
Mysql分库分表之理论学习以及sharding-jdbc使用
由于单表数据的不断在增长,达到了Mysql单库单表的理论最大值,考虑到数据过多对Mysql操作性能的影响,需要通过分库分表解决性能瓶颈。
分库 、分表,虽然本身都是为了解决单库单表的性能瓶颈,但两个有着完全不同的侧重点。
分表主要侧重点将一个表根据某种规则拆分为多个表,虽然没有破坏事务等操作,但其还是没有根本解决单个库的性能瓶颈。
分库,一般都会将数据分散到多个Mysql库中。但对于分布式系统来说,最大的问题还是跨库事务的复杂度。如果一定要实现事务,就需要使用分布式事务或者类似弱事务去实现。
另外一个问题是,对于分布式系统,如何保证id的唯一性,这个是关键。之前自己也写过文章,阐述了分布式系统如何保证全局ID的唯一性。比如SnowFlake算法,美团的Leaf,百度的UIDGenerator等等。
分库分表的划分方式有垂直划分和水平划分。
垂直划分也有分库和分表两个维度。分表就是将一张表根据某种规则,将多个字段分成几组放到不同的表里面;分库可以根据业务将数据表划分到不同的库中,比如商品一个库,订单一个库,优惠一个库。
水平划分就是将数据根据某个唯一建,根据某种规则划分到不同的表(或库)中,比如用户id,设备id等等。
垂直划分这个虽然将某个数据表的字段拆分存储,但其本质上并没有解决单表数据过大的情况。目前采用比较多的方式就是水平划分。比如一个用户已领取用户券的数据表。可以根据uid,进行hash取模。类似Redis Cluster的slot。一般Redis Cluster有16384个slot,key的分配算法是 CRC16(key)& 16383,计算获得0~16383中的某一个slot值。
比如有64个库(或者表),可以根据 uid % 64 进行hash取模后,分配到指定的数据表中。
目前市面上比较好用的分库分表的中间件挺多的,比如Mycat,Sharding-JDBC等等。Mycat是一种完全中间件形式的应用,单独部署,客户端访问通过Mycat;Sharding-JDBC是一种应用层面的代理,代码侵入较多。像这种框架一般都内置了分布式唯一键的生成以及分布式事务,但一般都采用当前比较流行的。比如Sharding-JDBC的分布式事务可以使用阿里的seata实现。
下面是网上找的一个对比图,目前大公司的一些成熟产品。
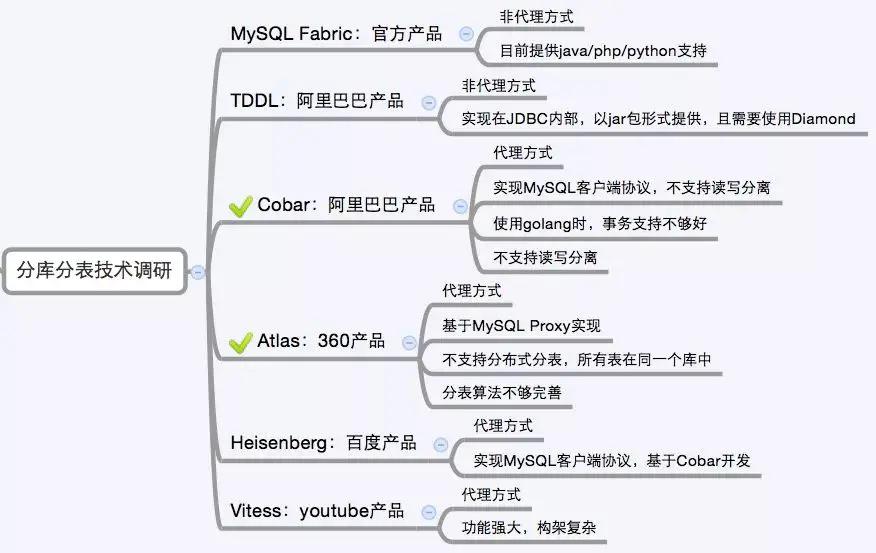
Mycat这个是阿里的产物,功能非常强大,这也让其系统相对比较复杂。目前有个个人开发的Kingshard也很火,小米的Gaea就是基于Kingshard和Mycat开发的。但Kingshard目前来看最大的问题是不支持分布式事务。Sharding-JDBC和上面的都不同,它是在业务层实现浸入,不是中间件模式,只要引入jar包,进行相应配置和开发即可。当当网虽然公司很烂,但这个产品的确挺牛逼的,已经是Apache的孵化项目了。
我主要要学习的是Sharding-JDBC实现分库分表。最开始可以只学习分库,比如将一个数据表的数据分到64个数据库中,至于某个用户的数据落到哪个数据库上,就根据取模即可。
-----------分割线 2020.08.28-----------------------
今天实践了一把sharding-jdbc,说实话,官网的例子并不是特别清晰,而且针对不同的版本,可能所使用的配置格式也不尽相同。昨天在实践的过程也是遇到了各种坑,当然这其中也有自己还不是特别熟悉的缘故。还好,最后调通了。这里简单记录一下使用过程。
1、首先是引入依赖。我使用的是springtboot,所以就直接用springboot集成的依赖包了。不过完全可以直接用shardingsphere的原官网包。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>4.0.0-RC2</version>
