
记录一下我们最近在压测过程中调优的过程
一、项目背景
先说下项目背景,我们要为某个项目组开发一个联机交易平台,联机交易在金融业是比较常见的概念,实际上就是分布式系统调度,只是对每一个微服务是有规范的。作为联机交易平台,所有交易都会走我们的系统,因此对性能、可用性等都有严格的要求。
由于我之前接触了很多公司的实际生产事故复盘(之前也发了一篇复盘相关的文章,感兴趣的可以查阅),所以我也要求我们所有项目组成员都要注意自己平时的代码开发,我也会不定期的Review他们的代码,但有时比较忙,没有太多经历看他们代码。上周我们项目开发得差不多了,所以我就组织了一次内部的压测,总结来看,4天的压测与调优过程是个不错的经历,发现了代码的很多问题,我自己对最后的压测结果还是非常满意的。
二、压测环境
1、应用服务,单点压测。8c16G,但已经有7G内存被用了,服务器有其他很多服务;
2、RedisCluster集群,三主三从,部署在两台服务器上,每台服务器是32c64G;
3、Postgres,四个子库,部署在两台服务器上,和上面的Redis服务器共用;
4、原子交易服务,和应用服务在同一个网段,同一个机房,不在同一台机器上。
简单的架构如下:
我们压测的联机交易比较简单,规则是串行调用两个原子交易节,这里再多说一句,我们提供了交易编排能力,即不用自己开发,只需要根据注册的原子交易节点完成在线服务编排,就能生成一个联机交易规则。
上图的事务日志存储策略指的是联机交易平台需要对交易进行分布式事务处理,采用SAGA模式,事务管理需要存储交易流水,平台提供上述三种策略,我们分别对这三种策略进行压测。
三、准备工作
压测环境的准备还是很重要的,如网络问题、机器配置等很多因素都可能干扰我们的压测结果,准备工作就是要尽量优化硬件和软件配置,使得压测结果更多的能反应应用本身的性能。我准备了如下几点:
1、所有涉及到的服务器在部署之前,都要Ping一下看一下本地网络到服务器的时延,是否满足需求。这点要说一下我们压测机是本地,我们会ping 本地到应用Server的时延,也会ping应用Server到Redis、PG以及原子交易服务的时延,基本上都是3到7ms之间;
2、所有Linux服务器要检查系统和用户级别的文件数打开限制,ulimit -n 可以看到,我们现在是65535,是OK的;
3、联机交易Server的日志级别调整成info,logback使用异步Appender,并且队列设置不阻塞。这个地方很重要,之前在复盘公司生产事故时,就出现了一个因为日志频繁的写入导致交易成功率很低的问题;
4、联机交易Server关闭所有定时任务。我们有一些事务的异步补偿任务,会轮询数据表。我们把这些暂时先关了;
5、检查TCP配置是都打开Socket端口重用等配置,TCP半连接队列配置。实际上会与服务器,如果不是SYN Flood,只是简单压测,这些配置可能不需要动。但如果压测的并发量还是很大的话,如果没有开KeepAlive,会出现大量的短连接,会出现频繁的TCP的建立和释放,当系统出现大量的Time_Wait状态的连接,会非常影响性能的。这个问题在使用Nginx做反向代理的时候经常出现。所以我们如果使用Nginx的时候都会把KeepAlive开关打开,配置header的Connection为非 close和Version配置成1.1;
6、JVM配置,采用G1收集器,最小堆、最大堆配置成4G,直接内存配置成1G;
7、Jmeter压测工具勾选 Use Keep Alive;
8、联机Server 部署arthas,attach到联机Server pid上;
9、本地打开JVisualVM,添加JMX连接到联机Server;
四、压测分工
1、一个人负责监控 JVisualVM 和arthas;
2、一个人负责使用jstat -gc pid 1000 查看 GC 的具体情况;
3、一个人主要监控TCP连接情况。我也写好了命令给他们, netstat -an|awk '/tcp/ {print $6}' | sort |uniq -c;
4、一个人负责发压,统计压测结果。
五、压测过程
1、发现线程数达到2万多
我们首先压测的是直接使用内存存储的策略,但刚开始压就是当头一棒,jmeter统计的TPS一直维护在几十,这特么不是扯淡吗?这是啥玩意?
