
高并发之缓存
我写的另外一篇更加详细的文章: 缓存那些事儿
1、Cache简单介绍
2、CPU cache
3、业务场景cache
1、Cache的引入和介绍
缓存,在计算机领域是随处可见的一个话题。其主要是通过硬件或者软件的组件存储请求的数据,从而使得要访问的数据可以更快的获取到。最早提到的缓存是CPU缓存,因为CPU处理速度很快,然而内存数据的读取有点跟不上处理器,因此出现了CPU cache,主要是缓存主存中的数据。后来慢慢发展,又出现了硬盘缓存。
还有我们业务中经常用到的网络数据缓存,网络数据缓存就太多了,如果分层来说,就是浏览器,CDN缓存,反向代理缓存,后端应用一级缓存、二级缓存等等。总之,各种缓存随处可见。
之前写过的文章:
2、CPU cache
cpu缓存的出现主要是为了减小处理器读取内存数据的时间,通过设置高速缓存,处理器就不必在直接读取内存,而是先查找CPU cache,如果命中,直接返回,如果不命中,向下级查询,如果cache中没有,再查询主内存
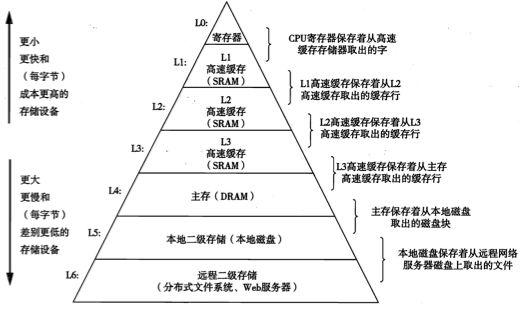
下面是CPU的多级缓存金字塔,不同缓存有着不同的作用。
看一下我的linux系统的CACHE:
getconf -a|grep CACHE
LEVEL1_ICACHE_SIZE 32768
LEVEL1_ICACHE_ASSOC 8
LEVEL1_ICACHE_LINESIZE 64
LEVEL1_DCACHE_SIZE 32768
LEVEL1_DCACHE_ASSOC 8
LEVEL1_DCACHE_LINESIZE 64
LEVEL2_CACHE_SIZE 262144
LEVEL2_CACHE_ASSOC 4
LEVEL2_CACHE_LINESIZE 64
LEVEL3_CACHE_SIZE 8388608
LEVEL3_CACHE_ASSOC 16
LEVEL3_CACHE_LINESIZE 64
LEVEL4_CACHE_SIZE 0
LEVEL4_CACHE_ASSOC 0
LEVEL4_CACHE_LINESIZE 0
那为啥CPU缓存要设置多级缓存呢?主要是为CPU和内存设置了多层的缓冲和平衡,如果只有一层,如果只追求速度,那么缓存容积会很少;如果只追求容积,那么性能又很差。这是缓存多层的一个平衡。
回写策略
写回是指,仅当一个缓存块需要被替换回内存时,才将其内容写入内存。如果快取命中,则总是不用更新内存。为了减少内存写操作,缓存块通常还设有一个脏位(dirty bit),用以标识该块在被载入之后是否发生过更新。如果一个缓存块在被置换回内存之前从未被写入过,则可以免去回写操作。
写回的优点是节省了大量的写操作。这主要是因为,对一个数据块内不同单元的更新仅需一次写操作即可完成。这种内存带宽上的节省进一步降低了能耗,因此颇适用于嵌入式系统。
写通较写回易于实现,并且能更简单地维持数据一致性写通是指,每当缓存接收到写数据指令,都直接将数据写回到内存。如果此数据地址也在缓存中,则必须同时更新缓存。由于这种设计会引发造成大量写内存操作,有必要设置一个缓冲来减少硬件冲突。这个缓冲称作写缓冲器(Write buffer),通常不超过4个快取Block大小。不过,出于同样的目的,写缓冲器也可以用于写回型缓存。
缓存的一致性
多核CPU,每个CPU都有一个L1和L2,如果在L1或L2中的数据被更新了,如何保证不同CPU数据的一致性呢?
