
系统高可用的实现
之前在浅谈集群的分类中介绍了集群的作用,但并没有过多描述高可用相关的知识,本文主要介绍我们系统架构的高可用性,以及实现方式。
高可用即整个系统可以在大部分时间内对外提供服务,无论系统内部发生任何故障,系统都尽量不崩掉。
实现高可用的方式有很多,最常见的方式是垂直扩展和水平扩展,垂直扩展即对单台机器的硬件设施进行升级,升级CPU,内存,磁盘等;水平扩展即冗余部署,以集群的方式部署服务。总结就是:
- 冗余备份,无状态;
- 可实现故障自动转移;可借助ZK,KEEPALIVE等手段来实现。
- 降级,熔断;
- 兜底方案;
- 微服务治理;
- 监控 ,包括基础设施监控,计算机系统监控,业务监控等等。

本文会着重介绍集群模式下的高可用的实现。其实关于高可用还有其他的一些辅助手段,尤其是对于一些ToC的业务系统,比如电商平台,可能还会考虑到熔断、降低、限流等措施,但本文并不会做过多介绍。

针对于集群,实现高可用的手段主要包括:
- 一主多从或者多主多从部署方式;
- 自动的健康检测;
- 自动的主备切换;
本文会通过数据库、Redis、消息队列、Dubbo等成熟中间件或者框架来介绍高可用的实现。
有些框架会自己实现高可用,有些框架会借助一些成熟的工具来实现,比如KeepAlived等等。
第三方高可用工具:
keepalive
这个比较常用。keepalive是一种使用虚拟路由冗余协议实现的。整个集群组成了一个路由组网,并对外提供一个虚拟ip(vip),在某个节点发生故障时(通过心跳等检测机制实现),会自动进行vip漂移(选举某个slave成为master的依据是可以配置每台机器的权重)。有一篇文章写得比较好: 负载均衡之备胎转正
heartbeat
第三方负载均衡:
LVS
HaProxy
Nginx
MiProxy数据库 高可用
Miproxy是小米基于Kingshard开发的一个代理,避免了客户端和数据库的直连。这种部署方式相对于传统方式的好处是集群内部的调整对客户端是无感知的,且可以实现读写分离,统一管理。

MiProxy后端的数据库是以一主多从的方式部署的。主库提供读写功能,从库只提供读功能。Miproxy会根据sql语句来决定,流量分发到哪台机器上。
主库会向ZK上报状态,从库会watch ZK节点的主库状态,如果失效会发起选举,当某一台slave成功选举成master后,会根据GTID自动切换为master。通过ZK实现了Master挂掉后,Slave自动切换成master,从而保证了主库的高可用性。实际上还有从库,从库本身如果出现问题该怎么办。
1、实例故障踢除
从库DOWN,流量自动转主库
从库DELETE,流量自动转可用从库
无从库可用,流量自动转主库
2、同步延迟/中断自动踢除
seconds_behind_master : 600
seconds_behind_master这个指标表示的是主备延迟。这个延迟可以手动配置让其必须延迟,否则这个值会根据每个事务的执行变化。影响这个字段的因素包括 事务是个事务(在主库执行很久)、从库压力较大(因素很多,比如QPS较高,机器负载较高等等)。这个指标的计算就是用从库开始执行事务的时间减去主库执行事务的时间。
