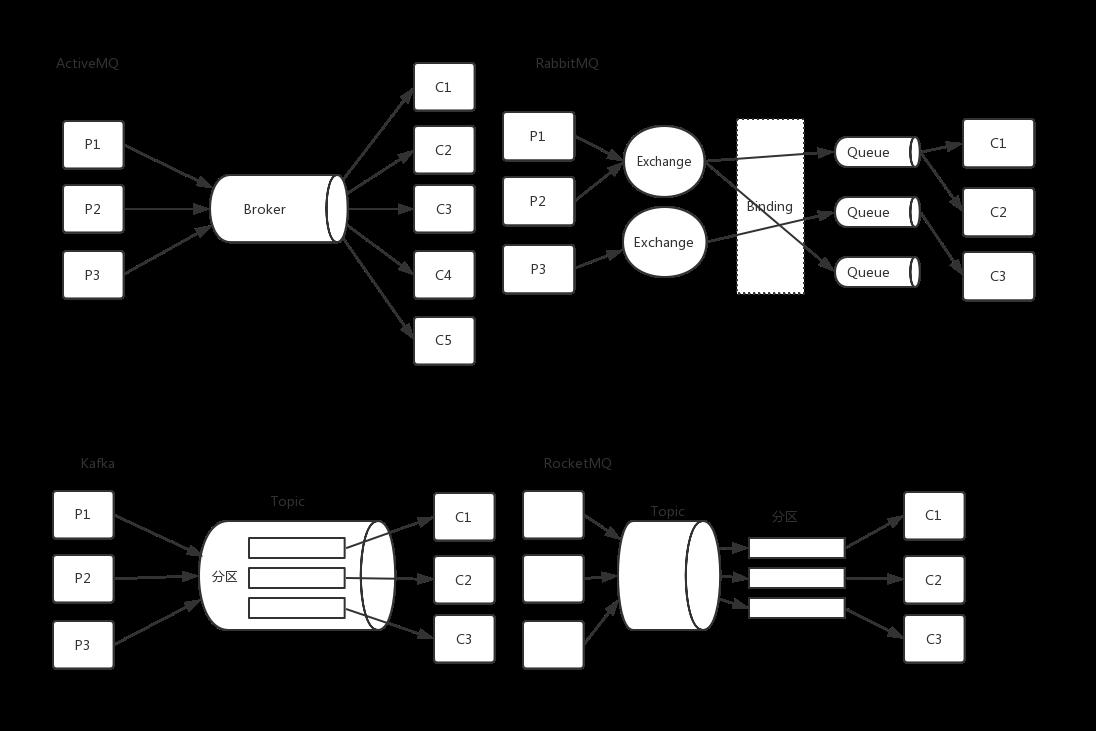
1、RabbitMQ
在RabbitMQ中重要的几个概念:
1、Exchange,发布任务者是将任务消息发送到RabbitMQ的交换器上,剩下其余的工作由它完成。Exchange接到消息后,会根据routing_keys将任务消息路由到指定的队列中。它像一个交互机;
它分为三种类型:
Direct exchange: 如果 routing key 匹配, 那么Message就会被传递到相应的queue中。其实在queue创建时,它会自动的以queue的名字作为routing key来绑定那个exchange。
Fanout exchange: 会向响应的queue广播。
Topic exchange: 对key进行模式匹配,比如ab*可以传递到所有ab*的queue。
2、Queue,任务消息push到队列之后,会根据某种策略将任务消息转发给某个worker。Queue要求消费者必须要有返回确认值。
3、binding,上面说了Exchange会根据routing_key将消息路由到Queue中,那么这路由规则是怎么定的呢?binding在这里就很重要的,RabbitMQ要指定一个binding_key,将Exchange和Queue绑定,然后Exchange会根据routing_key与binding_key匹配,然后选择指定的Queue。当然这里的binding_key不是什么时候都有效,这还与ExchangeType有关。其中最简单的就是direct类型,它会把消息路由到那些binding key与routing key完全匹配的Queue中。
4、Channel 是建立在TCP连接上的通道。关于使用它的原因,有如下介绍:“对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。”。
官网: Rabbitmq官网
0,中文文档: https://rabbitmq.mr-ping.com/tutorials_with_python/[6]RPC.html?q=virtual (一些概念 及使用示例)
1.RabbitMQ原理: http://note.youdao.com/noteshare?id=7d350cd1c16f00004ecd1e2b626730ba
2.RabbitMQ命令: http://note.youdao.com/noteshare?id=f86d14ed2db66543752ae80864cf1094
3.RabbitMQ API: http://note.youdao.com/noteshare?id=48bf61676ccf028ff40b645be86c40e1 官方API文档: https://pulse.mozilla.org/api/
4.RabbitMQ报警: http://note.youdao.com/noteshare?id=f306846ff9ab21597c19a4ca949965bb
5.RabbitMQ可靠性分析: http://note.youdao.com/noteshare?id=4218bff8400d84bc29c22b23ca8a4562
2、Kafka
一个完整的Kafka结构是有多个Producer,多个broker,多个consumer组成的。consumer是按照consumer group划分的。producer就是生产者;一个broker就是一个kafka节点,它可以指定多个Topic,而一个Topic可以分为多个Partition,某个topic的消息在多个Partition分区中存储,而每个partition内部本身是有序的。
官网中,对于消息队列,kafka是这么说的,即它解决了传统消息队列一次只能被一个消费者消费的问题(kafka可以发送给多个consumer group),又解决了发布订阅要发给每一个订阅者的问题(按照consumer group划分后,内部只能被一个consumer消费)。
