
高并发之负载均衡
由于单台服务器会受到带宽、内存、处理器等多方面因素的影响,所以往往在实际应用中需要同时部署多台服务器提供服务,而多台服务器会采用某种方法实现流量的分摊,实现负载的均衡。
说起负载均衡,一般都会想到下面几种:
DNS负载均衡
LVS负载均衡
Nginx负载均衡
三者从不同维度实现了流量分流。DNS主要是不同地理位置(不同机房)的负载均衡,LVS通过软件方式实现网络层的负载均衡,Nginx也是通过软件实现的负载均衡(主要是七层,现在也支持四层)。除此之外,随着微服务的发展,目前微服务框架也实现了负载均衡,比如Dubbo本身也提供了多种负载均衡策略。本文就针对以上几点做简要概括。
任何一个负载均衡都要支持按照某种算法选择一个后端server,也要实现集群容错,即如果出错了,你希望该如何处理。再有就是能够动态检测。
目前存在的几种负载均衡算法和策略:
随机(Random):把请求随机分配给内部中的多个服务器
轮循(Round Robin):每一次请求轮流分配给内部中的服务器。此种均衡算法适合于服务器组中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
权重轮循(Weighted Round Robin):根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。此种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
响应时间(Response Time):对内部各服务器发出一个探测请求(例如Ping),然后根据各服务器对探测请求的最快响应时间来决定哪一台服务器来响应客户端的服务请求。
最少连接数均衡(Least Connection):对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器,使负载更加均衡。此种均衡算法适合长时处理的请求服务,如FTP。
处理能力均衡:把服务请求分配给内部中处理负荷(根据服务器CPU型号、CPU数量、内存大小及当前连接数等换算而成)最轻的服务器,由于考虑到了内部服务器的处理能力及当前网络运行状况,所以此种均衡算法相对来说更加精确。
目标地址散列(Destination Hashing): 根据请求的目标IP地址,作为散列键(Hash Key)从散列表找出对应的服务器。
源地址散列(Source Hashing):根据请求的源IP地址,作为散列键(Hash Key)散列表找出对应的服务器。
一致性Hash:根据URL等一致性hash选择服务请求的服务器。
Failover: 检测服务器状态, 仅把请求发给能正常工作的服务器;或者待状态恢复正常后再选择该服务器。
接着具体说一下具体的几种负载均衡
Dubbo负载均衡
对于集群部署的dubbo service,在调用时,dubbo会根据某种算法从服务列表中选择其中一个,从而实现服务的负载均衡。dubbo主要提供了四种算法,即随机算法,罗宾轮询算法、最小活跃数算法以及一致性hash算法。
先看下继承关系:
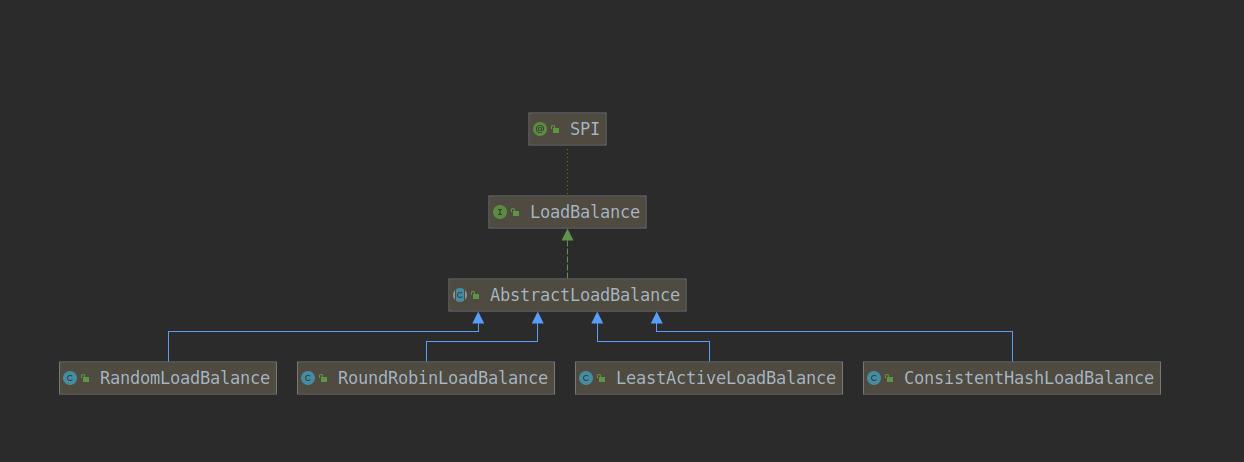
在进行invoker选择的时候,如果服务列表只有一个就直接返回,否则根据算法进行选择。先看下选择invoker的整体逻辑:
@Override
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
if (invokers.size() == 1) {
return invokers.get(0);
}
return doSelect(invokers, url, invocation);
}上面的doSelect就是实现类具体实现的算法,上面提到了主要有4种算法。
1、加权随机算法
思想:服务集群中的每个服务都配置一个权重weight,默认是100。如果所有权重相等,则完全随机选择一个;否则根据权重随机选择一个。比如现在有两个服务A,B,权重分别是100,200,那么选取比例就是 1/3,2/3。
看下源码:
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers
int length = invokers.size();
// Every invoker has the same weight?
boolean sameWeight = true;
// the weight of every invokers
int[] weights = new int[length];
// the first invoker's weight
int firstWeight = getWeight(invokers.get(0), invocation);
weights[0] = firstWeight;
// The sum of weights
