
Mysql复制
当一个企业发展变大,数据访问量增大,尤其并发量提升,QPS增加,这时底层数据库访问很有可能就会成为瓶颈,无论是IO密集型还是CPU密集型。那么为了避免Mysql成为系统的瓶颈,就应该有更好的策略提升读写性能。
目前比较成熟的方案有很多,包括Mysql主从复制,读写分离,Mysql cluster,Mysql InnoDBcluster。这几个都是从复制的角度出发。当然还包括数据库切分,比如水平切分,垂直切分。关于分库分表之前自己也写了两篇文章来介绍,分别讲述了分库分表思想以及Sharding-sphere的原理等等,可以在本网站上搜索。本文主要是记录对主从复制和读写分离的学习,以及Mysql InndoDBcluster的简单了解。
1、主从复制
Mysql的复制也是一个重点课题,其主要目的就是要提高可用性、实现负载均衡,分摊单台服务器压力、实现数据备份和容灾等等。
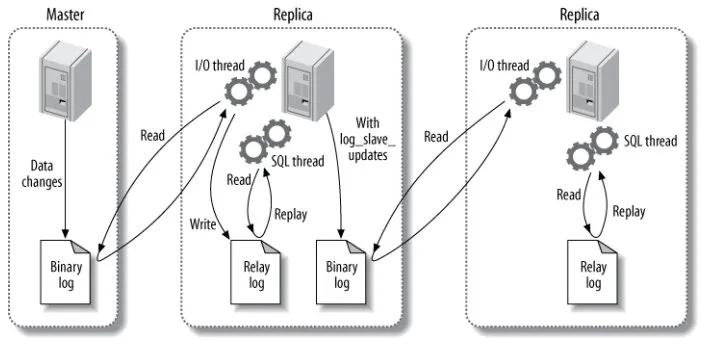
通常情况下复制指的是从主库到从库数据的复制,默认情况下是一个异步的过程。一般主要包括以下过程:
- 主库将数据更改记录到二进制文件binlog中;
- 备库开启一个IO线程,并在主库开启一个特殊的binlog dump线程,将binlog数据 拷贝到备库的中继log,relay log中;备库并不是不断轮询去做同步操作。而是当主库有数据更改时,会给主库发送一个信号量。主库返回的信息不仅仅有binlog内容,还有新的binlog文件名,它以及下一个更新的binlog文件的位置。
- 备库使用SQL线程读取中继log中的数据,并将其写入到备库数据中。
可以看一下slave的processlist:
ysql> show processlist\G;
*************************** 1. row ***************************
Id: 4
User: system user
Host:
db: NULL
Command: Connect
Time: 5205
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 5
User: system user
Host:
db: NULL
Command: Connect
Time: 5113
State: Slave has read all relay log; waiting for more updates
Info: NULL
*************************** 3. row ***************************
上面就是备库的两个线程,一个IO线程,一个SQL线程。
传统的Mysql复制是根据binlog的位置开始进行的,需要首先定位到对应位置进行处理,但自从5.6之后引入了一个叫GTID的概念。使用GTID,可以自动定位到GTID的位置,处理更方便快捷。
GTID,global transaction identifieds全局事务标识。这个标识是唯一的,它可保证一个事务只能被执行一次。其是由主机id以及自增id组成。
其工作原理如下:
1、当主库成功执行事务后,会将GTID(在事务执行前会自动生成)写入到Binlog;
2、主服务器将Binglog传入到从服务器的relay log,从服务器读取GTID,并将其设置为自己的GTID;
3、SQL线程从relay log中获取GTID ,然后和从服务器的GTID对比;
4、如果从服务器已经存在该GTID,则直接忽略;如果不存在,从服务器就会执行relay log中对应GTID的事务,并写到从服务器的binlog中。
我们可以查看当前Mysql是否已经开启了GTID。
mysql> show variables like "gtid_mode";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| gtid_mode | OFF |
+---------------+-------+
目前binlog的记录模式主要有三种,基于语句(statment),基于行(Row)模式,混合(mixed)模式。
基于语句的模式就是binlog记录的是所有可能影响数据变化的sql语句。然后在从库中再完全相同地执行一遍。这种模式比较好的地方是只记录语句,不用记录每一行的变化,数据量相对不大,节省带宽。比如一条批量update,只需要传一条语句,不用传每个更改的数据。但这种模式的缺点就是虽然主从库执行的sql完全相同。但主从库的上下文环境是不同的,而sql可能是严格依赖于环境的,比如当前时间戳等等。
基于行的模式,是记录被修改的数据,而不是sql语句。这种模式使得从库并不会因为环境不同,导致数据不能完全一致。但基于行的模式,可能会导致binlog的数据量特别大,就像上面说到的update,可能会在binlog产生更多的数据记录。这给复制造成了更大的开销。
mix模式,该模式是上述两种模式的组合。Mysql会根据实际的sql来决定选择哪个模式进行写入。
复制拓扑
复制的结构有很多中,一主多从,主-主,主-分发主-从库等等。但我感觉目前用的最多的应该是一主多从。但有时如果因为从库过多可能使得数据同步过程导致数据库性能下降,可以增加一个分发库。用了这个分发库之后,只有该分发库负责同步主库的数据更改,其他从库是直接从分发库上进行同步,好比找了一个缓冲。
复制过程中,可能遇到的问题,我就不写了,直接高性能Mysql弄了。

上面我觉得主从延迟是非常非常常见的,我之前也是在工作中遇到了很多次,因为瞬时数据量的变化很大,导致主库到从库的同步出现了延迟。而导致查询时从库还未包括更改后的数据。是否有延迟可以通过查看slave的状态。下面有一个Seconds_behind_master。它是通过比较IO线程事件的事件戳和SQL线程的事件事件戳得到的。当为0时,就证明同步非常OK。