Messaging traditionally has two models: queuing and publish-subscribe . In a queue, a pool of consumers may read from a server and each record goes to one of them; in publish-subscribe the record is broadcast to all consumers. Each of these two models has a strength and a weakness. The strength of queuing is that it allows you to divide up the processing of data over multiple consumer instances, which lets you scale your processing. Unfortunately, queues aren't multi-subscriber—once one process reads the data it's gone. Publish-subscribe allows you broadcast data to multiple processes, but has no way of scaling processing since every message goes to every subscriber.
The consumer group concept in Kafka generalizes these two concepts. As with a queue the consumer group allows you to divide up processing over a collection of processes (the members of the consumer group). As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
The advantage of Kafka's model is that every topic has both these properties—it can scale processing and is also multi-subscriber—there is no need to choose one or the other.
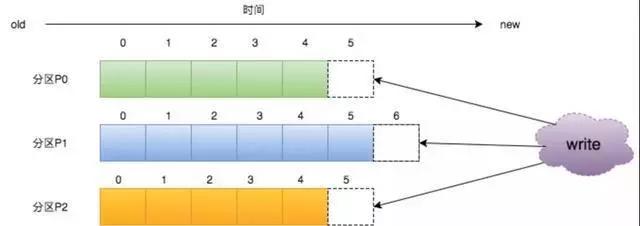
每一个Topic下的消息会被分布到其内部的多个partition中,而partition在Kafka中就是一个追加的日志,一旦有消息发送过来,就会被追加到该日志文件中,而且每个partition内部的消息是有编号的,就是offset,编号是依次递增的。因此,可以保证partition内部,消息是有序的。
我们知道Rabbitmq是有路由规则的。那Kafka的路由规则是如果没有Key值,就轮询发送;如果有Key值,就对Key值进行Hash,然后对分区数量取余。
一篇不错的关于Kafka的介绍: 阿里大牛实战归纳——Kafka架构原理
3、其他的另外两个可以自行看官网。
消费模式对比
1、Rabbitmq
支持push和pull两种模式。但是pull模式的性能非常差。不过Push模式的确也存在问题的,比如你push的消息频率过快,导致consumer没办法消费不过来。为了避免这个问题,可以为消费者配置限流策略。
引用一篇文章的一个段落:
Why push and not pull? First of all it is great for low latency. Secondly, ideally when we have competing consumers of a single queue we want to distribute load evenly between them. If each consumer pulls messages then depending on how many they pull the distribution of work can get pretty uneven. The more uneven the distribution of messages the more latency and the further the loss of message order at processing time. For that reason RabbitMQ's Pull API only allows to pull one message at a time, but that seriously impacts performance. These factors make RabbitMQ lean towards a push mechanism. This is one of the scaling limitations of RabbitMQ. It is ameliorated by being able to group acknowledgements together.