我看了一下jvisualvm,发现了两个很大的问题,一是堆空间占用很大,二是已启动的线程数非常多,快到3万个了。很遗憾,当时的记录我没有截图,这里截图一个我们现在的(我们开发机器的文件不允许弄出来,只能拍照了,但我拍的都是看不到实际业务的,不是泄密哈),已经调优过的。这个应用已经运行7天了,所以你看已启动线程数时1千多。实际上运行的只有几百个。
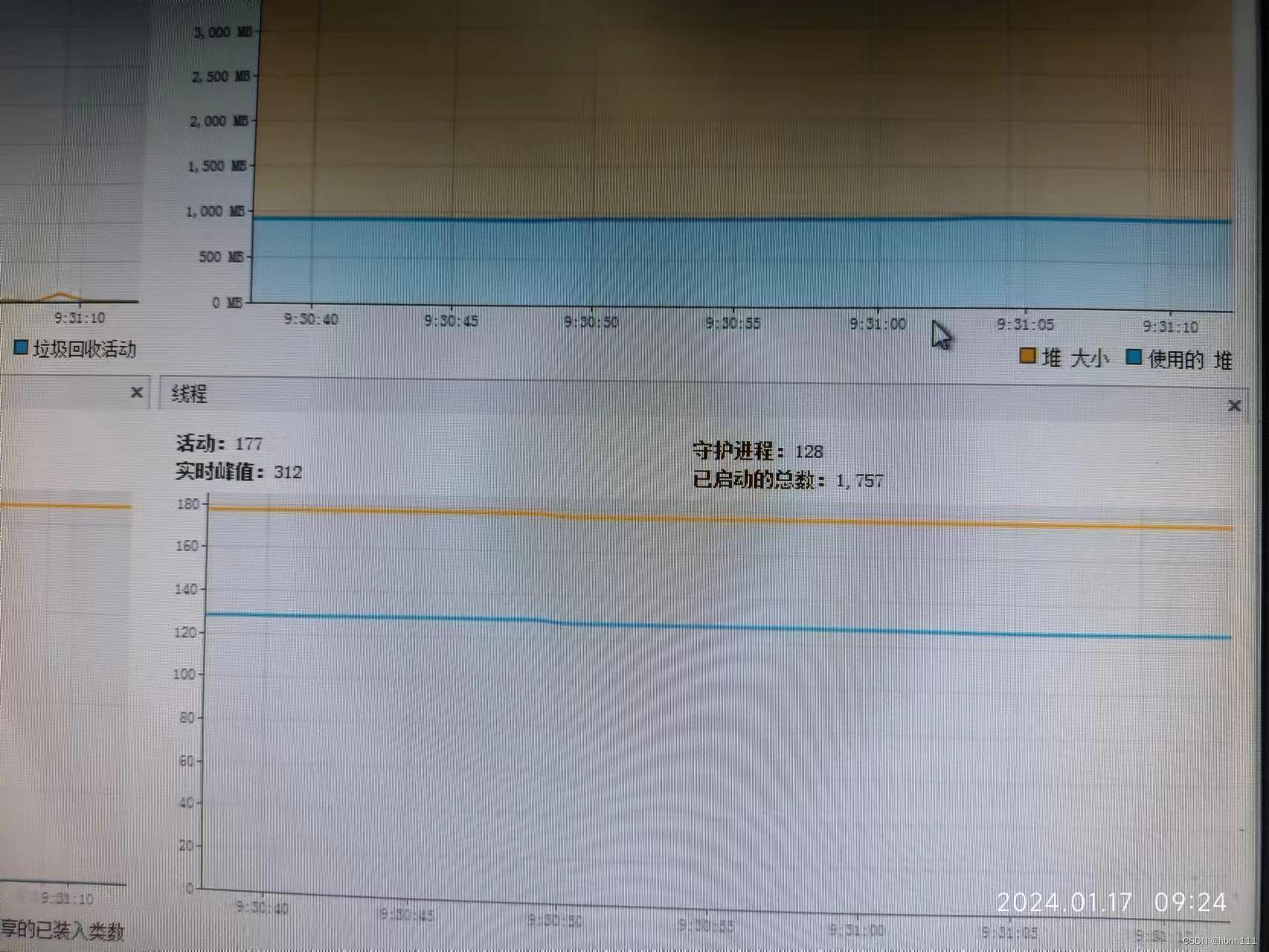
在这个步骤中,我都没时间理会堆空间的问题,先处理线程数的问题。因为整个系统都是我设计的,所以我对每个地方基本上都是很清楚,在内存存储的策略下,能占用这么多线程的只有远程调用原子交易这个步骤了,我们目前是通过http协议调用(同样支持dubbo等协议,只是先拿http压),肯定是使用http客户端时没有设置连接池或者最大线程数没有限制。
于是乎,我让我们组内的小伙伴排查发起HTTP调用的HttpInvoker类有没有问题,果然,一查就发现了没有使用连接池,马上改了代码,加了http连接池的配置,把最大连接数加到60了,我认为已经够用了。
改好之后,线程数立马就下来了,TPS也瞬间上去了。
2、堆使用空间越来越多
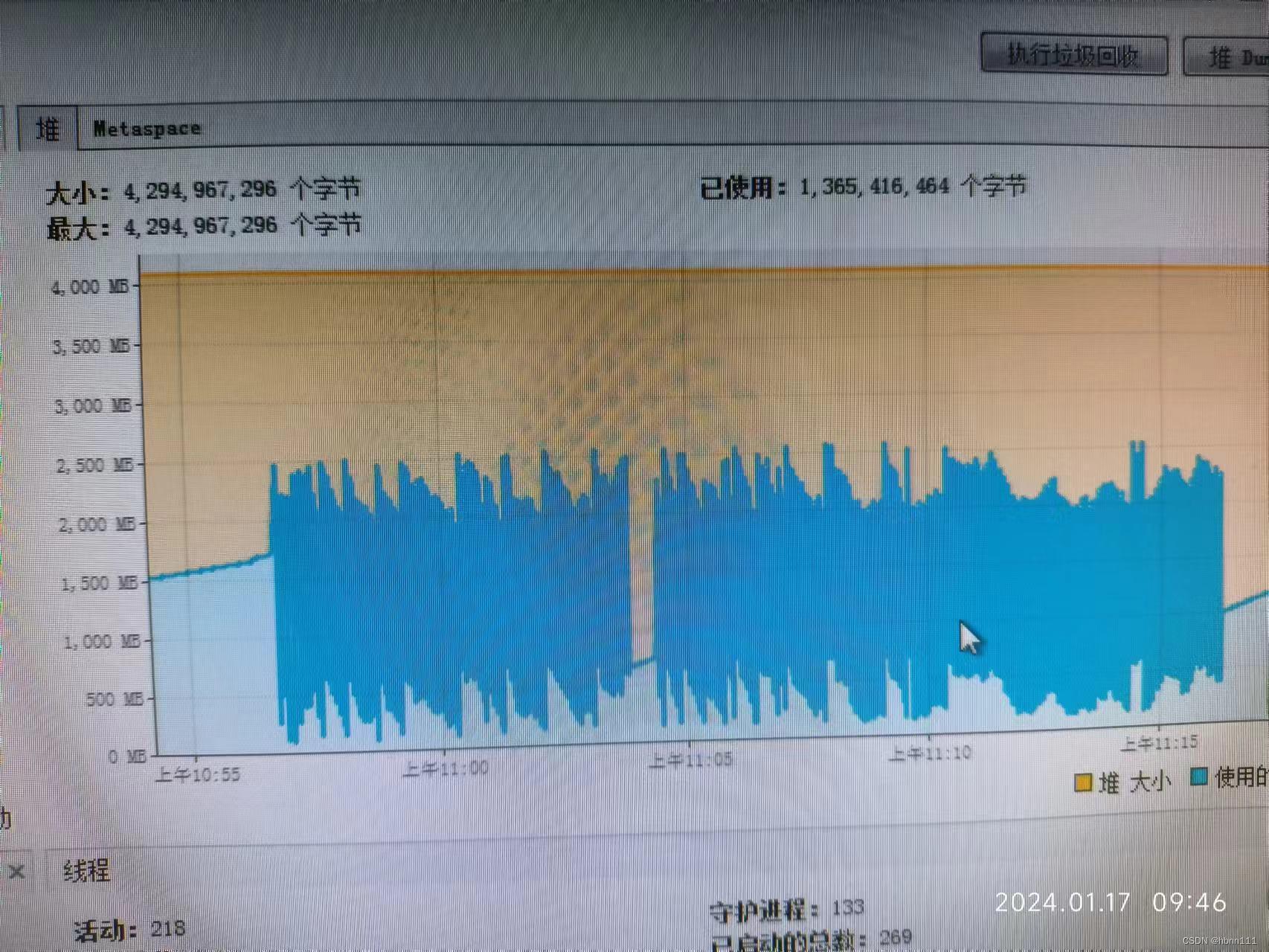
