
Java集合深度学习
java集合主要分两大阵营,Map和Collection。先看Map
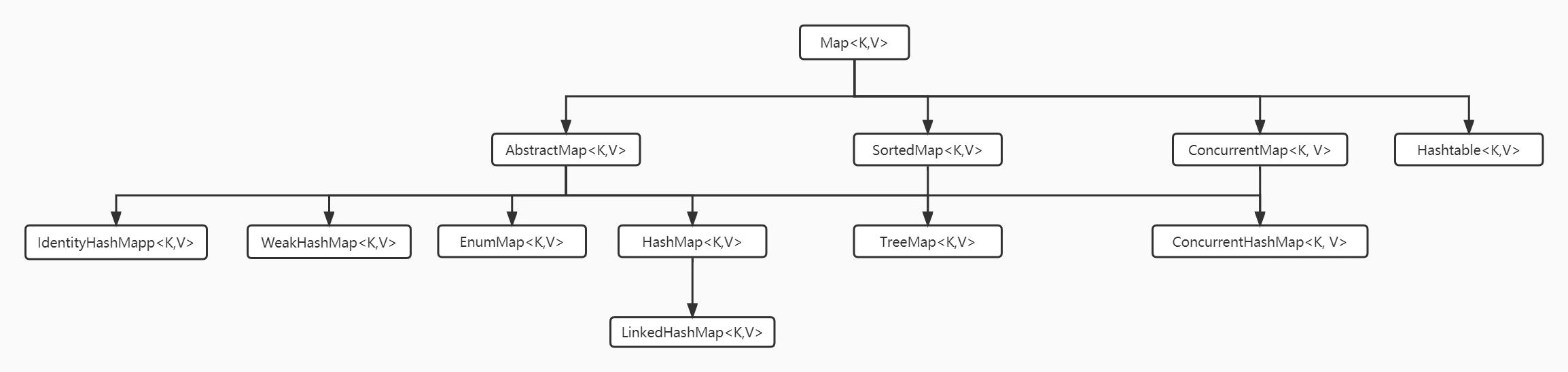
HashMap
先看看问题:
1、为什么是线程不安全的;
2、什么时侯红黑树退化成链表;
3、添加元素、扩容步骤
添加的过程:
如果索引数组是null,要扩容进行初始化。
1、计算出key的hash值;
2、如果对应索引位置是空,直接写入新节点,否则走第3步;
3、如果目标位置旧数据等于待插入数据,则更新该索引位置,否则走第4步;
4、如果是红很黑数,则走红黑数逻辑;如果是链表,则遍历,如果是某一个,则更新,如果不是,则插入到链表尾部;
5、size+1,如果此时数量大于threadshold,就要进行扩容。
扩容步骤:
当数组为空,初始化一个容量16,负载因子0.75的数组;
如果不是,就进行两倍的扩容;
如果当前位置的next是null,直接计算hash取模得到新位置坐标赋值(当然,也是原数组位置或者原数组位置+oldCap(原数组长度)),如果是有冲突数据,原数据或者移动到对应的索引位置,或者移动到对应索引位置+原数组的大小。
扩容触发条件:
1、数组为空;
2、冲突链表长度达到阈值 TREEFY_THREADHOLD 8,但整个hashMap的size不到64;
3、hashMap的size达到阈值 16 *0.75=12;
Hashmap的容量为什么是2的次幂?
