
并发编程之异步IO
之前学习了多进程,多线程,本文主要介绍下异步IO及协程。
- 协程介绍;
- yield实现协程以及原理;
- gevent实现协程
注:基于生成器的协程即将被废弃了,python3+中目前使用的都是通过asyncio实现。
通常情况下,多进程和多线程,多进程不多说了,就连线程,它最大的问题也是切换上下文的开销比较大,且由时钟中断来控制切换上下文,比较浪费时间。
Python在执行多线程时默认加了一个全局解释器锁(GIL),所以Python的多线程其实是串行的,并不能利用多核的优势。而哪怕在Java、C#这样的语言中,多线程真的是并发的,虽然可以利用多核优势,但由于线程的切换是由调度器控制的,不论是用户级线程还是系统级线程,调度器都会由于IO操作、时间片用完等原因强制夺取某个线程的控制权,又由于线程间共享状态的不可控性,同时也会带来安全问题。所以我们在写多线程程序的时候都会加各种锁,很是麻烦,一不小心就会造成死锁,而且锁对性能,总是有些影响的。 而协程较好的解决了线程切换出现的问题,它的核心思想是当发生阻塞(如发生IO),会主动让出CPU,后续再回来继续执行。这也是异步I/O的主要思想:即当需要执行一个耗时的IO操作时,它只发出IO指令,并不需要等待IO的结果,而是直接就去执行其他代码了。一段时间后,当IO返回结果时,再通知CPU进行处理。
下面是一个网上看到的非常浅显易懂的例子,专门讲了协程主动让出CPU的例子:
假设说有十个人去食堂打饭,这个食堂比较穷,只有一个打饭的窗口,并且也只有一个打饭阿姨,那么打饭就只能一个一个排队来打咯。这十个人胃口很大,每个人都要点5个菜,但这十个人又有个毛病就是做事情都犹豫不决,所以点菜的时候就会站在那里,每点一个菜后都会想下一个菜点啥,因此后面的人等的很着急呀。这样一直站着也不是个事情吧,所以打菜的阿姨看到某个人犹豫5秒后就开始吼一声,会让他排到队伍最后去,先让别人打菜,等轮到他的时候他也差不多想好吃啥了。这确实是个不错的方法,但也有一个缺点,那就是打菜的阿姨会的等每个人5秒钟,如果那个人在5秒内没有做出决定吃啥,其实这5秒就是浪费了。一个人点一个菜就是浪费5秒,十个人每个人点5个菜可就浪费的多啦(菜都凉了要)。那咋办呢?这个时候阿姨发话了:大家都是学生,学生就要自觉,我以后也不主动让你们排到最后去了,如果你们觉得自己会犹豫不决,就自己主动点直接点一个菜就站后面去,等下次排到的时候也差不多想好吃啥了。这个方法果然有效,大家点了菜后想的第一件事情不是下一个菜吃啥,而是自己会不会犹豫,如果会犹豫那直接排到队伍后面去,如果不会的话就直接接着点菜就行了。这样一来整个队伍没有任何时间是浪费的,效率自然就高了。
这个例子里的排队阿姨的那声吼就是我们的CPU中断,用于切换上下文。每个打饭的学生就是一个task。而每个人自己决定自己要不要让出窗口的这种行为,其实就是我们协程的核心思想。
Python的yield实现了协程,即当执行到yield函数时会返回,切换到其他函数,在另外一个函数遇到yield再返回到上一个函数,这样协同运行就是协程的思想。
当然,同步IO和异步IO代码逻辑还是有很多不同的。在“发出IO请求”到收到“IO完成”的这段时间里,同步IO模型下,主线程只能挂起,但异步IO模型下,主线程并没有休息,而是在消息循环中继续处理其他消息。这样,在异步IO模型下,一个线程就可以同时处理多个IO请求,并且没有切换线程的操作。对于大多数IO密集型的应用程序,使用异步IO将大大提升系统的多任务处理能力。下面一个例子(来自网上):
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)下面仔细说一下yield以及可迭代对象。
学过python的不可能不知道生成器,生成器可以通过yield实现。比如,最简单的:
for i in range(5):
yield i现在就详细介绍一下yield,send,next等。
要学好这块,要弄懂可迭代对象的迭代原理,要明白send,next函数的执行原理等知识。
1、可迭代对象。
python中列表,元祖,字符串,字典都是可迭代对象,他们叫做iterable,即他们都有一个内置的__iter__方法。
除了iterable之外,还有一种叫做iterator。说下这两者的联系和区别。
当我们执行iterable.__iter__()方法的时候会得到一个iterator。而iterator包含__next__方法,这允许我们使用next显示调用可迭代对象。
当我们利用for循环遍历iterable时,比如上面的例子,实际上是先通过iter(itertable)获得iterator,然后通过next方法,一步一步地调用。
想判断一个对象iterable还是iterator,可以使用标准库中collections中的类。
>>> from collections import Iterable, Iterator2、yield实现协程的原理
看例子:
def generator():
print 'start generator'
yield 1
print 'first:1'
yield 2
print 'second:2'
yield 3
print 'third:3'
g = generator()
g.next()输出:
start generator
为什么呢?