内存策略下,堆使用空间越来越多,是可见的上涨,4G的堆空间很快就打满了,看jstat统计会看到就那么一小会儿,FGC都11次了,而且很短的时间内都会发生一次FGC,我勒个去。更可怕的是,压测都停了,还是长期不回收。这里我已经断定一定是出现内存泄漏了,因为我们内存策略是使用两个ConcurentHashMap存储事务流水,我当初设计的是事务达到终态后,会发送一个事件,Listener会异步删除。所以我猜没有删除成功。
由于负责这块儿的小伙伴当天没在,我就看了一下代码,乍开始看有删除动作啊,没问题啊。我先是写了一个定时,使用的是newSingleThreadScheduledExecutor,每隔15秒监听一下这两个map的size,我就idea debug启动了代码,在删除的动作那儿加了断点,我发了一笔交易请求,走到断点一看的确也走到这儿了,这时我是没发现问题的,就把整个交易请求走完了。这时看上面定时输出的日志的map size是1,即结束后的确是没有删除成功的。
那么问题来了,已经走到删除的方法了,但实际上没有删除成功?这个现象的一个唯一可能只能是,写的key和删除的key不是一个。于是乎我又debug启动发了一次请求,通过断点发现,果然写入的key和删除的key不是一个,写入使用的是流水号,删除的key使用的是全局业务跟踪号。晕。。。。我赶紧改了代码,本地测试 交易结束后, map size变成0了。
