
爬虫模拟登录
模拟登录这块我本来试着scrapy,但是我觉得真得号不灵活,倒腾了半天,也不行。后来还是用了我之前写的代码,用requests模块模拟。requests模块特别好用,比urllib2以及其他的都好用(至少我是这么觉得地)。
模拟登录其实主要掌握了几点,就很好下手。
- 要抓住真正要登录的URL;
- 要拿到要post的表单数据Form data,一般是以字典形式;
- 填写好header,有的网站可能会认证User-Agent,Host,Referer等等请求头。
下面就来逐步说说我写模拟登录的过程。 想要拿到上面说到的数据,应该抓包分析,可以直接使用火狐的firebug插件或者chrome浏览器直接分析。
目标网站:http://zhixing.bjtu.edu.cn/portal.php
先打开分析工具,自己填写账号信息,登录。注意,分析工具要设置保存log ,因为有些网站是登录后跳转,会把post那个log删除。我填好后提交之后得到了下面结果:
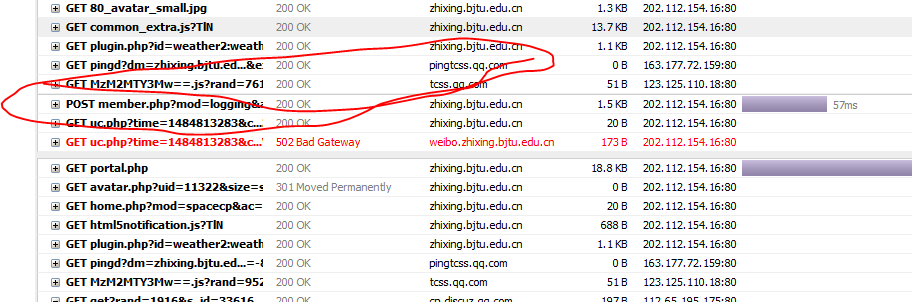
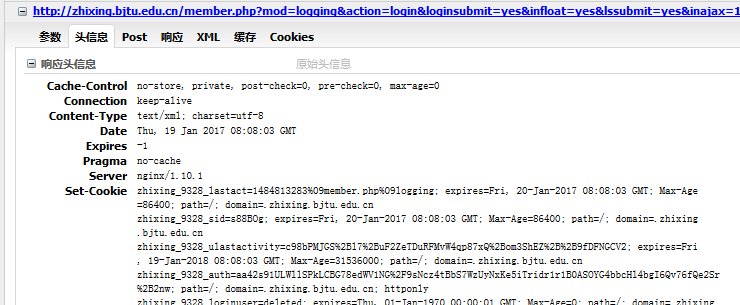
然后再看下提交的表单数据:
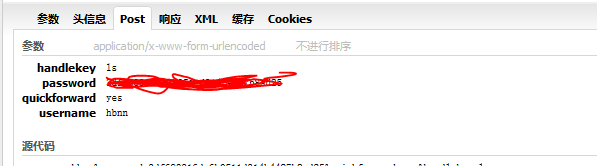
请求头:

至此,我们已经拿到了所有需要的数据,现在开始模拟。
我们使用requests模块,该模块有Session类,很管用。Session类对象让你能够跨请求保持某些参数,它也会在同一个 Session 实例发出的所有请求之间保持cookies.也就是说用一个session默认保存了cookie,不用认为去处理cookie,很方便 。
def login(self,posturl,postdata):
'''
self.build_opener()
postdata = urllib.urlencode(postdata)
request = urllib2.Request(url=posturl,data=postdata,headers=self.headers)
#print self.opener.open(request)
resp = urllib2.urlopen(request).read()
print resp
'''
self.session = requests.Session()
r = self.session.post(posturl,data=postdata,headers=self.headers)
return dict(r.cookies) if not isinstance(r.cookies,dict) else r.cookies
注意我的代码,session方法很简单,而用urllib2方法也可以实现目的,但是很麻烦。我这里的headers是我在类中定义的属性,就不过细赘述。我这里返回cookie,是为了给我的scrapy使用的,可忽略。
执行完上述操作后,我们就可以对需要登录才能访问的界面进行爬取了。
def login_get_content(self,url,url_type='html'):
content = self.session.get(url,timeout = 15)
try:
#get original data brfore transferring unicode
content = content.content
except UnicodeEncodeError:
content = content.text.encode('utf-8')
except UnicodeDecodeError:
print 'test'
content = content.text
content = StringIO(content)
#print content.read(),'test cstr'
if url_type == 'json':
return json.load(content)
elif url_type == 'xml':
return ET.parse(content)
else:
return BeautifulSoup(content,"html5lib")
我上面使用Beautifulsoup进行页面分析了。
看了上述操作,你肯定也会有感触,requests很好用。
说了上面的模拟登录,有人会说太麻烦,每次都要自己寻找posturl,formdata等等一大堆,他们提出直接手动登录,然后获取响应头中的cookie,这样很方便。但这最大的问题就是cookie是存在有效期,过期后就不好用了,而且作为程序员,怎么能允许自己总是手动这么low的方式存在呢,所以还是一劳永逸的好。获得cookie之后,你别的地方也完全可以使用该cookie进行登录。我在scrapy中就将requests与其结合了。
class ZxSpider(CrawlSpider):
name = 'zhixing'
def start_requests(self):
spider = Base_Spider('zhixing',['Host','Origin','Referer'])
posturl = 'http://zhixing.bjtu.edu.cn/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1'
postdata = {
'username':'***',
'password':'*****',
'quickforward':'yes',
'handlekey':'ls'
}
cookies = spider.login(posturl,postdata)
url = 'http://zhixing.bjtu.edu.cn/thread-1047622-1-1.html'
return [Request(url,cookies=cookies,callback=self.parse_page,headers=spider.headers)]
def parse_page(self,response):
sel = Selector(response)
r = sel.xpath('//td[@id="postmessage_10415551"]/text()').extract_first()
print r
return r
在scrapy中获取到cookies之后,就可以随心所欲的进行爬取啦!
介绍完了模拟登录,后续要开始研究对动态加载页面的爬取知识。
微信分享/微信扫码阅读