2、Kafka
采用的是pull模式。因为Kafka采用了分区的做法,自己可以调整自己的消费速率,比如一个partition对准一个consumer等等。它没有采用push主要是考虑上述说的push过多,不及时消费,可能会导致消息阻塞。
综上所述,现在采用pull模式较多,比如kafka和Rocketmq,像Rabbitmq这种,我是感觉不是非常适合业务量较大的情况,尤其是电商。
然而对于Pull模式,其实是存在一定的笔端,比如不能及时消费消息或者会造成很长一段时间的请求浪费。为了能够平衡pull模式的缺点,Kakfa采用了长轮询的方法。
长轮询简单来说就是消费者去拉消息,如果没有消息就阻塞,一直到达超时时间。然后重启发起请求。
看一下消费者的实现:
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
acquireAndEnsureOpen();
try {
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
// poll for new data until the timeout expires
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
if (!updateAssignmentMetadataIfNeeded(timer)) {
return ConsumerRecords.empty();
}
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE))) {
log.warn("Still waiting for metadata");
}
}
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.pollNoWakeup();
}
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
}
}
下面就上面提到的消息处理的问题进行一下对比。
1)顺序消息
提到顺序消息,其实要包括几个方面,包括生产者的顺序生产,消息队列的FIFO,消费者的顺序消费。
三个方面是缺一不可的。生产者和消费者那就需要两端在生产和消费消息的时侯进行业务控制了。本文谈论的就是消息队列是否可以保持先入队的消息,先出队。
不过,就目前来看,保证消息的有序性一般只能满足局部有序,而无法保证全局有序。如果真想实现全局有序,那么应该不是消息队列干的,可以考虑其他实现方式,比如单独使用Redis的有序集合。
Kafka目前可以实现局部的有序性,它可以保证同一个partition下的消息是有序的,因为每一个partition下的内容是以日志的形式追加的,新加一个就会增加offset,它可以保证唯一顺序递增的。因此,如果想保证有序性,可以考虑将需要有序的消息都发到同一个partition下。
Rabbitmq如果想实现顺序消费的话,也是将需要顺序处理的消息放到一个队列里,然后一个consumer对应处理一个queue中的消息。
最后还是提一句,上面说的就是保证顺序入队,顺序出队。并不包括消费者的顺序消费。因为就算是顺序出队,如果消费者是并发消费处理,同样保证不了顺序性。
总而言之,如果真需要保证消息的有序,需要生产者,消息队列,消费者三方共同配合完成。
2)消息持久化
1)Rabbitmq
Rabiitmq中的持久化要分成三部分来说,交换机(exchange),队列(queue),消息(message),这三部分都是可以持久化的。
交换机其实并不是实际存在的一个交换机,只是一张拥有路由到不同队列的信息表。它可以是持久化,也可以暂存。
队列可以是持久化的,它是存在磁盘上的,当broker重启后,它是可以恢复的。注意,这里说的恢复是指队列本身,并不包括队列里的消息。
好了,最后说到消息的持久化,消息是可以保存在内存中,也可以保存在磁盘上。如果真要实现消息的持久化,就需要满足交换机,队列和消息都是持久化的。这样再broker重启后,exchange,queue都恢复到原来的模样,消息会重新放到原来的队列里。
但官网建议尽量不要持久化,因为这样会降低性能。此外,在集群模式下,持久化队列在其他节点不能恢复;非持久化队列是可以被恢复的。不过自从3.6.0版本后,Rabbitmq引入了 Lazt queue的概念,即把内容先放到磁盘上,待真正有请求来消费它,再把内容加载到内存,目的是要解决那些长队列的问题,比如因为消费者挂了,消费没有及时消费,或者突然来了一波流量高峰等等,相当于限流中的漏通算法。
2)Kafka
其实上面也提到了kafka的日志,也就是说kafka的消息都是以日志的形式存储的,都是以追加的形式持久化到磁盘的日志中的。它可以以O(1)的时间复杂度进行操作。因为写操作会直接追加到日志末尾,并增加offset,读操作是根据最大chunk尺寸和偏移量直接读取数据。chunk size用来表示最大获取消息的总长度(间接的表示消息的条数).根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可。Kafka的segment的作用就是为了方便后续进行磁盘清理。
看到了上面两种方式,也可以发现Rabbitmq适合于信息量不是特别高的场景;Kafka适用于大公司的一些信息量较大,比如记录日志的一些场景。
3)消息幂等/消息重复/丢失
正常情况下,我们的确希望消息不会重复发送,不会丢失。但一般消息队列都很难做到消息不重复,此外也需要业务端保证消息的幂等性,消息队列保证不了。现在分析一下消息的传输机制。
目前对于消息的三种常见模式:
- At most once :消息可能会丢,但不会重复传输;
- At least one :消息绝不会丢,但可能会重复传输;
- Exactly once :每条消息肯定会被传输一次且仅传输一次.