再次压测,看到堆空间使用维持在50%以下,瞬间就舒服多了。下面的图片是我们现在的。
3、内存策略存在阻塞线程, thread -b
实际上,上面两个问题解决后,好了太多了,但我总觉还差点儿意思。于是我就用arthas开始看线程,arthas是阿里开发的,可以看到线程的状态、CPU使用率。thread -b命令可以看到当前阻塞的线程。
唉呦嘿,不查不知道,一查吓一跳。发现某个线程阻塞在load class的地方。看堆栈信息定位到代码里有一个地方是加载SPI实现类。我们有个场景是联机交易允许项目组对响应进行扩展,即在生成响应过程中埋入了钩子函数,通过SPI的方式实现的,引擎会自动加载所有SPI实现类。
代码里的问题在于每次构造响应的过程中,都会load一次,这不是扯呢吗?每次load都会有全局锁的,怪不得会阻塞。实际上只需要加载一次就可以了,设置一个静态变量即可。改了之后,立马舒服了。这里要要说一下,arthas真香!
4、分布式锁调优
我们现在有一个功能是为了保证幂等性,如果同笔交易在处理中,新到来的会被拒绝,这是通过分布式锁实现的,保证集群环境的幂等。就是这个功能极大影响性能,每次交易都会申请和释放Redis锁。另外一个潜在的重要问题是,交易100%依赖Redis,这就导致Redis如果出现问题了,就全挂了,存在一定的隐患的。