int totalWeight = firstWeight;
for (int i = 1; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
// save for later use
weights[i] = weight;
// Sum
totalWeight += weight;
if (sameWeight && weight != firstWeight) {
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight.
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < length; i++) {
offset -= weights[i];
if (offset < 0) {
return invokers.get(i);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
2、RoundRobin
最简单的轮询就是依次轮询,比如有N太服务器,编号从0到N-1依次轮询执行,没有任何的复杂算法。
下面是一个简单的实现:
public class RoundRobinBalance {
public static final List<Integer> selectList = Lists.newArrayList(1,2,3);
private int getWeight(Integer integer){
return integer;
}
private AtomicInteger atomicInteger = new AtomicInteger(-1);
public int simpleRoundRobin(){
int index = atomicInteger.addAndGet(1);
int length = selectList.size();
if (index >= length){
index = atomicInteger.addAndGet(-length);
}
return selectList.get(index);
}
}但实际中,每台服务器可能配置不同,我们需要为不同服务器增加不同的权重,部分服务器需要大概率被选中,权重就设置大一些,否则就设置小一些。带权重的轮询俗称WRR算法。
WRR目前有两种实现方式,一种是Nginx实现的平滑最大权重,dubbo也是参考这种模式。二是LVS实现的算法。
Nginx & Dubbo:不同权重的服务器,每次选择权重最大的,选中后,该权重会减去总权重,随后会加上其初始值。
类似下面的过程:
In case of { 5, 1, 1 } weights this gives the following sequence of
current_weight's:
a b c
0 0 0 (initial state)
5 1 1 (a selected)
-2 1 1
3 2 2 (a selected)
-4 2 2
1 3 3 (b selected)
1 -4 3
6 -3 4 (a selected)
-1 -3 4
4 -2 5 (c selected)
4 -2 -2
9 -1 -1 (a selected)
2 -1 -1
7 0 0 (a selected)
0 0 0
看一下dubbo的实现:
public class RoundRobinLoadBalance extends AbstractLoadBalance {
public static final String NAME = "roundrobin";
private static final int RECYCLE_PERIOD = 60000;
protected static class WeightedRoundRobin {
private int weight;
private AtomicLong current = new AtomicLong(0);
private long lastUpdate;
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
current.set(0);
}
public long increaseCurrent() {
return current.addAndGet(weight);
}
public void sel(int total) {
current.addAndGet(-1 * total);
}
public long getLastUpdate() {
return lastUpdate;
}
public void setLastUpdate(long lastUpdate) {
this.lastUpdate = lastUpdate;
}
}