这是因为当执行到yield语句时候,就立即返回了,此时可以去执行别的函数了。这有点像CPU中断,即对该处设置一个中断,然后返回目前的结果,并保留当前上下文。当再次调用的时候可以从上次中断的地方开始。比如我们再调用一次next,看看结果是啥?
def generator():
print 'start generator'
yield 1
print 'first:1'
yield 2
print 'second:2'
yield 3
print 'third:3'
g = generator()
g.next()
g.next()输出:
start generator
first:1
看到了吧,当我们再次调用next()时候,就又开始从上次中断的地方开始执行,并遇到下一个yield。
这就是协程的思想。假如当一个协程遇到了IO阻塞,那就可以立即切换到别的协程上,当执行完后再继续执行之前的协程。其实上面的例子已经很形象了,你这个协程没想明白呢,你就退出来,让别的协程执行。等你想明白了,你再回来执行。
说完了yield实现思想,再深入研究一下yield的用法,如send,close等等。
看个例子:
def generator():
print 'start generator'
value = yield 1
print 'send:',value
print 'first:1'
yield 2
print 'second:2'
yield 3
print 'third:3'
g = generator()
g.next()
g.send('f')输出:
start generator
send: f
first:1
当我们调用send的时候,又开始执行函数第一个yield之后的语句,知道再遇到yield。此外并输出了我们传入的值。也就是说,send方法共发生了两件事。
1、继续执行,意味着send也调用了next;
2、输出传入的值。看这句value = yield 1,我们通过send方法将变量传给了yield表达式,即(yield 1),之后value复制了该表达式的引用。之后print该变量,变得到了传入的值。
这里有一点要注意,执行send方法,并传入非None值的条件是,必须到生成器表达式处,即yield处,否则会出错。
def generator():
print 'start generator'
value = yield 1
print 'send:',value
print 'first:1'
yield 2
print 'second:2'
yield 3
print 'third:3'
g = generator()
g.send([1,3])报错:
Traceback (most recent call last):
File "C:\Python27\s.py", line 95, in <module>
g.send([1,3])
TypeError: can't send non-None value to a just-started generator
你可以直接使用g.send(None)来实现和next同样的作用。next不可以传入非None值。
注:基于生成器的协程即将被废弃了,python3+中目前使用的都是通过asyncio实现。
一个简单的例子:
import asyncio
import time
t1 = time.time()
async def get1():
print("hehe")
await asyncio.sleep(3)
print("restart to execu")
return 3
async def get12():
print("hehe")
await asyncio.sleep(4)
print("restart to execu")
return 12
async def main():
result = await asyncio.gather(get1(), get12())
print("Finish,it cost :{}".format(time.time() - t1))
print(result)
asyncio.run(main())doDeal是一个协程,其实如果正常的执行,还是相当顺序执行,但当用了await.create_task就会创建任务,在循环事件中执行。
def create_task(coro):
"""Schedule the execution of a coroutine object in a spawn task.
Return a Task object.
"""
loop = events.get_running_loop()
return loop.create_task(coro)
内部的await语法来挂起自身的协程,外部的await是主程序等待协程执行。类似于golang的
sync.WaitGroup
详情: Python asyncio
..........................................................................分割线................................................................