我给我们的小伙伴提供了一个思路,把这个分布式锁拿掉,因为我们在交易开始时,会写一笔组合交易流水到存储中,PG和Redis两种策略都可以天然的避免重复的问题。没必要在一开始就使用分布式锁保证。
但问题又来了,如果我们使用内存临时存储策略,怎么保证幂等性呢?如果是单点服务就好解决了,直接控制ConcurrentHashMap的写入,那集群场景下该怎么保证呢?坦诚讲,如果不用分布式锁是保证不了的,可就算用分布式锁,你也只能防止同时进行中的交易的重复,如果前一笔交易已经执行完了,后一笔交易如果是重复的,还是保证不了幂等性的。也就是说,做分布式事务管理使用内存就不是好的方案,所以目前的机制是干脆取消掉全局锁,这种情况不处理,后续再酌情考虑内存策略下的幂等问题。
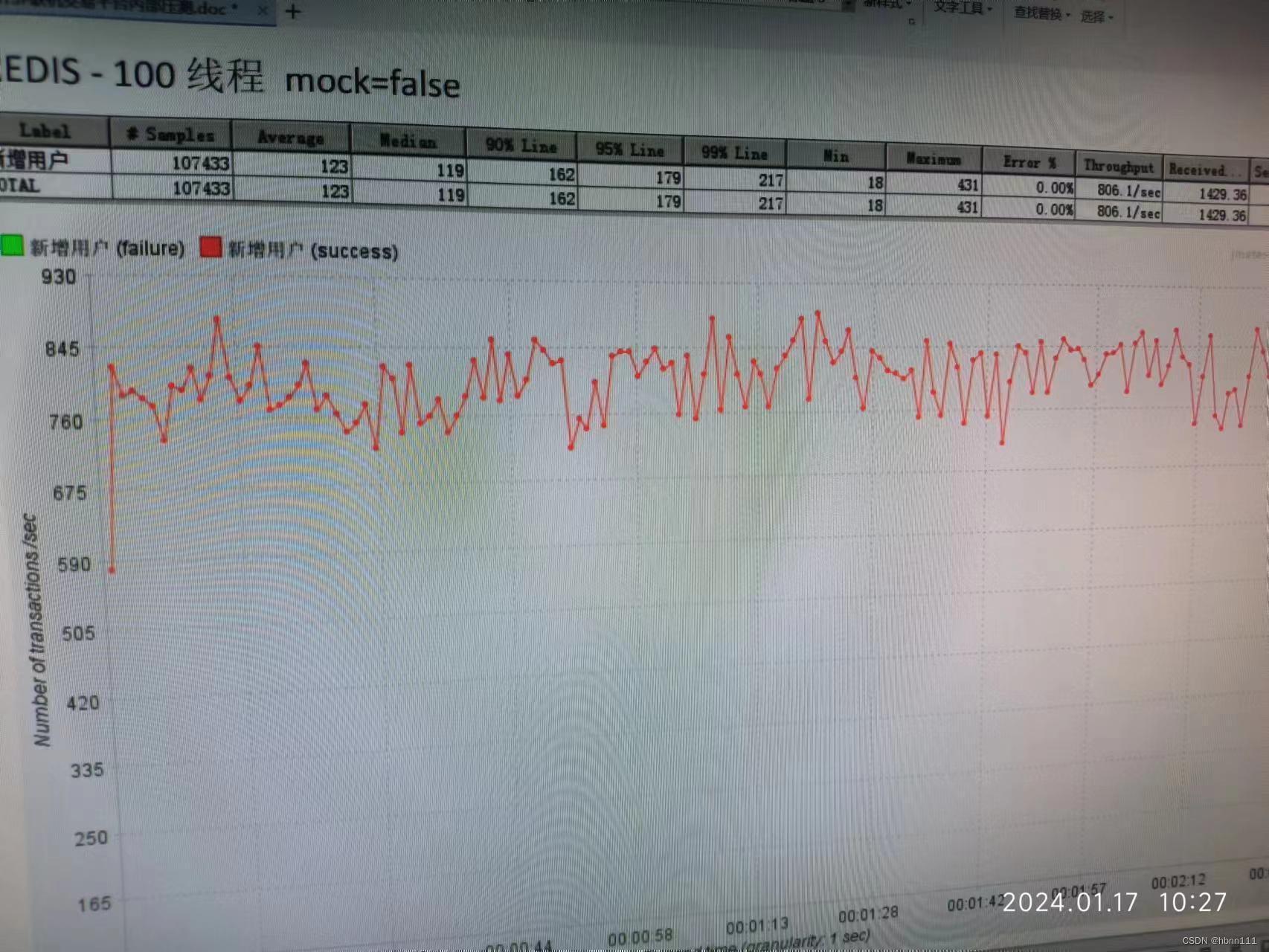
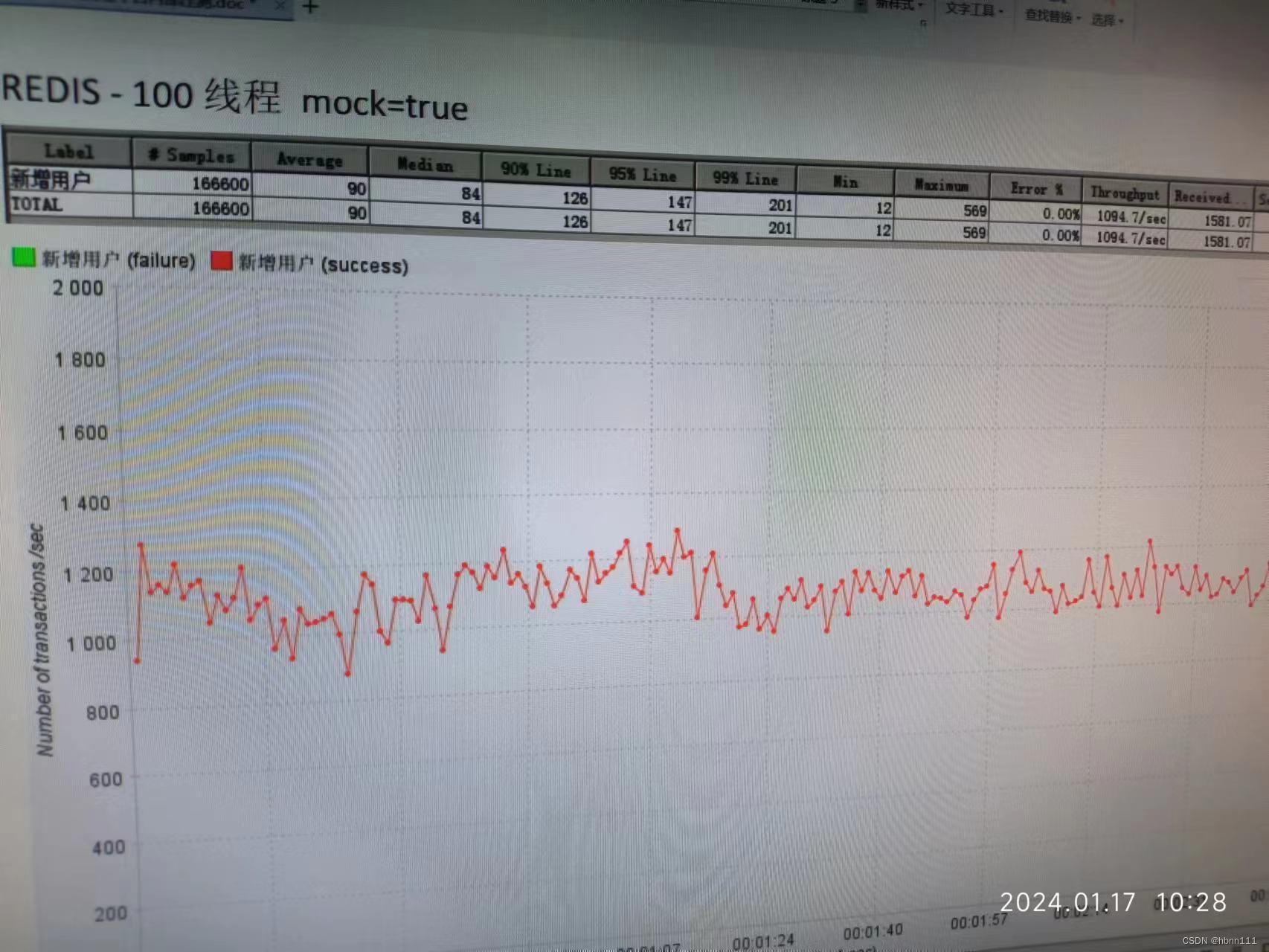
5、Redis压测结果竟然不如PG
当我看到这个结果,我头都大了,上面的问题基本上都是我排查出来的,压到Redis的时候又出现这个现象,我真是有点郁闷了。
我赶紧让组内的小伙伴排查Redis策略类写的是否有问题。如果Redis压测结果不如PG只能证明,Redis策略写的太烂了。我之前参加过的复盘中就有因为Redis的大key,热点key问题导致出现系统崩溃的。我让小伙伴排查一下是不是每笔交易操作的key太多了,或者有没有大key出现。