private ConcurrentMap<String, ConcurrentMap<String, WeightedRoundRobin>> methodWeightMap = new ConcurrentHashMap<String, ConcurrentMap<String, WeightedRoundRobin>>();
private AtomicBoolean updateLock = new AtomicBoolean();
/**
* get invoker addr list cached for specified invocation
* <p>
* <b>for unit test only</b>
*
* @param invokers
* @param invocation
* @return
*/
protected <T> Collection<String> getInvokerAddrList(List<Invoker<T>> invokers, Invocation invocation) {
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
Map<String, WeightedRoundRobin> map = methodWeightMap.get(key);
if (map != null) {
return map.keySet();
}
return null;
}
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.get(key);
if (map == null) {
methodWeightMap.putIfAbsent(key, new ConcurrentHashMap<String, WeightedRoundRobin>());
map = methodWeightMap.get(key);
}
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
Invoker<T> selectedInvoker = null;
WeightedRoundRobin selectedWRR = null;
//找出当前权重最大的,并计算总权重。
for (Invoker<T> invoker : invokers) {
String identifyString = invoker.getUrl().toIdentityString();
WeightedRoundRobin weightedRoundRobin = map.get(identifyString);
int weight = getWeight(invoker, invocation);
if (weightedRoundRobin == null) {
weightedRoundRobin = new WeightedRoundRobin();
weightedRoundRobin.setWeight(weight);
map.putIfAbsent(identifyString, weightedRoundRobin);
}
if (weight != weightedRoundRobin.getWeight()) {
//weight changed
weightedRoundRobin.setWeight(weight);
}
long cur = weightedRoundRobin.increaseCurrent();
weightedRoundRobin.setLastUpdate(now);
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = invoker;
selectedWRR = weightedRoundRobin;
}
totalWeight += weight;
}
//主要是清除缓存用的。
if (!updateLock.get() && invokers.size() != map.size()) {
if (updateLock.compareAndSet(false, true)) {
try {
// copy -> modify -> update reference
ConcurrentMap<String, WeightedRoundRobin> newMap = new ConcurrentHashMap<String, WeightedRoundRobin>();
newMap.putAll(map);
Iterator<Entry<String, WeightedRoundRobin>> it = newMap.entrySet().iterator();
while (it.hasNext()) {
Entry<String, WeightedRoundRobin> item = it.next();