最重要的原因就是为了保证hash的均匀分布。
其计算在数组的位置时,使用了 hash &(n-1),其中n就是数组的长度,当n是2的幂次时,正好n-1是全1,与运算可以尽量保留hash值得本身数据,如果不是2的幂次,n-1之后的二进制有些位置就是0,与运算可能会导致不同hash值最后计算的位置是相同,增大了hash冲突的可能性。
其次,采用2的次幂的另外一个原因是增加计算速度。我们知道,通常情况下,我们在计算key在数组中的bucket时,会进行取模运算,即拿hash % 数组长度。这种计算方式相当于位运算还是慢的。使用2的次幂,可以直接 n-1进行位运算。
ConcurrentHashMap
ConcurrentHashMap是并发操作比较优秀的容器,目前也是得到了广泛的应用。
在JDK1.8之前,其采用数组+链表的结构,并将整个数组分段(Segment),并定义一个内部类Segment,其继承自ReentrantLock,有了段,加锁时不必将整个Map加锁,只需要对某个段加锁,这样不会将整个Map锁死。它的思想就是将整个锁分离,从而提高并发性能。
自JDK1.8开始,其数据结构和HashMap一样都是采用了数组+链表+红黑数的数据结构。它不再使用之前的分段锁,而是使用CAS+synchorized锁实现,关于CAS的介绍,我之前写过文章: Java多线程共享变量同步机制 。但是1.8仍然保留了原有的Segment的概念,这是为了兼容之前版本的序列化。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
它调用了一个原子操作:
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}看上面代码可看见其调用了Unsafe的getObjectVolatile这个native方法。通过使用volative定义,保持了数据可见性。
其他原子操作:
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
casTabAt即采用CAS的方式更新数据。
ConcurrentHashMap在执行put操作的时侯,主要有三个重要的并发控制。
1、但table是空时,会初始化数据。此时会通过volatile变量进行CAS操作来初始化数组initTable;注意他是使用sizectl这个volatile变量来决定是否可以初始化数组,如果小于0,则Thread.yield,类似于自旋。
2、如果对应数组元素(链表表头或者红黑树的根)为null(根据volatile保证可见性),就采用CAS添加,即调用上面的casTabAt;
3、如果不为null,就使用synchorized加锁。代码可查看源码的putVal方法。
再注意另外一点的是,Concurrenthashmap的扩容和HashMap是不同的,他不是一下完成的,其他的线程也会进行helpTransfer(触发节点是遇到了FowardingNode,这个对象是在扩容时,将oldTable对应位置设置成该对象,该对象的hashcode是MOVED)。每个线程分配的桶数是16,如果小于16,就一个线程处理。任务是从后往前分配。关于扩容比较好的文章: ConcurrentHashMap扩容
Collection容器
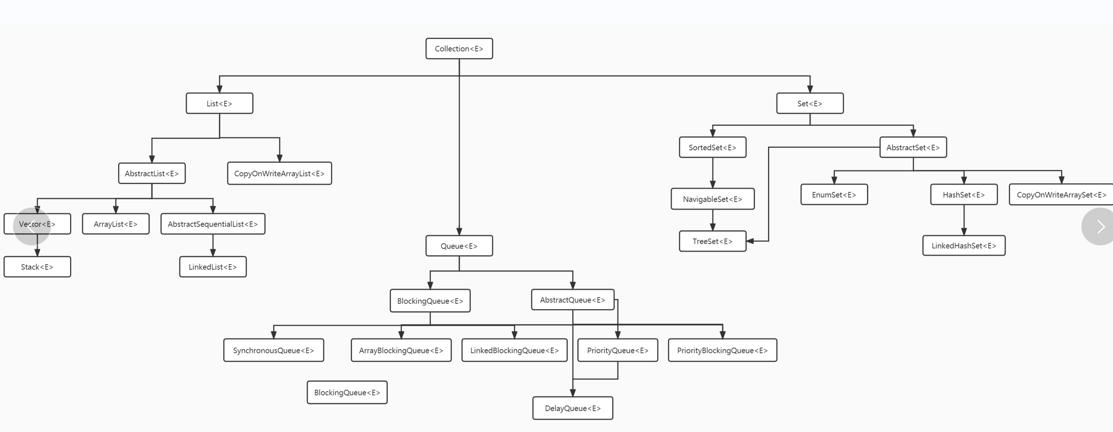
ArrayList,LinkedList是两种比较常用的列表,都不是线程安全的。
arrayList容易报出超过边界的异常,以及值的覆盖。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}第一句是扩容时,使用,执行这句时,可能size都刚好等于数组容量,都没有触发扩容。随后线程1添加了元素,线程二也开始添加元素,但这是size已经+1了,此时就会出现越界;如果线程2拿到的size没有+1,则会出现数值覆盖的场景。
两者性能的对比(补充:实际上不能拿ArrayList和LinkedList对比,而应该是ArrayDeque和LinkedList对比,两者都是实现Deque双端队列)。
ArrayDeque插入的元素不可为null。
获取元素过程
arrayList有 get和indexOf,get比较快,其是直接访问对应索引下标位置的数据,如果是indexOf比较慢,需要遍历;
