
Java并发编程之基本使用
本文就是介绍简单的Java多线程的使用。
1、实现Thread子类;
2、实现Runnable接口;
3、实现Callable接口;
4、线程池;
1、实现Thread子类
protected class MyThread extends Thread {
@Override
public void run() {
log.info(String.format("I am %s",Thread.currentThread().getName()));
try
{
Thread.sleep(1000L);
}catch (Exception e){
log.error("{} in {}",e.getMessage(),Thread.currentThread().getName());
}
log.info("finish {}",Thread.currentThread().getName());
}
}只要继承了Thread基类,并重载run即可
2、实现Runnable接口
protected class ThreadRuable implements Runnable {
@Override
public void run() {
System.out.println(String.format("I am %s",Thread.currentThread().getName()));
try
{
Thread.sleep(1000L);
}catch (Exception e){
log.error("{} in {}",e.getMessage(),Thread.currentThread().getName());
}
log.info("I am {}",Thread.currentThread().getName());
}
}只要实现了Runnable接口即可。
对于上面两种,一般情况下,使用Runnable更妥,因为Java的线程池可以有效管理实现Runnable接口的线程,而我们通常情况下使用线程池更多一些。
但Runnable本身也存在一些“缺点”,打引号的意思是说它是缺点,并不意味着就是它的不足,只是在某些特定环境下,可能不适用。即它不能返回值,也不能抛出异常,如果有些特定场景下希望可以得到返回值的话,就不能用Runnable(我觉得这样的场景不多,我们完全可以通过全局变量或者中间件来传递变量),可以考虑实现Callable接口。
3、Callable接口
protected class ThreadCall implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println(String.format("I am %s",Thread.currentThread().getName()));
try
{
Thread.sleep(1000L);
}catch (Exception e){
log.error("{} in {}",e.getMessage(),Thread.currentThread().getName());
}
log.info("I am {} call",Thread.currentThread().getName());
return (int)Thread.currentThread().getId();
}
}
public void rune(){
log.info("Start to exec multi thread at {}",DateLib.getCurTimeStamp());
for (int i=1;i<10;i++){
// Thread thread = new Thread(new ThreadRuable()); //Thread子类
// Thread thread = new Thread(new MyThread()); //实现Runnable接口
FutureTask<Integer> futureTask = new FutureTask<Integer>(new ThreadCall());
Thread thread = new Thread(futureTask);
thread.start();
try
{
// log.info("get from futuretask result :{}", futureTask.get()); //get方法会阻塞线程
}catch (Exception e){
log.error(e.getMessage());
}
}
log.info("multi thread are finished at {}",DateLib.getCurTimeStamp());
}一般Callable会配合线程池使用
public void rune(){
log.info("Start to exec multi thread at {}",DateLib.getCurTimeStamp());
ExecutorService executorService = Executors.newFixedThreadPool(10);
List<Future> futures = new ArrayList<Future>(10);
for (int i=1;i<10;i++){
Future future = executorService.submit(new ThreadCall()); //提交有返回值的;无返回值的使用execute方法
futures.add(future);
}
executorService.shutdown();
for (Future future:futures){
try{
log.info("get result from future:{}",future.get());
}catch (Exception e){
log.error(e.getMessage());
}
}
try{
Thread.sleep(1000L);
}catch (Exception e){
}
log.info("multi thread are finished at {}",DateLib.getCurTimeStamp());
