
Linux之零拷贝技术
拷贝技术简单说就是一种数据从一个地方拷贝到另外一个地方的IO操作,比如从磁盘到内核空间,从内核空间到用户空间等等。在传统的I/O中,数据拷贝的过程会经历频繁的CPU上下文切换,进行多次拷贝过程,这本身对系统造成了一定的系统消耗,且效率低下。零拷贝技术就是为了解决这些问题,减少CPU的频繁切换,减少数据的拷贝技术。
首先看一下传统的IO操作过程。
假设现在有一个操作是读取磁盘上的文件数据,并通过网络发送出去,那么其经历的过程如下:
(图片来源于网络)
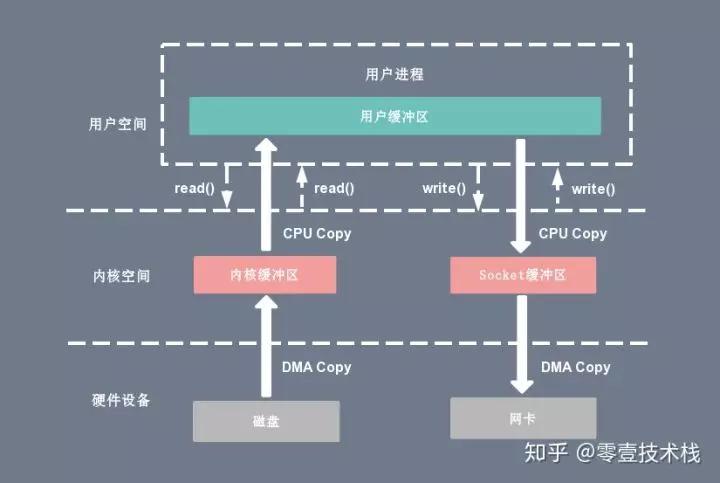
流程:
1、调用read函数,读取磁盘文件的数据,数据通过DMA(Direct Memory Access,直接读取内存,不需要CPU中段)的方式从磁盘中拷贝到内核空间;
2、数据从内核空间拷贝到用户空间,需要CPU直接参与。
3、开始执行write函数,数据从用户空间拷贝到内核空间的Socket缓冲区,CPU直接参与。
4、数据通过DMA的方式从内核空间写入到网卡中,发送出去。
其实上面的流程,相比于之前的CPU中断的方式已经减少了两次CPU的参与,已经减少了CPU的切换,这要得益于DMA,DMA传输时时通过DMA控制器实现的,CPU会把总线控制权交给DMA控制器,完成后再交还给CPU。但这还不够,仍然存在两次CPU的拷贝。为了优化整个过程,有以下几种方式:
- 用户态直接IO;
- 写时复制技术;
- 零拷贝技术(减少拷贝次数);
1、用户态直接IO
就是绕过内核空间,直接从硬盘将数据拷贝到用户空间,减少了拷贝的过程,因此在一定程度上提高了性能。但其也有局限性,且CPU运算和IO操作不匹配,容易造成资源浪费。
使用直接IO的要求:
- 用于传递数据的缓冲区,其内存边界必须对齐为块大小的整数倍
- 数据传输的开始点,即文件和设备的偏移量,必须是块大小的整数倍
- 待传递数据的长度必须是块大小的整数倍。
使用直接IO的方式就是在打开文件时加上O_DIRECT选项,这样系统就知道要通过直接IO方式访问。
int open(const char *pathname, int flags);
open函数打开一个文件描述符,参数flags如下:
-
O_WRONLY:表示我们以"写"的方式打开,告诉内核我们需要向文件中写入数据; -
O_DSYNC:每次write都等待物理I/O完成,但是如果写操作不影响读取刚写入的数据,则不等待文件属性更新; -
O_SYNC:每次write都等到物理I/O完成,包括write引起的文件属性的更新; -
O_DIRECT:执行磁盘IO时绕过缓冲区高速缓存(内核缓冲区),从用户空间直接将数据传递到文件或磁盘设备,称为直接IO(direct IO)。因为没有了OS cache,所以会O_DIRECT降低文件的顺序读写的效率。
