
浅谈Kafka以及Rocketmq的高性能
Kafka和Rocketmq作为消息队列,它是如何保证高吞吐量和高性能的呢?
可以主要看下Kafka,因为Rocketmq基本上都沿用了Kafka的思想。
其高性能主要依赖于以下几个机制:
1、顺序IO
2、PageCache
3、零拷贝
一、顺序IO
Kafka的消息是落到磁盘文件上的,正常来讲因为读写磁盘IO都是比较耗时的操作,尤其是对于随机IO来说,性能较差。我们知道一个磁盘IO的事件需要经过磁盘寻道,寻转延迟以及数据传输等过程,如果是随机IO,那么寻道是一个很耗时的过程。Kafka通过每次写数据追加到文件的末尾,保证顺序的写入。
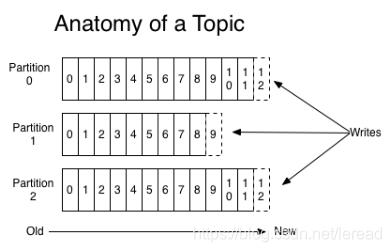
通过这种模式写入,读取就变得简单了,kafka会将每个partition进行分段,每段都是一个segment,文件分为.index和.log文件,分别记录了索引数据和文件数据。.index记录的是二元组。 比如 (5,102),表示在数据文件第5个消息,用基础偏移量,就是文件名的值+5就是全局的offset,其偏移地址是102.
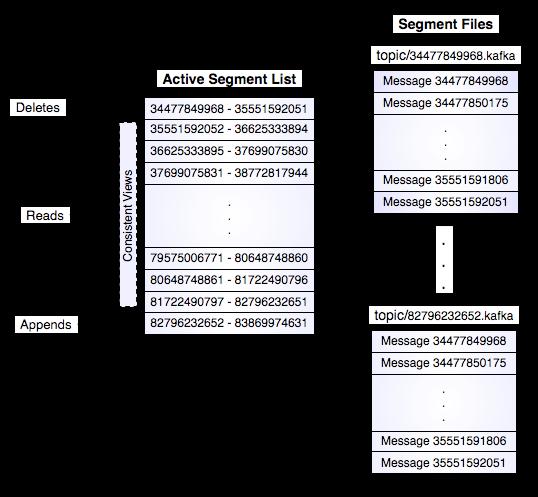
上面分析了读写的一个过程。
二、PageCache
之前也写过一篇文章介绍过PageCache: 操作系统磁盘缓存 。
简单说就是由于磁盘操作时一个比较耗时的操作,CPU更多的时间都是在等待。因此操作引入了一个磁盘缓存的概念,主要包括PageCache和BufferCache。PageCache主要是强调的对文件的缓存。
当Broker接收到数据后,它是先将数据写入到PageCache中,并不是直接写入到磁盘文件上,这就大大减少了操作时间,提升了性能。然后隔一段时间后,内核线程再将PageCache数据刷到磁盘上。
那么问题来了,当机器down机,且还没有来得及将数据刷到磁盘文件中,数据会丢失吗?
正常情况下,的确是会丢的。在Kafka中,如果想保证不丢失,就使用同步刷盘的机制,但这样会严重影响整个系统的性能。可以通过减小刷盘间隔来尽量避免数据丢失。现在我们公司采用的Rocketmq也是采用异步刷盘的机制,通过使用分布式集群,保证只要有一个broker不掉线,PageCache就不会丢失。
通过直接写内存,保证了写的性能。如果读的速度和写的速度相当,那么读的操作也可以直接从PageCache获取。这种不经过磁盘文件的操作是其高性能的重要原因之一。
三、零拷贝
零拷贝的技术之前已经写过文章介绍了,可以看: Linux之零拷贝技术 。
零拷贝技术有很多种,有sendfile,mmap等方式。
Kafka在写入时使用了mmap的方式,在发送时使用了sendfile。它也是直接调用了JAV API transferTo,最终调用操作系统的sendfile。
然而Rocketmq是只使用了mmap+write的方式。主要是考虑通常情况都是小数据传输,而sendfile只是将文件描述符拷贝到缓冲区,只有通过阻塞的方式完成数据文件发送。mmap可以使用异步方式发送。
JAVA的mmap通过MapperByteBuffer实现的。现在模仿一个写操作:
public void writeByMap(){
Path path = Paths.get("/home/haibo/t.py");
String haibo = "dwdwdeghrhyu5u6hbheu68i7jnbsft37u8ihewt8u";
byte[] bytes = haibo.getBytes(StandardCharsets.UTF_8);
try{
FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ,StandardOpenOption.WRITE,StandardOpenOption.TRUNCATE_EXISTING);
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE,0,bytes.length);
if (mappedByteBuffer != null){
mappedByteBuffer.put(bytes);
mappedByteBuffer.force();
}
}catch (Exception e){
e.printStackTrace();
}
}通过strace -c -tt javac IOPra 看一下系统调用:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
20.88 0.000753 18 41 29 openat
17.91 0.000646 14 45 mmap
14.50 0.000523 523 1 execve
10.68 0.000385 16 24 21 stat
10.29 0.000371 23 16 mprotect
3.52 0.000127 15 8 pread64
3.13 0.000113 56 2 munmap
3.00 0.000108 9 12 fstat
2.41 0.000087 7 12 close
2.38 0.000086 43 2 readlink
2.33 0.000084 7 11 read
1.97 0.000071 71 1 clone
1.83 0.000066 22 3 2 access
1.22 0.000044 14 3 brk
0.80 0.000029 14 2 1 arch_prctl
0.75 0.000027 13 2 getpid
0.69 0.000025 12 2 rt_sigaction
0.50 0.000018 18 1 set_tid_address
0.50 0.000018 18 1 set_robust_list
0.39 0.000014 14 1 prlimit64
0.31 0.000011 11 1 rt_sigprocmask
0.00 0.000000 0 1 futex
------ ----------- ----------- --------- --------- ----------------
其实Kafka还做了很多的优化,比如并行处理啊,数据压缩啊等等。上面三种是主要的三个因素。
参考资料:
微信分享/微信扫码阅读