3、 故障恢复自动拉起
○ 自动下线从库恢复后自动拉起
○ 手工下线从库不会自动拉起
其实对于数据库这种有状态的集群来讲,在谈论高可用时最重要也是最不能忽视的就是数据的一致性。我们知道在CAP理论中,我们只能做到AP,CP,也就是C和A是不可兼得的。那如果做到高可用,可能会在一定程度上失去一致性。对于Mysql来讲,最开始主从复制是完全异步复制的,后来又引出了半同步复制。
异步复制:当master执行了相应的写操作,执行成功后直接返回客户端。随后异步得将数据同步到slave。这种好处就是在完成复制的同时,不会牺牲系统的响应速率,但最大的问题就是不能保证数据一致性;
同步复制:当master在执行写操作时,必须要等到所有slave库的relay log写完,才能够返回给客户端。该模式可以较好低保证数据一致性,但却严重影响系统性能,从库越多,性能越差;
半同步复制:该复制模式是异步方式和同步复制的折中方案,只要slave中有一个成功写入relay log,master就可直接返回,如果在一定时间内,没有slave写入成功,则复制模式变为异步复制。
Mysql还推出一个插件叫做组复制MGR,底层依赖于paxos,是实现故障自动检测、高可用的一种方式,本人没做研究,感兴趣的可以看看。
Redis高可用
Redis集群的发展路径->主从->哨兵机制->Redis-Cluster。
最早其实Redis并没有提供集群的较好的部署方案,一主多从的方式在master挂了的情况下,只能手动切换slave。后来出现了哨兵机制,sentinel。
哨兵机制实现的基础是单独开启一个进程叫哨兵(也会以集群的方式部署,避免哨兵本身出现问题),随后负责进行故障检测,以及主从切换。故障检测的实现比较简单,就是通过心跳机制的来判断主节点是否下线,哨兵集群会进行投票,如果哨兵集群的几个节点(哨兵集群数量的一半+1 ,n/2+1)都判定主节点下线了,才会认为主节点有问题了,并进行相应的故障转移。
那该选择哪个slave节点成为新master呢?主要是看以下几个指标:
1、看优先级,可以配置slave_priority
2、看复制进度;
3、id号最小的。
流程图:

当选择好新的主节点之后,让所有的从节点将复制节点(master)改成新的;通知客户端主节点变了。继续监视down掉的节点,如果恢复,就将其变为从节点。
sentinel可以较好得实现高可用,但其最大的问题是我们需要单独的进程部署sentinel,因此出现了另外一个Redis集群部署方式,Redis-Cluster,这是一个革命性的集群部署方案,不仅仅是实现了高可用,更重要的是分布式解决方案,将整个集群分片部署。
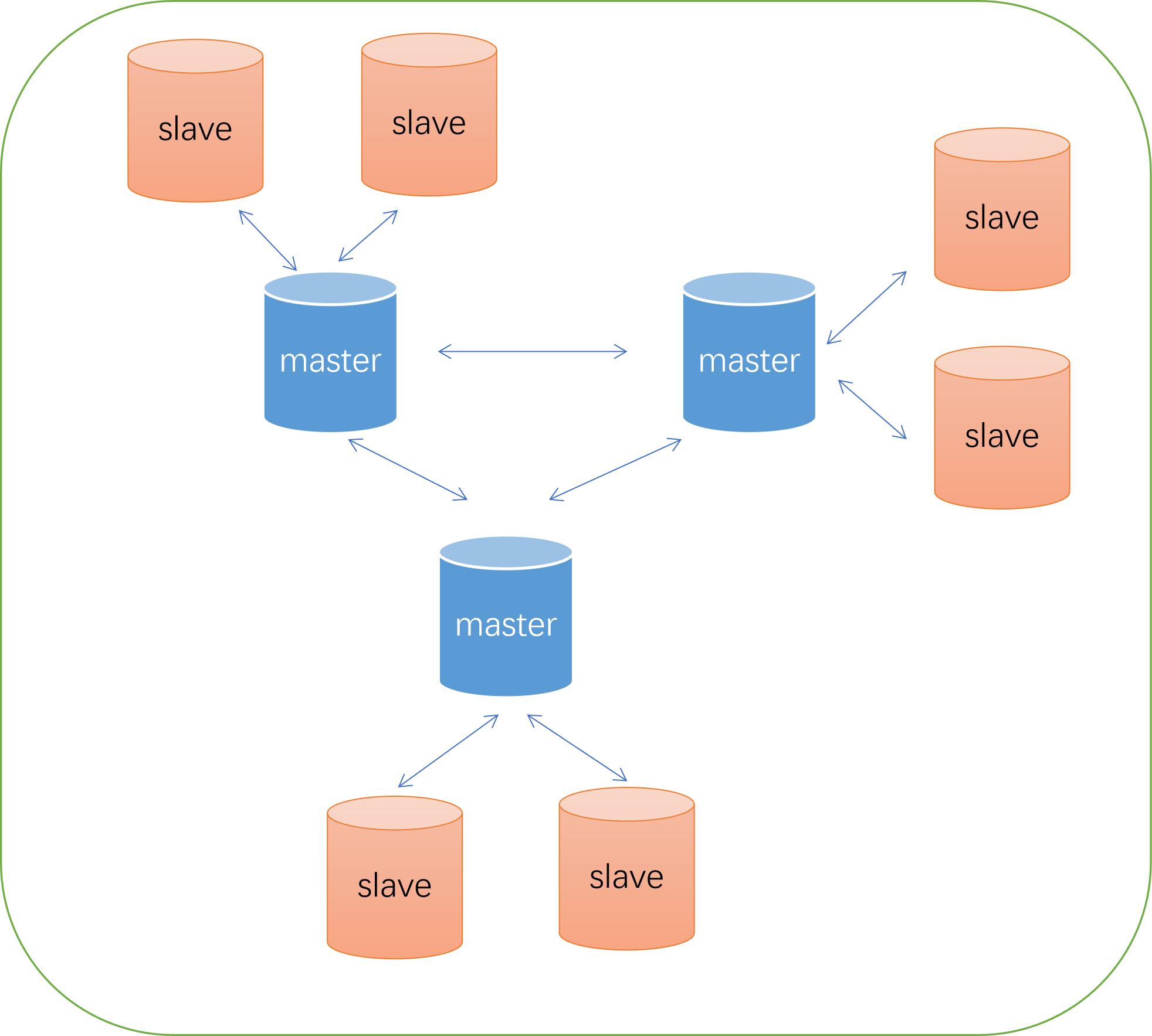
对于任意一个master而言,其后都跟着多个slave节点,当master出现故障时,会自动进行切换。Redis-Cluster的选举方式和sentinel的实现机制完全不同,其通过著名的分布式共识算法Raft来实现的。
具体流程是:
1、通过Ping消息,master节点在一定的超时时间内没有响应,就被标记为疑似下线,如果有多个节点认为该master节点疑似下线,那么该master就标记为下线。