2、写时复制
之前我有一篇文章专门写了关于写时复制技术的。具体可见: 写时复制 。其基本思想就是在读时共向内存数据,只有在写时才会拷贝数据出来。
3、零拷贝技术
(1)实现一:mmap
(图片来源于网络)
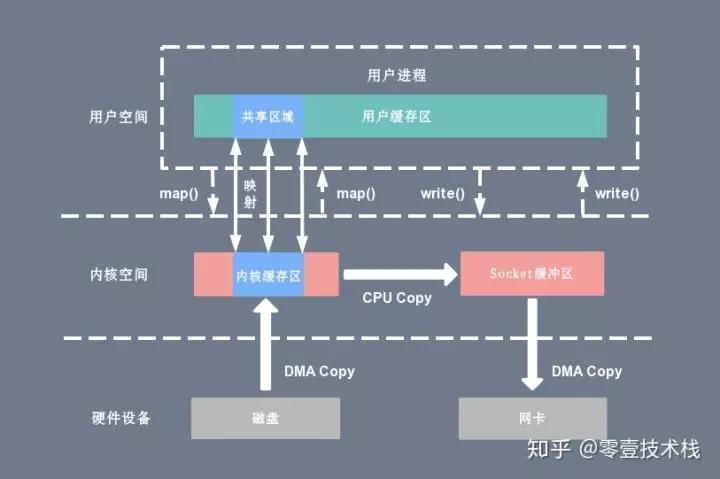
其基本思想就是取代了传统的read()操作,改用mmap,由于其实现了内核和用户空间的一个内存共享,即不需要再从内核空间将数据拷贝到用户空间了,相对于传统的I/O,减少了一次CPU copy的操作,提升了效率。
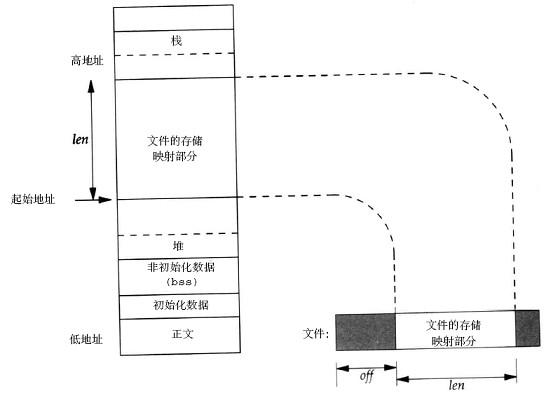
mmap是Linux系统中的系统调用,它是一种内存映射方法,可以将文件地址与虚拟地址空间的一部分虚拟地址进行一一映射,如下图。实现了该对应关系后,进程可以使用指针操作内存,系统负责数据回写,提高了数据交互的效率,就如上面那样。更详细得关于mmap介绍,可参考: 认真分析mmap:是什么 为什么 怎么用 mmap官方文档
mmap虽然提高了数据访问效率,但自身也存在着缺点。
1、mmap映射区域大小必须是物理页大小的整倍数(32位系统是4k字节),因此有时会造成空间得浪费,尤其是对于小文件。
2、就是当某个进程执行mmap文件时,其他进程如果此时该文件被其他进程操作时侯,可能引发系统发送SIGBUS信号,抛出异常。具体原因来自POSIX规定:
The mmap() function can be used to map a region of memory that is larger than the current size of the object. Memory access within the mapping but beyond the current end of the underlying objects may result in SIGBUS signals being sent to the process. The reason for this is that the size of the object can be manipulated by other processes and can change at any moment. The implementation should tell the application that a memory reference is outside the object where this can be detected; otherwise, written data may be lost and read data may not reflect actual data in the object.