1)Rabbitmq
从broker到consumer,它要求消费者在消费后要返回一个Ack,然后才会把消息从队列中删除。这样就确保了At Least Once。这样会导致消息重复消费,那么就会要求业务端来实现消息的幂等性了。
从Producer到Broker,它采用了两种模式事务机制和confirm机制,可以保证数据不丢失,At least once。当然默认清苦哪个下,broker是不会返回任何信息给消费者的,意思就是At most once。
详细介绍两种机制(摘抄):
- 事务机制,事务确实能够解决producer与broker之间消息确认的问题,只有消息成功被broker接受,事务提交才能成功,否则我们便可以在捕获异常进行事务回滚操作同时进行消息重发。RabbitMQ中与事务机制有关的方法有三个:txSelect(), txCommit()以及txRollback(), txSelect用于将当前channel设置成transaction模式,txCommit用于提交事务,txRollback用于回滚事务,在通过txSelect开启事务之后,我们便可以发布消息给broker代理服务器了,如果txCommit提交成功了,则消息一定到达了broker了,如果在txCommit执行之前broker异常崩溃或者由于其他原因抛出异常,这个时候我们便可以捕获异常通过txRollback回滚事务了。
事务步骤:
- client发送Tx.Select
- broker发送Tx.Select-Ok(之后publish)
- client发送Tx.Commit
- broker发送Tx.Commit-Ok(只有提交到所有的镜像队列,才会返回 tx.commit-ok)
- 发布方确认机制。生产者将信道设置成confirm(确认)模式,一旦信道进入confirm模式,所有在该信道上面发布的消息都会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,RabbitMQ就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这就使得生产者知晓消息已经正确到达了目的地了。RabbitMQ回传给生产者的确认消息中的deliveryTag包含了确认消息的序号,此外RabbitMQ也可以设置channel.basicAck方法中的multiple参数,表示到这个序号之前的所有消息都已经得到了处理。 一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认(ack)之后,生产者应用便可以通过回调方法来处理该确认消息,如果RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息,生产者应用程序同样可以在回调方法中处理该nack消息。
发布方确认步骤:
- 代码中使用 confirm.select方法将信道设置为发送方确认方式
- rabbitmq返回confirm.select-ok,表示同意设置信道为confirm模式。(默认要返回,如果将no-wait参数设置为true时候,服务端不需要返回confirm.select-ok)
- 生产者发送消息到rabbitmq,当rabbitmq将消息同步到所有镜像队列后,返回ack(包含消息的唯一ID)给生产者。
注意:两种方式不能共存,由于没有事务的消息回滚,并且可以异步发送消息,因此发送方确认模式更加轻量,更加快速。
2)Kafka
Kafka支持At Least once和At most once。
从生产者到kafka,和Rabbitmq类似,也是在broker收到消息后,回复一个commit消息。假如收不到commit消息,就会重新发送,这样能确保at least once,Kafka默认是这样的。
当然,如果控制producer永远不重新发送,那么就可以实现at most once。
从broker到consumer可以先处理再返回commit,也可以先返回commit,再消费消息。
我们公司用的talos中,解决消息幂等消费是从生产者和消费者两端入手的。
生产者端提交去重:每次生产一条消息,分配一个唯一的sequenceNumber序列号,这样即使生产者提交信息后,由于接收不到talos提交信息反馈导致重传了,talos也会根据sequenceNumber进行去重处理。
消费者端去重:先根据接收到消息的sequenceNumber进行去缓存里(set数据结构)查,不存在则代表没有处理过该消息,业务逻辑处理该条消息,处理完后将sequenceNumber存入redis的set中;存在代表消费过,那么就不处理。redis相当于一个去重缓存。
