
分布式任务队列 Celery 的介绍
(点击 上方公众号 ,可快速关注)
来源:思诚之道
链接:www.bjhee.com/celery.html
在程序运行过程中,要执行一个很久的任务,但是我们又不想主程序被阻塞,常见的方法是多线程。可是当并发量过大时,多线程也会扛不住,必须要用线程池来限制并发个数,而且多线程对共享资源的使用也是很麻烦的事情。还有就是前面几篇介绍过的协程,但是协程毕竟还是在同一线程内执行的,如果一个任务本身就要执行很长时间,而不是因为等待IO被挂起,那其他协程照样无法得到运行。本文要介绍一个强大的分布式任务队列Celery,它可以让任务的执行同主程序完全脱离,甚至不在同一台主机内。它通过队列来调度任务,不用担心并发量高时系统负载过大。它可以用来处理复杂系统性能问题,却又相当灵活易用。下面我们就来了解下Celery。
架构组成
一个完整的Celery分布式队列架构应该包含一下几个模块:
-
消息中间人 Broker
消息中间人,就是任务调度队列,通常以独立服务形式出现。它是一个生产者消费者模式,即主程序将任务放入队列中,而后台职程则会从队列中取出任务并执行。任务可以按顺序调度,也可以按计划时间调度。Celery组件本身并不提供队列服务,你需要集成第三方消息中间件。Celery推荐的有RabbitMQ和Redis,另外也支持MongoDB、SQLAlchemy、Memcached等,但不推荐。
-
任务执行单元 Worker,也叫职程
即执行任务的程序,可以有多个并发。它实时监控消息队列,获取队列中调度的任务,并执行它。
-
执行结果存储 Backend
由于任务的执行同主程序分开,如果主程序想获取任务执行的结果,就必须通过中间件存储。同消息中间人一样,存储也可以使用RabbitMQ、Redis、MongoDB、SQLAlchemy、Memcached等,建议使用带持久化功能的存储中间件。另外,并非所有的任务执行都需要保存结果,这个模块可以不配置。
完整的架构组成图如下:
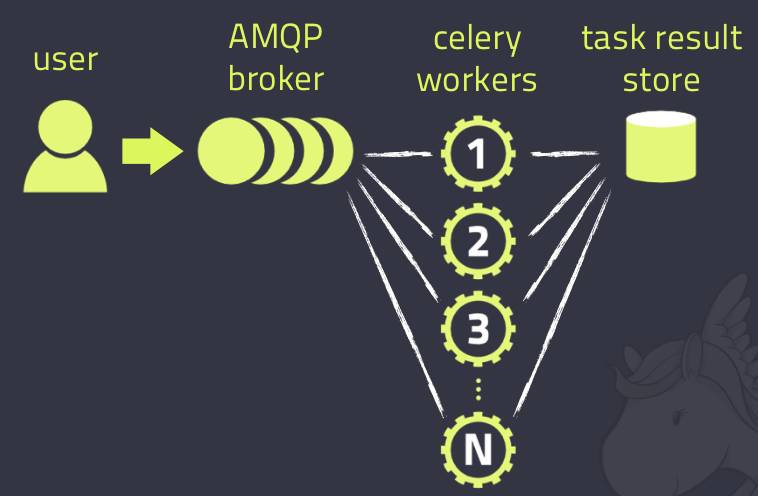
运行一个例子
让我们跑一个例子,我们使用RabbitMQ作为中间人,Redis作为结果存储。关于RabbitMQ和Redis的安装,大家可以网上搜搜,这里就不赘述了。本例假设RabbitMQ和Redis都安装在本地机上。
首先我们要安装Celery
当前最新的版本是4.0.0,我们可以通过PyPI安装:
$ pip install celery
为了支持Redis,你还需要安装Celery对Redis的依赖:
$ pip install 'celery[redis]'
然后,我们编写任务代码tasks.py
from celery import Celery
app = Celery ( 'tasks' ,
broker = 'amqp://guest@localhost//' ,
backend = 'redis://localhost:6379/0' )
@ app . task
def add ( x , y ) :
return x + y