if (now - item.getValue().getLastUpdate() > RECYCLE_PERIOD) {
it.remove();
}
}
methodWeightMap.put(key, newMap);
} finally {
updateLock.set(false);
}
}
}
if (selectedInvoker != null) {
selectedWRR.sel(totalWeight);
return selectedInvoker;
}
// should not happen here
return invokers.get(0);
}
}
LVS的wiki说明:
Supposing that there is a server set S = {S0, S1, …, Sn-1};
W(Si) indicates the weight of Si;
i indicates the server selected last time, and i is initialized with -1;
cw is the current weight in scheduling, and cw is initialized with zero;
max(S) is the maximum weight of all the servers in S;
gcd(S) is the greatest common divisor of all server weights in S;
while (true) {
i = (i + 1) mod n;
if (i == 0) {
cw = cw - gcd(S);
if (cw <= 0) {
cw = max(S);
if (cw == 0)
return NULL;
}
}
if (W(Si) >= cw)
return Si;
}
Python版的实现:
class Store:
__slots__ = ('index', 'weight')
def __init__(self, index, weight):
self.index = index
self.weight = weight
def weighted(dataset):
current = Store(index=-1, weight=0)
dataset_length = len(dataset)
dataset_max_weight = 0
dataset_gcd_weight = 0
for _, weight in dataset:
if dataset_max_weight < weight:
dataset_max_weight = weight
dataset_gcd_weight = gcd(dataset_gcd_weight, weight)
def get_next():
while True:
current.index = (current.index + 1) % dataset_length
if current.index == 0:
current.weight = current.weight - dataset_gcd_weight
if current.weight <= 0:
current.weight = dataset_max_weight
if current.weight == 0:
return None
if dataset[current.index][1] >= current.weight:
return dataset[current.index][0]
return get_next
Dubbo还有另外两种负载均衡算法即最小活跃数以及一致性hash,感兴趣可以看源码,这里不再详细介绍了。
dubbo客户端通过watch注册中心的节点实现动态变化,此外支持不同方式的集群容错:
1)failover cluster模式(默认策略):失败自动切换,自动重试其他机器,常用于 读 操作
(2)failfast cluster模式(快速失败):一次调用失败就立即失败,常用于非幂等的 写 操作,比如新增一条记录(调用失败就立即失败)
(3)failsafe cluster模式(异常忽略):出现异常时忽略掉,常用于不重要的接口调用,比如日志记录
(4)failback cluster模式:失败后自动记录请求,然后定时重发,比较适合于写消息队列
(5)forking cluster模式:并行调用多个provider,只要一个成功就立即返回。常用于实时性要求比较高的读操作,但是会浪费更多的服务资源,可通过forks="2"来设置最大的并行数
(6)broadcacst cluster模式:逐个调用所有的provider。任何一个provider出错则报错。常用于通知所有提供者更新缓存或日志等本地资源信息。
Nginx负载均衡