不过看网上资料,是说自0.11.0.0起,Kafka Producer支持幂等传递选项,保证重新发送不会导致在日志中出现重复项。它在一定程度上实现了excatly once。感兴趣的可以阅读一下这篇文章: Kafka设计解析(八)- Exactly Once语义与事务机制原理
简单来说也是从几点入手,一是在生产者发送到broker的消息是幂等的,也是通过为生产者分配id以及为消息分配序列号来实现的。不过它也只能满足单个Session内的幂等,基于此Kafka提出了事务机制。大体上是利用一个由应用程序提供的事务ID(Transction ID),来保证跨Session的多个读写操作的原子性。
4)消息回溯
消息回溯的意思就是已经消费的消息是否能找回来。
对于Rabbitmq来说,上面已经说了,消费之后就会被删除,所以它不支持消息回溯;
对于Kafka来说,因为它是将信息以日志的形式顺序存储到磁盘上,所以根据offset是完全可以回溯的。
其他的没研究。
5)负载均衡
Kafka的负载均衡做得相对比较好,它利用zookeeper做协调管理,所有kafka的元数据(metadata)会存储在zookeeper中。一般一个Topic下的不同分区会被分到不同的broker(kafka)上。
生产者可以根据topic和key利用某种负载均衡算法将消息发送到不同的机器上。
消费者可以分配consumer group,将一些消费者分配到一个组中,分别消费。如果有消费者变化,重新触发负载均衡。
相对于Kafka,Rabbitmq做得一般,它当然也可以根据交换机种类和key,然后将消息路由到不同的队列。但是,对于生产者,需要知道有那些交换机,哪些队列。这个是很不友好的。不过Rabbitmq也可以通过建立master-slave集群。
在消费端,Rabbitmq通过某种均衡算法将消息push给消费者。
不过如果想要实现更优化的负载均衡,可以再借助LVS等实现。
6)高可用
1)Rabbitmq
Rabbitmq是高可用的,它可以以集群的方式部署,此外,可以使用镜像模式的队列。
由于Rabbitmq是采用Erlang开发的,因此它有着天然的分布式优势,各个集群节点之前都过一个主用的 Erlang Cookie进行通信,这使得每个节点的元数据都可以被集群中的任何一个节点感知(除了队列本身里的消息数据)。它的通信和信息同步和Kafka的不同之处就是它并不需要于第三方的软件(zookeeper)。
当然,如果单单是集群,还不行,因为队列中的消息是无法同步的。因此Rabbitmq引入了另外一种模式,叫镜像队列。它是一种主从模式的队列,主节点队列负责与客户端沟通。然后通过一种组播协议将消息同步到从队列中。该组播协议(GM)是一种原子操作,可以保证所有slave节点要么都收到了master的消息,要么就都没收到。当主队列失效后,最老的salve会被选为master队列。
一篇介绍集群的好文: Rabbitmq集群原理
2)Kafka
Kafka也是高可用的,其实在上面的一些地方也已经说了,是集群通过zookeeper进行管理,如果有Leader挂掉了,就会冲洗年选举。此外分区(Partition也是复制的,具体逻辑在另一篇文章有介绍: 分布式一致性算法 。
Kafka 分配Replica 的算法如下:
- 将所有存活的N 个Brokers 和待分配的Partition 排序
-
将第i 个Partition 分配到第(i mod n)个Broker 上
- 这个Partition 的第一个Replica 存在于这个分配的Broker 上
- 并且会作为Partition的优先副本
- 将第i 个Partition 的第j 个Replica 分配到第((i + j) mod n)个Broker 上
对于消费者消费消息这块。除了Kafka,一般都是一个消息只会被一个消费者消费,当然,前提是消息正常消费了。Kafka支持了消费者分组,同一个消费可以被发送不同消费者分组中的某一个消费者。
上述谈到的消息队列,都有较强的消息异步传输功能,之前我在看laravel代码时,看到过其自身实现的Queue,感觉很强悍的,他队列存储可以用Mysql,可以用Redis,SDS等等。采用数据库的时候,根据数据库的排它锁以及多个字段来保证消息的正确消费;Redis时会采用3个队列来实现,一个list,两个有序集合。
最后分享一篇较好的消息队列对比的文章: 综合对比消息队列
微信分享/微信扫码阅读