这里我们创建了一个Celery实例app,名称为’tasks’;中间人用RabbitMQ,URL为’amqp://guest@localhost//’;存储用Redis,URL为’redis://localhost:6379/0’。同时我们定义了一个Celery任务”add”,可以返回两个参数的和。当函数使用”@app.task”修饰后,即为可被Celery调度的任务。
接下来,让我们启动后台进程
职程会监听消息中间人队列并等待任务调度,启动命令为:
$ celery worker -A tasks --loglevel=info --concurrency=5
-
参数”-A”指定了Celery实例的位置,本例是在”tasks.py”中,celery命令会自动在该文件中寻找Celery对象实例。不过我更建议你指定Celery对象名称,如”-A tasks.app”。
-
参数”loglevel”指定了日志等级,也可以不加,默认为warning。
-
参数”concurrency”指定最大并发数,默认为CPU核数。启动成功后,你会看到如下信息:
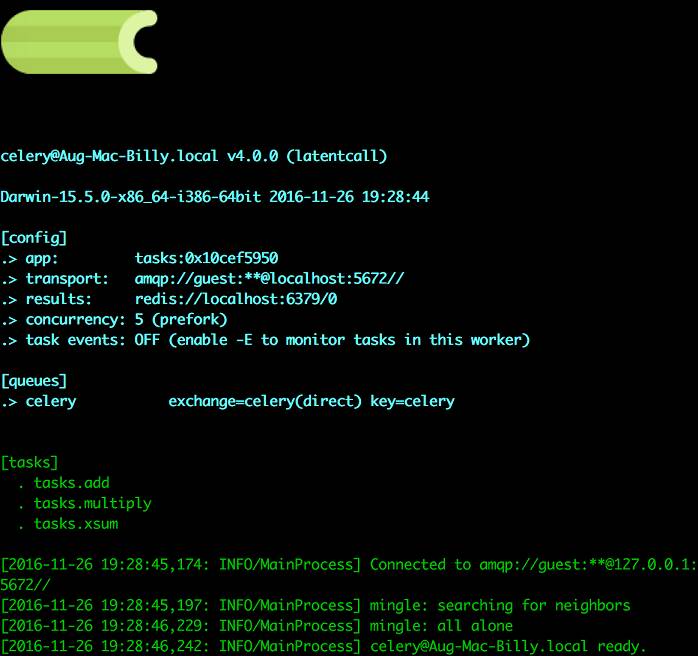
关于celery命令参数的更多信息,你可以用下面的命令来查询:
$ celery help
$ celery worker -- help
更详细的信息,就要去查阅官方文档了
现在,让我们发些任务出来吧
打开python控制台,输入下面的指令:
>>> from tasks import add
>>> add . delay ( 2 , 5 )
< AsyncResult : 4c079d93 - fd5f - 47f0 - 8b93 - c77a0112eb4e >
这个”delay()”方法会将任务发送到消息中间人队列,并由之前启动的后台职程来执行。所以这时Python控制台上只会返回”AsyncResult”信息。如果你看下之前职程的启动窗口,你会看到多了条日志”Task tasks.add[4c079d93-fd5f-47f0-8b93-c77a0112eb4e] succeeded in 0.0211374238133s: 7″。说明”add”任务已经被调度并执行成功,并且返回7。
因为我们的程序配置了后台结果存储(backend),我们可以通过如下方法获取任务执行后的返回值:
>>> result = add . delay ( 2 , 5 )
>>> result . ready ()
True
>>> result . get ( timeout = 1 )
7
此时我们就可以获取到返回值7了,由于有些任务执行时间会很长,我们可以使用”result.ready()”方法来检查任务是否执行完成。如果之前我们没有配置backend存储,那么刚才的调用会抛异常。
关于后台
上例中我们配置了Redis存储,那让我们去Redis里看看Celery任务执行的结果是怎么存储的吧。通过”keys celery*”,可以查到所有属于celery的键值,你会看到如下信息。
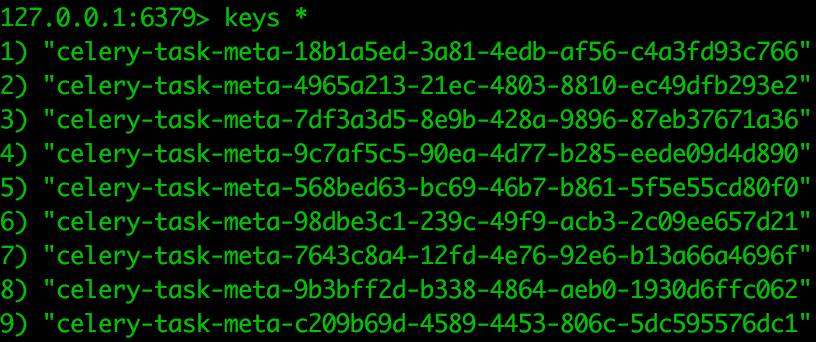
看来,celery是一个任务一条记录啊,而且键值上带着任务的UUID。让我们查看刚才执行的那条记录的值吧,结果如下:
"{\"status\": \"SUCCESS\", \"traceback\": null, \"result\": 7, \"task_id\": \"4c079d93-fd5f-47f0-8b93-c77a0112eb4e\", \"children\": []}"
状态,异常,返回值等都是通过JSon序列化存在Redis里的,很好理解吧。
关于配置
Celery的参数配置,可以使用下面几个方法来实现:
-
单个参数配置
app . conf . CELERY_BROKER_URL = 'amqp://guest@localhost//'
app . conf . CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
-
多个参数配置
app . conf . update (
CELERY_BROKER_URL = 'amqp://guest@localhost//' ,
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
)
-
从配置文件中获取
先将配置项放入配置文件中,如”celeryconfig.py”
BROKER_URL = 'amqp://guest@localhost//'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
然后导入到celery对象中:
app.config_from_object('celeryconfig')
Celery的配置项相当之多,大家可以从官方文档中查询。
delay()和apply_async()
我们之前调用任务使用了”delay()”方法,它其实是对”apply_async()”方法的封装,使得你只要传入任务所需的参数即可。对于特殊的任务调度需求,你需要使用”apply_async()”,其常用的参数有:
-
countdown: 指定多少秒后任务才被执行
-
eta: 指定任务被调度的时间,参数类型是datetime
-
expires: 任务过期时间,参数类型可以是int(秒),也可以是datetime
-
retry: 任务发送失败的重试次数
-
priority: 任务优先级,范围是0-9
-
serializer: 参数和返回值的序列化方式
详细参数列表可以从官方文档中查询。
关于序列化
当前版本的Celery默认序列化方式是”json”,对于刚才的例子,传入的参数和返回值都是数值类型,用json序列化没问题,但是对于有些对象来说,无法用JSon序列化,如果你是Python程序的话,可以使用”pickle”序列化,它支持所有Python类型对象。Celery支持的序列化方式还有”yaml”, “msgpack”。你可以在创建Celery对象时指定序列化方式,也可以通过配置指定,或者在使用apply_async()方法调用任务时指定:
app = Celery ( 'tasks' , broker = '...' , task_serializer = 'yaml' )
app . conf . update (
CELERY_TASK_SERIALIZER = 'pickle' ,
CELERY_RESULT_SERIALIZER = 'json' ,
)
@ app . task
def add ( x , y ) :
...