************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.17.0.2
Master_User: root
Master_Port: 3306
Connect_Retry: 30
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 966
Relay_Log_File: 081accebd554-relay-bin.000002
Relay_Log_Pos: 1132
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 966
Relay_Log_Space: 1346
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 4ad460c2-11ea-11eb-94fe-0242ac110002
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
因为各种原因可能导致主从数据不一致的问题。如果相差不大,且对一致性要求不高的情况下,可以继续开启主从复制。但实际上,我们都是要求主从必须严格一致。所以就要想办法去解决主从不一致的问题。
一个简单有效的方法就是先将主库的所有表锁住, flush tables with read locks,然后通过Mysqldump导出所有的sql文件,在从库执行。
2、读写分离
读写分离的意思是主库只负责写,从库只负责读,这样可以一定程度提升Mysql的性能。一般读写分离都是通过中间件的实现的,目前流行的有很多,比如Kingshard,小米的gaea,阿里的mycat等等。laravel也简单实现了读写分离功能。说实话,实现读写分离这个功能还是比较简单的。基本思想就是通过解析查询语句,来决定是否连接主库还是从库。
之前写了Kingshard的选择主从库的逻辑,比较简单,感兴趣的可以看: Kingshard中间件 。
本文再简单说说laravel的实现,其他的诸如mycat等等,还包括分库分表等等,功能很多,这里就不说了。
laravel创建一个PDO链接是通过ConnectionFactory来实现的,类似一个工厂方法,PDO是laravel和底层数据库连接和通信的接口,底层可以是Mysql,Sqlite等等类型的数据库。当我们在数据库配置文件中分别配置了读写数据库,那么在建立链接时,会建立一个读写链接,源码:
public function make(array $config, $name = null)
{
$config = $this->parseConfig($config, $name);
if (isset($config['read'])) {
return $this->createReadWriteConnection($config);
}
return $this->createSingleConnection($config);
}
protected function createReadWriteConnection(array $config)
{
$connection = $this->createSingleConnection($this->getWriteConfig($config));
return $connection->setReadPdo($this->createReadPdo($config));
}
protected function createReadPdo(array $config)
{
return $this->createPdoResolver($this->getReadConfig($config));
}读写链接的建立过程是,它首先会建立一个写库的链接,然后再建立一个读库的PDO闭包。
闭包如下:
protected function createPdoResolverWithHosts(array $config)
{
return function () use ($config) {
foreach (Arr::shuffle($hosts = $this->parseHosts($config)) as $key => $host) {
$config['host'] = $host;
try {
return $this->createConnector($config)->connect($config);
} catch (PDOException $e) {
if (count($hosts) - 1 === $key && $this->container->bound(ExceptionHandler::class)) {
$this->container->make(ExceptionHandler::class)->report($e);
}
}
}
throw $e;
};
}
好了,上面把一个读写链接建立好了,接下来是针对不同的SQL动态的选择读库还是写库。
先看以下select查询方法:
public function select($query, $bindings = [], $useReadPdo = true)
{
return $this->run($query, $bindings, function ($query, $bindings) use ($useReadPdo) {
if ($this->pretending()) {
return [];
}
// For select statements, we'll simply execute the query and return an array
// of the database result set. Each element in the array will be a single
// row from the database table, and will either be an array or objects.