</dependency>
第一个druid,应该都很熟悉了,注意这里不要用springboot集成的版本。 shardingsphere使用的是4.0.0,我测试的这个时候,已经有了4.1.1的版本了,但是用最新版本的时候,使用最新配置没有成功,后续我再试试。
2、配置
spring:
......
shardingsphere:
#这个地方,表示是否打印出具体的sql
props:
sql:
show: true
#多个数据源,要在这里配置。我使用的是Druid的Datasource
datasource:
names: hbnnmall0,hbnnmall1
# type: com.zaxxer.hikari.HikariDataSource
//我这是一个数据库配置一次,好像应该还有更简单的配置方法。要不然如果分了64个库,那每个都配置也不现实。
hbnnmall0:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://10.123.8.8:3306/hbnnmall?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.jdbc.Driver
username: admin_wr
password: 44646664
filters: stat
maxActive: 100
initialSize: 1
maxWait: 60000
minIdle: 1
timeBetweenEvictionRunsMillis: 600000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxOpenPreparedStatements: 20
mybatis.configuration.map-underscore-to-camel-case: true
hbnnmall1:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://10.6.7.8:3306/hbnnmall2?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.jdbc.Driver
username: admin_wr
password: 355464
filters: stat
maxActive: 100
initialSize: 1
maxWait: 60000
minIdle: 1
timeBetweenEvictionRunsMillis: 600000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxOpenPreparedStatements: 20
mybatis.configuration.map-underscore-to-camel-case: true
//这里就是分片的规则了。包括分库和分表。
sharding:
//这里指定了默认的数据库,如果不进行分库分表的,就需要使用默认的数据库了
default-data-source-name: hbnnmall0
//这配置的是数据库的分片算法,mod 2.
default-database-strategy:
#行表达式
inline:
//分片的列
sharding-column: gid
algorithm-expression: hbnnmall$->{gid % 2}
//涉及到的数据表
tables:
shop_good:
//实际的数据节点,hbnnmall0,hbnnmall1就是上面配置的datasource
actual-data-nodes: hbnnmall$->{0..1}.shop_good
//这是key生成策略,可选择snowflake.