(2)实现二:sendfile
sendfile用于文件描述符之间的拷贝,由于其完全是在内核中完成的,因此执行效率更高。其中输入文件描述符(in_fd)需要支持mmap(也就是说不是Socket),out_fd在2.6.33之前必须是socket,之后的内核可以支持任一的文件。
sendfile函数原型: ssize_t sendfile(int out_fd , int in_fd , off_t * offset , size_t count );
不过也分为常规的sendfile,以及DMA辅助的sendfile。常规sendfile同样是经历三次拷贝,只不过解决了mmap中存在的问题。DMA辅助的sendfile还会进一步减小拷贝次数。下图是对应示意图:
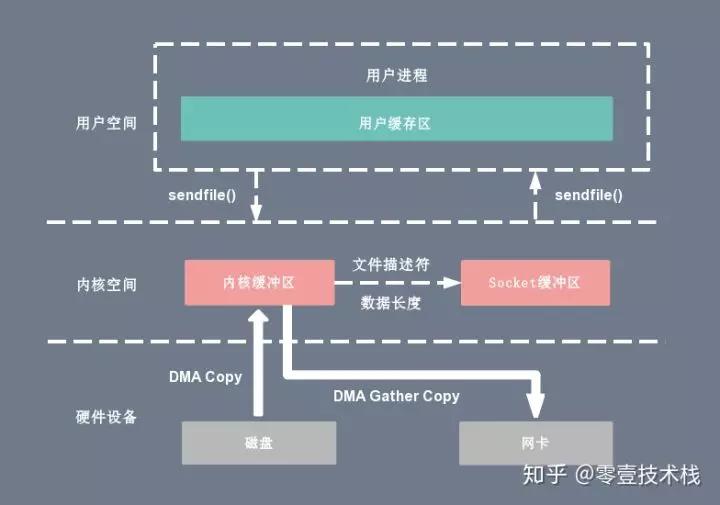
用户空间调用sendfile后,首先DMA控制器会将数据拷贝到内核空间,如果是常规的sendfile,就进行一次CPU拷贝。如果是DMA辅助的,DMA控制器会根据偏移量以及数据长度,将内核空间要拷贝的数据拷贝到Socket缓冲区。偏移量就是上述函数原型中的offset,count就是表示要拷贝的数据长度。然后根据偏移量和长度信息直接从内核内核缓冲区拷贝到网卡。
sendfile的缺点是在拷贝过程中,在out_fd消费这些传输数据之前不允许修改:
If out_fd refers to a socket or pipe with zero-copy support, callers
must ensure the transferred portions of the file referred to by in_fd
remain unmodified until the reader on the other end of out_fd has
consumed the transferred data.
sendfile官方文档: http://man7.org/linux/man-pages/man2/sendfile.2.html
缓冲区共享
简单说就是在虚拟地址空间建立块缓冲区,可以缓存一些数据,避免频繁拷贝,但对程序与系统的软硬件的配合要求较高。有一篇关于这方面的介绍可以看看: PostgreSQL共享缓存区管理
最后说一下另外一个概念PageCache。
上面很多次提到了内核缓冲区,其实这就是PageCache,也叫页缓存。那这个是干啥用的?
我们都知道相对于CPU的处理速度,磁盘IO速度是相当慢的,因此为了提高系统调用性能,会将磁盘数据缓存到内存中,从而提高读取速度。不过PageCache是有大小限制的。默认是4K,在64位操作系统是8k。
可以使用vmtouch查看一个文件所占用pagecache大小:
aibo@haiboInxiaomi:/home/work/admin$ vmtouch bill_to_db.sh
Files: 1
Directories: 0
Resident Pages: 0/1 0/4K 0%
Elapsed: 0.000175 seconds
haibo@haiboInxiaomi:/home/work/admin$ vun bill_to_db.sh
Command 'vun' not found, did you mean:
command 'vue' from snap vue (3.3.0)
command 'zun' from deb python3-zunclient (4.0.0-0ubuntu1)
See 'snap info <snapname>' for additional versions.
haibo@haiboInxiaomi:/home/work/admin$ vim bill_to_db.sh
haibo@haiboInxiaomi:/home/work/admin$ vmtouch bill_to_db.sh
Files: 1
Directories: 0
Resident Pages: 1/1 4K/4K 100%
Elapsed: 0.000199 seconds
参考资料:
Linux系统中的Page cache和Buffer cache
微信分享/微信扫码阅读