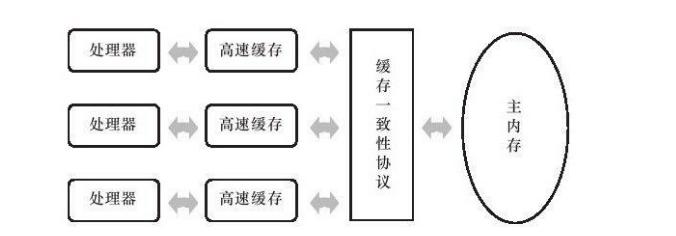
对于多核CPU来说,操作系统会通过CPU总线,保证同一时刻只有一个处理器在写内存。当一个CPU1正在修改高速缓存中的数据时,其他CPU对应的缓存会被通知无效,随后CPU1会将数据写入内存,其他CPU会读取内存中的被更新的数据。
在处理器上还有一个协议较MESI协议,它的作用就是为了保证缓存的一致性。
- modify:当前CPU cache拥有最新数据(最新的cache line),其他CPU拥有失效数据(cache line的状态是invalid),虽然当前CPU中的数据和主存是不一致的,但是以当前CPU的数据为准;
- exclusive:只有当前CPU中有数据,其他CPU中没有改数据,当前CPU的数据和主存中的数据是一致的;
- shared:当前CPU和其他CPU中都有共同数据,并且和主存中的数据一致;
- invalid:当前CPU中的数据失效,数据应该从主存中获取,其他CPU中可能有数据也可能无数据,当前CPU中的数据和主存被认为是不一致的;
一个简单流转过程:
1、CPU1读取一个共享变量a,此时CPU1本地缓存的对应数据标记为E,表明是独享;
2、CPU2读取变量a,CPU1,CPU2的本地缓存的对应数据都标记为S,共享状态;
3、CPU1修改变量a,CPU1本地缓存状态变为M,通过控制总线告知CPU2本地缓存将对应数据标记为I;
4、此时并不做任何事情;
5、当CPU2要修改a,发现为I标记,就会让CPU1将对应数据回写到主内存中,CPU2再读取主内存数据。
通过上述过程,可发现缓存不能保证强一致性,就是不能保证本地缓存和主内存完全一致。比如当一个CPU,CPU1修改了某个缓存数据,但是还没有回写到主内存,此时其他CPU要读取对应数据,但发现该数据已被标记为dirty,不能读了,只能读主存的,但此时可能主存数据还没有被CPU1回写。
基于这个问题,Java有个volatile,就是解决这个问题的。它可以保证每次有更新,都会及时刷到主存中。
此时CPU1的修改操作和回写操作是原子操作。
3、业务场景cache
在现如今互联网业务中,用户数和并发量不断变大,导致服务器响应时间变长。而瓶颈通常都是在数据库的请求上。为了提升服务器性能,通常我们都会选择缓存数据库的响应数据。
如果将业务分层的化,每层都会有自己的缓存,从浏览器,到Nginx,到应用,到数据库等等。
之前写过一篇文章叫做: HTTP缓存 ,主要是介绍在互联网应用对于一些静态资源的缓存策略,里面介绍了浏览器和Nginx缓存相关知识。
此外,就是对动态数据的缓存。从Mysql本身来说,其实他本身也有缓存。对于每一条查询语句,Mysql的sql解析器都会分析该语句是否之前执行过,如果有且之间没发生啥变化,就会直接拿缓存数据,不再执行查询语句。具体关于Mysql缓存机制可以查看下面的相关资料。
虽然Mysql有缓存,但其并不能满足我们对于数据的缓存要求,首先我们缓存的数据可能并不是简单的一条sql查询的数据,此外Mysql有任何的数据的变化,缓存都会失效。
基于此,业务都会采用其他缓存。从缓存介质来说,可以分为内存,文件和非关系型数据库。从缓存类别说,可以有本地缓存和分布式缓存。
现在我们的本地缓存一般都使用的是进程内缓存,而分布式缓存可以为Memcached,Redis等等。而日常使用中都是两者相结合,进程缓存为 一级缓存,分布式缓存为二级缓存。
不同的语言,不同的web框架,有着不同的进程内缓存的实现方法。比如Django,比如Springboot等等。springboot相关的有Encache,GuavaCache(google提供的)。
我们提到缓存,绕不开的有两个议题,一个是淘汰策略,一个是缓存一致性。
淘汰策略比如LRU,LFU,FIFO等等,有很多,每个缓存相关服务或者框架实现的原理可能各不相同。
缓存一致性,主要是数据库和缓存的一致性。当有数据变化时,如何保证缓存和数据库的数据一致性?
解决方案有以下几种:
1、先删除缓存,再更新数据库;
2、先更新数据库,再更新缓存;
3、先更新数据库,再删除缓存。
参考资料:
【并发编程】CPU cache结构和缓存一致性(MESI协议)
微信分享/微信扫码阅读