之前写过一篇文章简要介绍了Nginx的高并发实现原理: Nginx实现高并发 。现在看一下其负载均衡。
Nginx主要对七层应用实现分流,配置非常简单。
upstream account_backend {
server 127.0.0.1:9090 max_fails=3 fail_timeout=10s weight=2;
server 127.0.0.2:9090 max_fails=3 fail_timeout=10s;
server 127.0.0.3:9090 max_fails=3 fail_timeout=10s;
}
上面Nginx会使用加权轮询,默认是1,Nginx会根据权重去选择对应server。该算法是Nginx默认算法。
Nginx还内置了ip hash算法,通过对客户端ip进行hash选择一个服务器,通过该方法可保证同一用户的可只打倒一个后端机器上。
upstream account_backend {
ip_hash;
server 127.0.0.1:9090 max_fails=3 fail_timeout=10s ;
server 127.0.0.2:9090 max_fails=3 fail_timeout=10s;
server 127.0.0.3:9090 max_fails=3 fail_timeout=10s;
}
当后端服务器集群中某个挂掉了,Nginx会自动将请求转到其他节点上。但是它默认是不会将该异常节点摘除,后续的请求还是可以打到异常机器上。至于这点,可以看这篇文章,该文章详细介绍了该如何进行后端健康检测的: Nginx负载均衡中后端节点服务器健康检查 - 运维笔记 ,主要说明了淘宝团队开发的模块,可以自动剔除异常的server。
其实可以看到Nginx的配置还是非常简单的,用起来很方便,目前几乎所有的业务系统都用Nginx,已经很少有用apache的了。
LVS负载均衡
上面所说的nginx已经具有良好的高并发性能,但是仍然存在着瓶颈,因此需要更优秀的负载均衡进一步提升性能。LVS是网络层的负载均衡,通过lvs可以对接N个nginx代理。
LVS相关的知识点可以参考本网站 LVS分类下的文章: LVS分类 。这里就不多说了。
LVS部署有以下几种模式:
1、单机模式,一个LVS对应多个Nginx server;
2、一主一备+KeepAlived,提高可用性;
3、集群模式。通过FullNAT+OSPF-ECMP,并使用一致性hash算法实现分流。
目前最多的就是集群部署方式,其特点为:
- LVS 和上联的三层交换机间运行 OSPF 协议。 OSPF 开放最短路径优先,一种常用的路由协议。
- 上联交换机通过 ECMP 等价路由,将数据流分发给 LVS 集群。ECMP充分应用在各大路由协议中,如OSPF,ISIS、EIGRP、BGP等。它可保证如果存在多条相等路径,会充分利用多条路由,从而实现基于流的负载均衡(如果不开ECMP,那么当选择一条路由后,或许都会一直使用该路由,其他相等路径都不会走)。
- LVS 集群再转发给业务服务器。
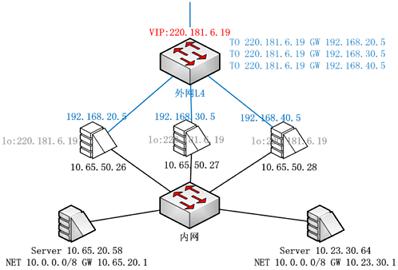
集群方式部署极大地保证了异常情况下,负载均衡服务的稳定性:
- 健壮性 :LVS 和交换机间运行 OSPF 心跳。1 个VIP配置在集群的所有 LVS 上。当一台 LVS 宕掉,交换机会自动发现并将其从 ECMP 等价路由中剔除。
- 可扩展 :如果当前 LVS 集群无法支撑某个 VIP 的流量,LVS 集群可以进行水平扩容。
DNS负载均衡
LVS作为一个server,当然其本身也会达到瓶颈,因此此时还有DNS负载均衡。简单说就是一个域名配置多个不同地理位置的ip,这个ip可以是LVS虚拟ip。
目前出名的DNS域名服务商都提供相应的功能,如dnspod。dnspod是个牛鼻的东西,我对其创始人吴洪声充满了钦佩之情,是个难得的天才。
其优缺点,我也是摘抄哦:
优点
- 基本上无成本,因为往往域名注册商的这种解析都是免费的;
- 部署方便,除了网络拓扑的简单扩增,新增的Web服务器只要增加一个公网IP即可。
缺点
- 健康检查,如果某台服务器宕机,DNS服务器是无法知晓的,仍旧会将访问分配到此服务器。修改DNS记录全部生效起码要3-4小时,甚至更久;
- 分配不均,如果几台Web服务器之间的配置不同,能够承受的压力也就不同,但是DNS解析分配的访问却是均匀分配的。其实DNS也是有分配算法的,可以根据当前连接较少的分配、可以设置Rate权重分配等等,只是目前绝大多数的DNS服务器都不支持;
- 缓存问题。一般低级DNS都会缓存域名IP映射关系,如果某个出现问题或者发生变化,不会及时更新。
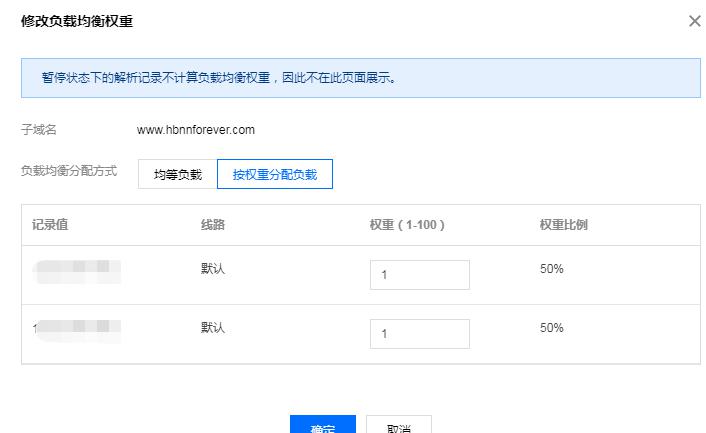
上面有一点说是默认简单轮询,现在的DNSpod,阿里云DNS解析都支持权重的配置。
下面是腾讯云DNSPod的一个实操:
参考资料:
微信分享/微信扫码阅读