生成器有个问题,当执行完最后一个yield,再调用next,会报错:StopIteration。
除此之外,还可以提前终止:throw() 与 close()
可以通过throw抛出一个GeneratorExit异常来终止Generator。Close()方法作用是一样的,其实内部它是调用了throw(GeneratorExit)的 。
这里,把一哥们画的图粘出来,我觉得画得特别好:
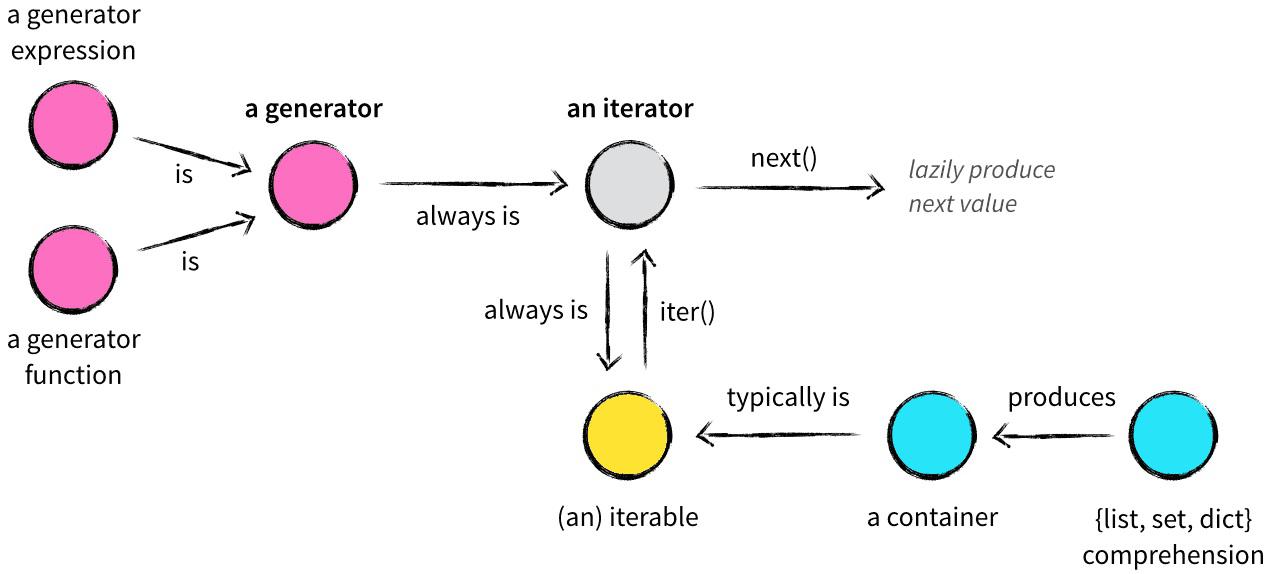
上面,blabla说了一大堆的yield的问题,现在我们再研究一下比较简单的实现协程的方法。
目前第三方模块能提供较好的协程实现方法,例子如下:
import threading
5 import urllib2
6 import timeit
7 import gevent
8
9
10 def f(url):
11 res = urllib2.urlopen(url)
12 data = len(res.read())
13 print data
14
15
16 url1 = 'http://www.baidu.com'
17 url2 = 'http://www.sina.cn'
18 url3 = 'http://www.qq.com'
19
20 def main():
21 ths = []
22 p1 = threading.Thread(target=f,args=(url1,))
23 ths.append(p1)
24 p2 = threading.Thread(target=f,args=(url2,))
25 ths.append(p2)
26 p3 = threading.Thread(target=f,args=(url3,))
27 ths.append(p3)
28
29 for t in ths:
30 t.start()
31 for t in ths:
32 t.join()
33
34
35 def ge():
36 gevent.joinall([
37 gevent.spawn(f,url1),
38 gevent.spawn(f,url2),
39 gevent.spawn(f,url3)])
40
41
42
43 if __name__ == "__main__":
44 t= timeit.Timer("main()","from __main__ import main")
45 #t= timeit.Timer("ge()","from __main__ import ge")
46 print t.repeat(1,1)
利用多线程运行时间:0.9850409030914307;
利用协程运行时间:0.2833070755004883;
同样,我们可以使用协程池,和进程池的用法差不多。
不过协程的缺点是无法使用多核,但我们可以通过多进程+协程来实现。
。。。。。。。。。Python3+的异步IO应用起来是给力了,相对于多线程,可以大大提高性能。下面是一个简单爬虫的例子。是多线程和异步的对比:
import time
import aiohttp
import asyncio
from bs4 import BeautifulSoup
import requests
from concurrent import futures
table = []
def parser(html):
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(html, "lxml")
# 获取网页中的畅销书信息
book_list = soup.find('ul', class_="bang_list clearfix bang_list_mode")('li')
for book in book_list:
info = book.find_all('div')
# 获取每本畅销书的排名,名称,评论数,作者,出版社
rank = info[0].text[0:-1]
name = info[2].text
comments = info[3].text.split('条')[0]
author = info[4].text
date_and_publisher = info[5].text.split()
publisher = date_and_publisher[1] if len(date_and_publisher) >=2 else ''
# 将每本畅销书的上述信息加入到table中
table.append([rank,name,comments,author,publisher])
# 处理网页
async def download(url):
async with aiohttp.ClientSession() as session:
html = await fetch(session, url)
parser(html)
# 全部网页
urls = ['http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-%d'%i for i in range(1,26)]
# 统计该爬虫的消耗时间
print('#' * 50)
t1 = time.time() # 开始时间
def down(url):
resp = requests.get(url).text
parser(resp)
return "s"
with futures.ThreadPoolExecutor(8) as fet:
res = {fet.submit(down,url) for url in urls}
for f in futures.as_completed(res):
print(f.result())
print(table)
t2 = time.time() # 结束时间
print('耗时:%s' % (t2 - t1))
上面耗时:1.447s
async def download(url):
async with aiohttp.ClientSession() as session:
resp = await session.get(url)
resp = await resp.text(encoding='gb18030')
parser(resp)
# 利用asyncio模块进行异步IO处理
# loop = asyncio.get_event_loop()
# tasks = [asyncio.ensure_future(download(url)) for url in urls]
# tasks = asyncio.gather(*tasks)
# loop.run_until_complete(tasks)
耗时:1.040s。
微信分享/微信扫码阅读