}get方法会一直阻塞直到线程执行完成。
上面的Future对象提供了很多的使用方法:
public abstract interface Future<V> {
public abstract boolean cancel(boolean paramBoolean);
public abstract boolean isCancelled(); //检测在任务在正常完成前是否已经取消
public abstract boolean isDone(); //检测任务是否已经完成
boolean cancel(boolean mayInterruptIfRunning); //取消任务
public abstract V get() throws InterruptedException, ExecutionException; //获取返回结果
public abstract V get(long paramLong, TimeUnit paramTimeUnit)
throws InterruptedException, ExecutionException, TimeoutException;
}
上面使用的Future是按照添加的顺序执行的,某些场景还是希望哪些完成,就执行哪些,因此还有一种实现方式是使用CompletionService。
public void rune(){
log.info("Start to exec multi thread at {}",DateLib.getCurTimeStamp());
ExecutorService executorService = Executors.newFixedThreadPool(10);
CompletionService<Integer> cs = new ExecutorCompletionService<Integer>(executorService);
for (int i=1;i<10;i++){
executorService.submit(new ThreadCall());
}
executorService.shutdown();
for (int i=1;i<10;i++){
try{
log.info("get result from future:{}",cs.take().get());
}catch (Exception e){
log.error(e.getMessage());
}
}
try{
Thread.sleep(1000L);
}catch (Exception e){
}
log.info("multi thread are finished at {}",DateLib.getCurTimeStamp());
}当然,完全可以把其理解为非阻塞的。
4、线程池
在日常应用中,更多的还是使用线程池的。因为无限制的创建线程是存在很多的风险的。
比如增加了系统资源的消耗,线程的建立和释放过程都占用一定的系统资源。此外,无限制的占用资源,不断地增加内存消耗,对系统来说是很危险的,因为一般我们的Server对JVM最大内存都是有限制的,很有可能发生OOM。
线程池很好得解决了上面的问题,线程池内部会有一个阻塞队列,要执行的任务会被放到阻塞队列,线程会从中去任务来执行。当有新任务加入阻塞队列中,一个空闲线程会将其取出执行。
我从网上找了一张线程池的UML图
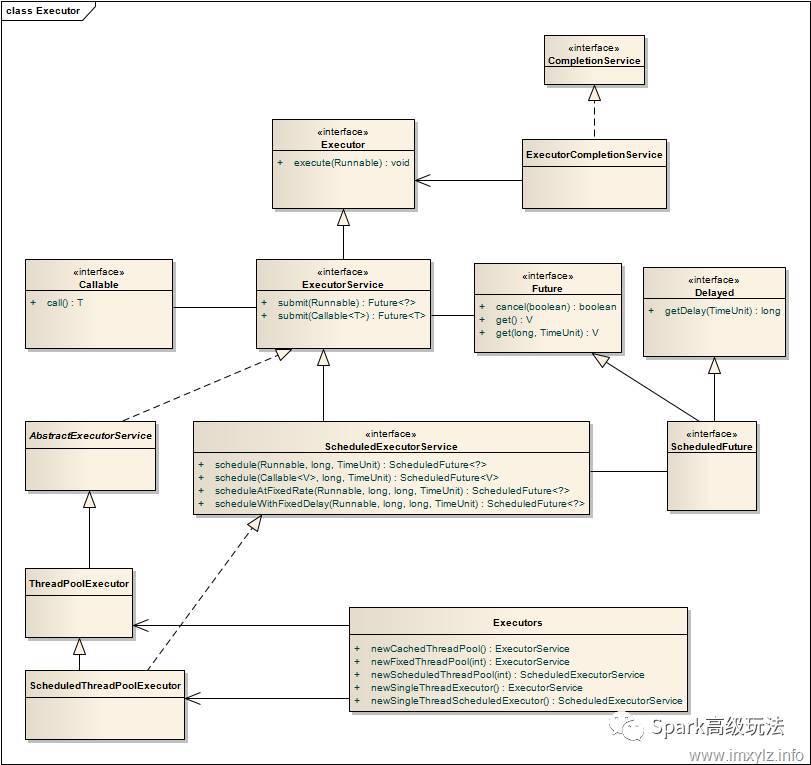
上面Executors是基础接口,主要可执行实现Runnable的线程。
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
其最重要的子接口是ExecutorService,它本身定义了具体的一些行为方法。
1,execute(Runnable command):执行Ruannable类型的任务,
2,submit(task):可用来提交Callable或Runnable任务,并返回代表此任务的Future对象
3,shutdown():在之前的任务都已经提交,且没有新任务接受,关闭,该操作不会等待之前的任务都执行完成。
4,shutdownNow():停止所有任务,并返回正在等待的任务列表。
5,isTerminated():测试是否所有任务都履行完毕了。
6,isShutdown():测试是否该ExecutorService已被关闭。线程池本身也是有状态变化的,主要包括RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
线程池的基础实现类是ThreadPoolExecutor.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
Executors的几个创建线程池的方法其实都是使用该类创建的。阿里对于线程池的创建的建议也是直接使用
ThreadPoolExecutor,主要是我们自己控制各种参数,防止出现OOM。
现在解释一下里面的参数。
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
corePoolSize是表示核心线程池大小。如果当前线程池的线程数量小于该值,当有一个新任务需要执行时,即使现在有空闲的线程,也会新建一个线程。
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
maximumPoolSize表示线程池允许创建的最大的线程池数。
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
字面意思已经很清楚了,当线程池的数目大于核心线程数(corePoolSize)时,空闲线程可存活的时间。当超过了这个时间,空闲的线程就会被回收。
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
workQueue消费队列,主要有以下几种:
ArrayBlockingQueue:是一个数组结构的有界阻塞队列,此队列按照先进先出原则对元素进行排序
LinkedBlockingQueue:是一个单向链表实现的阻塞队列,此队列按照先进先出排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool使用了这个队列。