2、master下的slave发起选举,其他的master节点会为相应的slave进行投票,根据Raft协议,选择出新的master节点;
这里要注意两点。一是slave发起选举,二是master投票。
Slave在认为master进入FAIL之后会delay一段时间才会发起选举,其原因是为了让master的FAIL状态在集群内广播。不同的slave的delay时间是不同的,从而避免一个master的多个slave在同一时间发起election。
master投票的条件:
- Slave所属的master的状态为FAIL
- Slave的currentEpoch大于等于master的currentEpoch
- Slave的configEpoch大于等于master认为该slave所属master的configEpoch
- Master维护一个lastVoteEpoch字段,针对每一个epoch只会投票一次,一旦投票后就会拒绝所有更小的epoch
- 投票就会回复ACK,否则就忽略
3、slave选举为新的master节点后,会被分配旧master的哈希槽。
RocketMQ高可用
RocketMQ的架构包括NameServer,Broker,Producer,Consumer。Producer和Consumer暂不说,NameServer和Broker是RocketMQ服务端的核心组件。
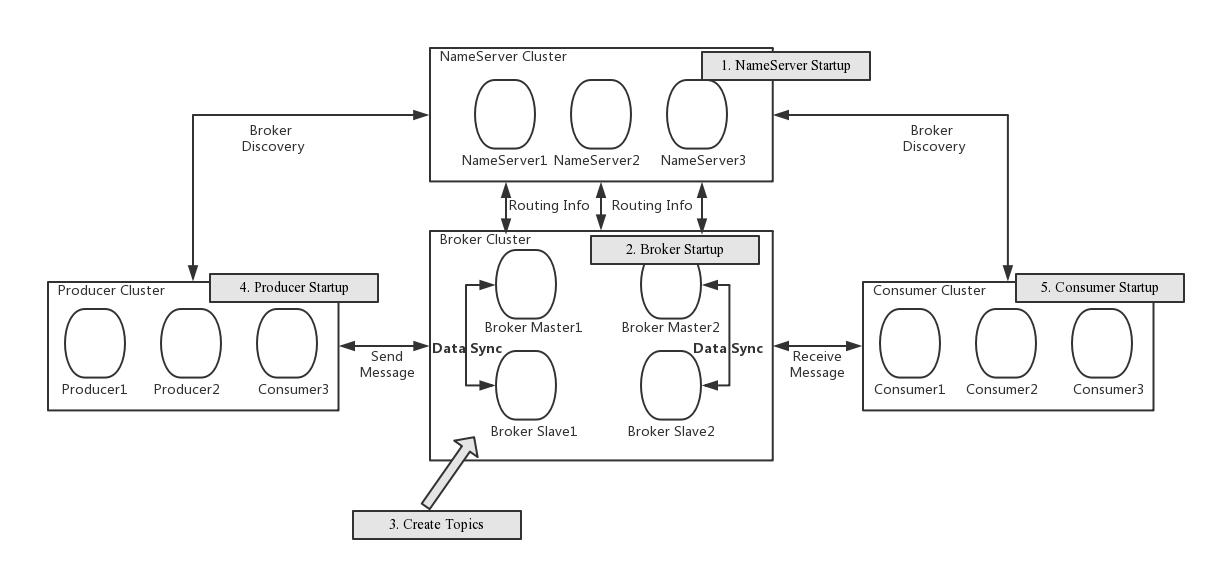
RocketMQ的高可用主要提现在Producer、MQ、Consumer三者。
先看核心RocketMQ,其包括NameServer,Broker组。
NameServer采用集群方式部署,至少三个节点,纯无状态服务,每个NameServer都会保存全部的路由信息。NameServer和Broker,Producer,Consumer三者都会建立链接。
Broker(包括master,slave)会和所有的NameServer建立长链接,固定周期发送心跳包,从而使得NameServer集群的每个节点都会存储所有的路由元信息。
Broker也是以集群的方式部署的,类似于Redis-cluster,也是有多个master多个slave,同样topic的不同队列可以分布式存储到不同的master节点上。当master下线了,可以自动从slave切换到master,实现的方式是使用Dledger。
Producer和Consumer会和NameServer集群中的一个节点建立长连接,都定时从NameServer拉取路由元信息。并与对应的Broker的Master,Slave建立长连接。
注意这里NameServer不会主动将路由变更信息推送给客户端,需要客户端自己去拉取信息,因为的确会在短时间内出现路由信息不一致的问题。
参考资料:
https://cloud.tencent.com/developer/article/1883453
https://juejin.cn/post/7062549452908658701
微信分享/微信扫码阅读