add . apply_async (( 2 , 5 ), serializer = 'json' )
关于并发
任务的并发默认采用多进程方式,Celery也支持gevent或者eventlet协程并发。方法是在启动职程时使用”-P”参数:
$ celery worker -A tasks --loglevel=info -P gevent -c 100
通过”-P gevent”我们就将并发改为了gevent方式了;”-c 100″同之前介绍的”concurrency”参数,指定了并发个数。对于gevent不熟悉的朋友,可以看看我之前的文章。另外默认多进程方式的参数值是”prefork”。
Flask同Celery的集成
本文的最后,我们演示一个将Flask应用同Celery集成的例子。最常见的任务就是发邮件,比如新用户注册,我们会发一个邮件来确认。由于发邮件是个IO阻塞式任务,我们可以将它交给Celery职程,而Flask应用可以继续运行。
首先,我们写个Flask应用,它会显示一个表单,让用户填写收件人和邮件内容,然后点击发送按钮来发邮件。
from flask import Flask , request , render_template , redirect , url_for , flash
from flask_mail import Mail , Message
app = Flask ( __name__ )
app . config . update (
SECRET_KEY = 'hard to guess string' ,
MAIL_SERVER = 'smtp.example.com' ,
MAIL_DEFAULT_SENDER = 'bjhee@example.com' ,
MAIL_USERNAME = 'bjhee' ,
MAIL_PASSWORD = 'example'
)
mail = Mail ( app )
@ app . route ( '/' , methods = [ 'GET' , 'POST' ])
def index () :
if request . method == 'GET' :
return render_template ( 'index.html' )
address = request . form [ 'address' ]
msg = Message ( 'Hello Celery' ,
recipients = [ address ])
msg . body = request . form [ 'content' ]
mail . send ( msg )
flash ( 'Sending email to %s' % address )
return redirect ( url_for ( 'index' ))
if __name__ == '__main__' :
app . run ( host = '0.0.0.0' , debug = True )
模版文件”index.html”的内容如下:
<! doctype html >
< html >
< head >
< title > Test Celery </ title >
</ head >
< body >
< h1 > Send mail </ h1 >
{ % with messages = get_flashed_messages () % }
{ % if messages % }
{ % for message in messages % }
< p style = "color: green;" > {{ message }} </ p >
{ % endfor % }
{ % endif % }
{ % endwith % }
< form method = "POST" >
< p > Address : < input type = "text" name = "address" ></ p >
< p > Content : < textarea name = "content" ></ textarea ></ p >
< input type = "submit" name = "submit" value = "Send" >
</ form >
</ body >
</ html >
让我们运行它,并测试下发邮件功能。你会发现发送过程是同步的。现在让我们加上Celery的代码:
from celery import Celery
celery = Celery ( 'tasks' ,
broker = 'amqp://guest@localhost//' ,
backend = 'redis://localhost:6379/0' )
celery . conf . update (
result_expires = 3600 ,
task_serializer = 'pickle'
)
@ celery . task
def send_email ( msg ) :
with app . app_context () :
mail . send ( msg )
这里,我们将发送邮件的方法”send_email()”定义为了一个Celery任务。要注意两点:
-
Flask-Mail必须在应用上下文中运行,因此在调用”mail.send()”之前需创建一个应用上下文。
-
Flask-Mail的Message对象不能用JSon序列化,因此要将序列化方式改为”pickle”。
另外,别忘了将Flask视图中发送邮件的方法改为”send_email.delay(msg)”。
现在,让我们启动职程,假设上述代码保持在文件”app.py”中:
$ celery worker -A app.celery --loglevel=info
再次运行这个应用,测试下发邮件功能,并查看下职程运行的日志,你会发现发邮件功能是在职程中执行的。
更多参考资料
-
Celery的官方网站
-
Celery的官方文档
-
github上的Celery源码
本文中的示例代码可以在这里下载(http://www.bjhee.com/downloads/201611/celery.tar.gz)。
觉得本文对你有帮助?请分享给更多人
关注「Python开发者」
看更多技术干货

微信分享/微信扫码阅读