$statement = $this->prepared($this->getPdoForSelect($useReadPdo)
->prepare($query));
$this->bindValues($statement, $this->prepareBindings($bindings));
$statement->execute();
return $statement->fetchAll();
});
}
//这里决定了是选择主库,还是从库,使用useReadPdo,select默认是true。如果想读主库,可以显示传入false
protected function getPdoForSelect($useReadPdo = true)
{
return $useReadPdo ? $this->getReadPdo() : $this->getPdo();
}如果是当前连接存在事务,即这是一条在事务中的读库,也会强制使用主库。this->transactions这个变量是每增加一个事务就会+1。
public function getReadPdo()
{
if ($this->transactions > 0) {
return $this->getPdo();
}
if ($this->getConfig('sticky') && $this->recordsModified) {
return $this->getPdo();
}
//如果是闭包函数,执行必包函数
if ($this->readPdo instanceof Closure) {
return $this->readPdo = call_user_func($this->readPdo);
}
return $this->readPdo ?: $this->getPdo();
}其他的类似insert,update,delete都会直接就使用写库连接。
最终都会调用:
$statement = $this->getPdo()->prepare($query);
上面就是laravel实现读写分离的一个基本过程。此外,读库和主库也可以配置多个。laravel每次会随机选择一个连接,也是一种负载均衡的实现。
不过laravel的这个实现比较简单,像Kingshard等实现的都是相对功能较多的,比如黑白明单等等。但Kingshard等都是以中间件的形式需要单独部署的。
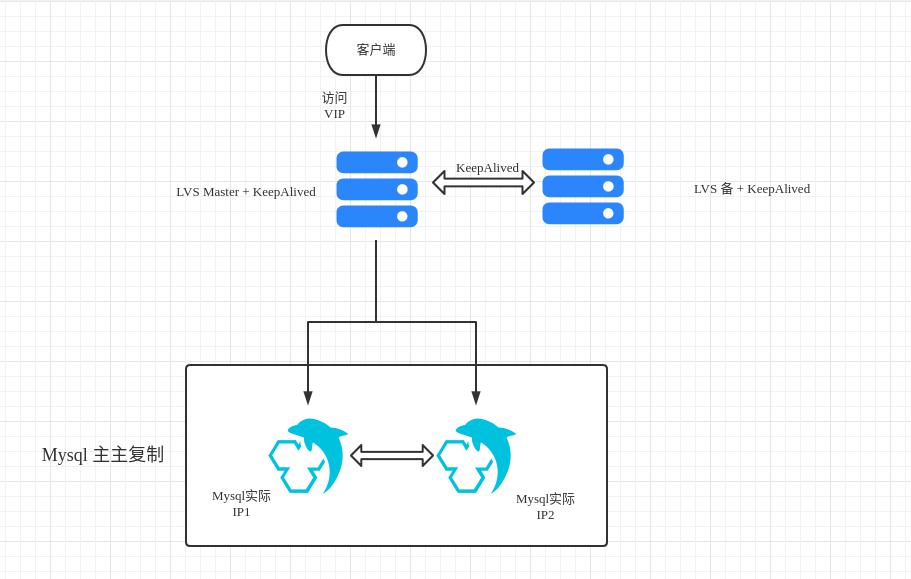
在上面只是介绍了主从复制以及读写分离,其实在实际应用中,为了提高可用性和负载均衡,Mysql架构比较复杂。目前很多都使用Mysql+LVS+KeepAlived来实现。一般复制拓扑结构都是主主复制。
LVS主要是用来实现负载均衡的。
Keepalived的作用是检测服务器的状态,如果有一台服务器宕机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其它服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器。关于这方面感兴趣的可以参考下面的资料。
下面就是一个简单的示意图,实际上要比这个复杂。比如可以多个master,多个slave。那样可能就要引入一个中间件,来实现读写分离,分库分表等等。
参考资料:
keepalived+LVS使用两台机器实现mysql双主负载均衡高可用实践
微信分享/微信扫码阅读