# key-generate-strategy:
# column: id
# key-generator-name: snowflake
配置完成之后,其实改动就完成了,调用dao层,还和之前的使用方式一模一样,完全没有任何其他的改变。
打印的一个sql实例:
首先启动一个项目时,就会看到你配置的sharding规则:
c.a.d.p.DruidDataSource {dataSource-1} inited [DruidDataSource.java : 994] [INFO ] [main]
c.a.d.p.DruidDataSource {dataSource-2} inited [DruidDataSource.java : 994] [INFO ] [main]
o.a.s.c.c.l.ConfigurationLogger ShardingRuleConfiguration
defaultDataSourceName: hbnnmall0
defaultDatabaseStrategy:
inline:
algorithmExpression: hbnnmall$->{gid % 2}
shardingColumn: gid
tables:
shop_good:
actualDataNodes: hbnnmall$->{0..1}.shop_good
logicTable: shop_good
[ConfigurationLogger.java : 134] [INFO ] [main]
o.a.s.c.c.l.ConfigurationLogger Properties
sql.show: 'true'
现在执行一个sql,查询gid=88889的数据,
ShardingSphere-SQL Rule Type: sharding [SQLLogger.java : 99] [INFO ] [main]
ShardingSphere-SQL Logic SQL: select * from shop_good where gid=? [SQLLogger.java : 99] [INFO ] [main]
ShardingSphere-SQL SQLStatement: SelectSQLStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.SelectStatement@57d8d8e2, tablesContext=TablesContext(tables=[Table(name=shop_good, alias=Optional.absent())], schema=Optional.absent())), projectionsContext=ProjectionsContext(startIndex=7, stopIndex=7, distinctRow=false, projections=[ShorthandProjection(owner=Optional.absent())], columnLabels=[gid, spu_id, cid, new_cid, backend_cid, type, name, summary, pic_id, album, price_min, inventory, saled, saled_fee, utime, ctime, evaluate_avg, post_desc, desc_img_list, intro, techspec, pack_list, intro_ext, details_id, tag_filter, comment_count, market_price, order_overdue, share_descr, attr_ext, is_custom, sale_mode, lv1cid, edit_complete, primary_pid, tv_album, tv_intro_ext, img800, img800s, img_square, img_horizon, consignor, after_sale_agent, customer_service_agent, img_safe_area, img_safe_area_url, platform, status, source, display_order]), groupByContext=org.apache.shardingsphere.sql.parser.relation.segment.select.groupby.GroupByContext@2f726cf4, orderByContext=org.apache.shardingsphere.sql.parser.relation.segment.select.orderby.OrderByContext@514eefc4, paginationContext=org.apache.shardingsphere.sql.parser.relation.segment.select.pagination.PaginationContext@4700db93, containsSubquery=false) [SQLLogger.java : 99] [INFO ] [main]
ShardingSphere-SQL Actual SQL: hbnnmall1 ::: select * from shop_good where gid=? ::: [88889] [SQLLogger.java : 99] [INFO ] [main]
再执行一个gid=88888的数据查询。
ShardingSphere-SQL Actual SQL: hbnnmall0 ::: select * from shop_good where gid=? ::: [88888] [SQLLogger.java : 99] [INFO ] [main]
现在已经实现了分库,再来一个分表的。其实主要是配置的改变。
基本数据源配置不再赘述,主要是分片。
sharding:
default-data-source-name: hbnnmall0
default-database-strategy:
inline:
sharding-column: uid
algorithm-expression: hbnnmall$->{uid % 2}
# binding-tables: shop_good
# broadcast-tables=t_address
tables:
# shop_good:
# actual-data-nodes: hbnnmall$->{0..1}.shop_good
# key-generate-strategy:
# column: gid
# key-generator-name: snowflake
user_coupon:
table-strategy:
inline:
sharding-column: oid
algorithm-expression: user_coupon_$->{oid % 2}
actual-data-nodes: hbnnmall$->{0..1}.user_coupon_$->{0..1}
#分布式主键生成类型。目前有雪花和UUID
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 123在插入的时候要注意,不能设置自增主键类型,否则ShardingJDBC的年主键生成就失效了。至少我用的这个版本是出现这种问题的。
接下来要考虑的是跨库的分布式事务等问题了。
总结:虽然可以轻松实现分库分表,但考虑到分库分表可能带来的各种问题.如果不到了非分不可的地步,尽量部分.或者可以简单分表或者单库.意思就是尽量简化系统的负责度,降低问题发生的概率等等.
。。。。。2020.10.20.。。。。。。。
在商品搜索中,加入了一层查数据库全文索引,突然发现,Sharding-JDBC未能正确解析对应语句。
比如:
select gid from shop_good where MATCH(name) AGAINST('${searchName}' in boolean mode)
使用Sharding-JDBC抛出了异常,后来取消了Sharding-JDBC恢复正常。
参考资料:
微信分享/微信扫码阅读