经排查发现, Redis策略中一次交易涉及多次key的操作,且存在一个大key ,有序集合,用于存储每笔交易的全局业务跟踪号,即每笔交易都会写入。首先,有序集合是跳表的数据结构,频繁的写入也会影响性能,尽管Redis的skiplist每次插入是随机选择一个层数插入,但频繁插入还是很差。另外,我们为了大key,每次数量达到5000就会拆跳表,把数据分到新的集合中。总之,这本身是一个非常耗时的操作,最后我们的队列没有删除操作,队列数量只会越来越多。我们都知道Redis的命令执行是单线程的,对集合的操作势必会影响到所有的Redis操作。
我们的解决方案是把有序集合干掉,不用了。我们做集合是为了后续的遍历轮询交易,可本身Redis是key-value,还要强制做PG的范围查询,就没必要了。所以,就暂时干掉了。
干掉之后,Redis策略的压测结果就立马上来了。
六、总结
这次压测、调优的过程非常有趣,发现问题、排查问题、解决问题这一整个过程真是收获满满。当你看到压测结果通过调优后性能有明显的上升后,还是非常有成就感的,这也是属于我们技术人的一种小幸福吧。
最后想说,永远不要轻视测试,包括单元测试,集成功能测试,压力测试。
微信分享/微信扫码阅读