SynchronousQueue :一个不存储元素的阻塞队列,每个插入操作必须等到另外一个线程调用移除操作,否则插入操作一直处理阻塞状态,吞吐量通常要高于LinkedBlockingQueue,Executors.newCachedThreadPool使用这个队列。这个有点像golang中的channel。
PriorityBlockingQueue:优先级队列,时基于数组的堆结构,进入队列的元素按照优先级会进行排序。
至于选择哪种就要看实际情况。如果想要一个带有边界的就选择数组结构的,如果想要没有边界的,可考虑链表结构的队列。虽然有不同数据结构实现的队列,但他们的本质都是阻塞型队列。
一个简单的例子:
public class ThreadPoolPra {
private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
5,
10,
10,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
public void run(){
log.info("start to run thread pool example at {}",DateLib.getCurTimeStamp());
for (int i = 1;i<10 ;i++){
threadPoolExecutor.execute(
()-> {
log.info("it is thread:{} in pool",Thread.currentThread().getName());
try{
Thread.sleep(1000L);
}catch (Exception e){
log.error(e.getMessage());
}
log.info("finish thread:{} in pool",Thread.currentThread().getName());
}
);
}
threadPoolExecutor.shutdown();
try{
Thread.sleep(2000L);
}catch (Exception e){
}
log.info("main thread pool example is finished at {}",DateLib.getCurTimeStamp());
}
}Executors类中实现了几个创建线程池的方法,但在设计业务中,并不建议直接用,主要考虑以下方面:
1) FixedThreadPool 和 SingleThreadPool :
使用的阻塞队列时链表队列LinkedBlockingQueue,允许的请求队列长度为 Integer.MAX_VALUE ,可能会堆积大量的请求,从而导致 OOM 。
2) CachedThreadPool 和 ScheduledThreadPool :
允许的创建线程数量为 Integer.MAX_VALUE ,可能会创建大量的线程,从而导致 OOM 。
再多说以下ScheduledThreadPool,它使用的时DeleyWorkQueue,这时一种基于堆结构的阻塞队列,和上面的PriorityBlockingQueue类似。
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}线程池的任务提交过程:
1、如果当前线程池中的线程数小于corePoolSize,就会新建线程;
2、如果当前队列未满,就向队列添加任务;
3、如果队列已满,且线程数小于maxPoolSize,就新建线程;
4、如果队列已满,且线程数大于maxPoolSize,就执行拒绝策略。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}线程池的生命周期:
RUNNING: Accept new tasks and process queued tasks
* SHUTDOWN: Don't accept new tasks, but process queued tasks
* STOP: Don't accept new tasks, don't process queued tasks,
* and interrupt in-progress tasks
* TIDYING: All tasks have terminated, workerCount is zero,
* the thread transitioning to state TIDYING
* will run the terminated() hook method
* TERMINATED: terminated() has completed
再说下关于线程池大小的设定,线程池大小设置为多少才合适。这个还要看我们的程序是计算密集型的还是IO密集型的。
如果是计算密集型的,那么线程池大小一般设置为CPU数量+1即可,+1是为了确保如果偶尔因为某个线程因为页面缺失或其他原因暂停时,可以切换到多余的线程,确保CPU时钟周期不被浪费掉;对于IO 密集型的可以使用更多的线程来执行,至于设置成多少,在《Java并发编程实战》提到了一个公式,根据CPU数量,等待时间和计算时间比等等因素。也就是说实际上对于IO密集型任务来说,并没有一个严格的标准,应该设置成多少,而是要根据实际的系统配置和任务类型来决定。所以我们在编程的时侯可以自己试试,设置不同的线程,看看哪个数量的线程池利用率最高。
我在本地模拟了一下,CPU是8核,我所写的任务的等待时间核比达到6.1。当我设置最大线程数是8时,CPU利用率达到60%左右,当我线程数设置为60时,几乎快跑满整个计算机的CPU了。
但是要注意出现线程饥饿死锁。线程饥饿死锁是指任务间的相互依赖,执行中的任务一等待着等待队列中的任务二执行完再处理,但任务二需要等任务一处理完才能够执行。这通常会出现在但线程池或者线程池不够大的场景。
线程池需要注意的问题:
线程池的参数要设置合适,要考虑几个因素:
1、CPU利用率,性能提升;
2、内存,注意不要因为并发处理,导致OOM(使用有界队列,控制同一时刻并发量);
关于线程池较好的文章: 线程池的介绍
微信分享/微信扫码阅读