linkedList就需要遍历链表获取了(根据目标索引的值来决定是从前遍历还是从尾遍历)。
添加元素过程
arrayList可以添加到尾部,也可以是目标位置。如果添加到尾部,且不需要扩容的话,速度还是可以的;如果不是尾部,就需要进行复制,如果再赶上扩容,就比较惨了。
linkedList默认是加到链表尾部,如果根据位置也是根据位置决定从前还是从尾部。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
删除元素过程
删除和添加一样。arrayList删除的元素越在后面,性能越好,删除最后的元素性能最好。
并发容器CopyOnWriteArrayList
写时复制,简单思想是在有写入或者删除操作时会拷贝新的一份数组数据,执行完后,设置新数组,在整个写入过程会加入可重入锁。
它的优点是在进行写入的过程,读请求不会阻塞,写入时候会加入ReentrantLock,因此写和写肯定是阻塞的。其缺点也比较明显,即不能保证数据的一致性,此外因为要进行复制,会额外造成内存浪费。所以,该容器更多得适用于读多写少,且对数据一致性要求不高的场景。否则,请使用读写锁ReentrantReadWriteLock。读写锁是分别有一个读锁,一个写锁,读锁是共享锁,写锁是独占锁。
CopyOnWriteArrayList这点和操作系统的RCU非常类似。
队列Queue的实现除了PriorityQueue,基本上都是支持并发的容器,多用于线程池中,如ArrayBlockingQueue,LinkedBlockingQueue等等。其实还有一种队列时Deque,是双端队列,这里就不展开说了,可以看一下ArrayDequeue,官方的意思可以使用其模拟栈,取消使用Stack。
ArrayBlockingQueue:是一个数组结构的有界阻塞队列,此队列按照先进先出原则对元素进行排序。底层使用数组,容量不可改变,初始化必须指定容量大小。执行put方法时,当队列满了,执行入队会阻塞,会执行condition notFull的await;执行take方法时,如果队列为空,会阻塞,执行notEmpty的await。入队成功会调用notEmpty的signal;出队成功会调用notNull的signal,这两个signal会唤醒阻塞的线程。
LinkedBlockingQueue:和ArrayBlockingQueue类似,只不过是其使用单链表实现的,且可以不指定初始容量大小,默认是Integer.MAX_VALUE。静态工厂方法Executors.newFixedThreadPool使用了这个队列。
SynchronousQueue :一个不存储元素的阻塞队列,每个插入操作必须等到另外一个线程调用移除操作,否则插入操作一直处理阻塞状态,吞吐量通常要高于LinkedBlockingQueue,Executors.newCachedThreadPool使用这个队列。这个有点像golang中的channel。
PriorityBlockingQueue:优先级队列,时基于数组的堆结构,进入队列的元素按照优先级会进行排序。对应的非阻塞队列是PriorityQueue,定时任务中使用的就是该队列。其在初始化时要指定初始容量,其会自动扩容。扩容大小:
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));DelayQueue:一个使用优先级队列实现的无界阻塞队列。
而阻塞队列的实现主要依赖于Condition接口。
Condition主要有两个基本方法:await方法和signal方法,一个用于等待,一个用户唤醒线程。
Condition必须依赖于Lock接口,生成Condition可通过可重入锁lock.newCondition()生成。
总结支持并发的容器:
CopyOnWriteArrayList 上面已经介绍了。
ConcurrentHashMap 三大利器:volatille +CAS+synchronized锁。
HashTable
多个阻塞队列 ,在上面提到的一些阻塞队列。
ConcurrentLinkedQueue
ConcurrentLinkedDeque
ConcurrentSkipListMap 跳表的结构 相对于 TreeMap,是线程安全的(利用CAS操作),且在和红黑树有相同的查询效率的情况下,进行删除和插入操作需要付出的代价更小。
微信分享/微信扫码阅读

