
堆栈与队列
说起堆栈都会考虑到两个方面,一是指进程中的堆和栈,二是指数据结构中的堆和栈。
一、进程的堆和栈
栈主要是用来存放局部函数的参数和局部变量的值,由系统自动分配释放,具体的操作和数据结构的栈一样,即先进后出,通常是和线程相关的,栈里存的是栈帧,每个栈帧包括栈帧地址和栈顶地址;而堆是由程序员自动分配释放(malloc,calloc等),如果不释放,就会由操作系统自动回收,操作类似于链表。不过在运行中仍然可以申请。最多可以申请一个进程内堆的最大值。
栈中分配局部变量空间,堆区是向上增长的用于分配程序员申请的内存空间。另外还有静态区是分配静态变量,全局变量空间的;只读区是分配常量和程序代码空间的;以及其他一些分区。
如果是使用C语言编写代码的,是很容易出现缓冲区溢出的,之前在1988年就发生了利用该漏洞进行攻击的事件。简单解释缓冲区溢出,就是我们分配了一个固定大小的数组,但是有人恶意写入超过数组边界的字符串,然而C语言是不做边界检测的,所以就导致向上写入,如果攻击者在函数返回地址中写入其他的返回地址,可能导致意想不到的事情发生。具体可参考: 缓冲区溢出原理
在Python中,一切皆为对像,且Python是由C实现的,Python中所有的对象都是存在堆中,它的分配器会根据对象的大小来决定选择哪种,对于大于512KB(可以设置更改)的对象,使用 Python 原生内存分配器(Python’s raw memory allocator)进行分配,它的本质也是调用 C 标准库中的malloc/realloc/free等 函数;对于小于等于 512KB 的对象,内存分配主要由 Python 对象分配器(Python’s object allocator)实施,也就是本文中所要介绍的 pymalloc 机制;对于一些内置类型,如 int/dict/list/string 等,又会有单独的针对这些内置类型的分配器实现。比如管理 int 类型就使用一个简单的 free list。
二、数据结构中的堆,栈和队列。
1、栈
特点:后进先出 Last In First Out,LIFO。
类比: 往纸箱里放书,只能往最上面放,或者从最顶上拿
基本操作:顶端放入新元素(push),顶端移除元素(pop)
栈上溢:当试图向一个满栈中插入一个元素时,会出现栈上溢。
栈下溢:当试从一个空栈中获得一个元素时,就出现栈下溢。
使用场景:
- 子程序的调用
- 递归调用
-
栈计算四则运算表达式。需要一个数字栈,一个操作符栈,一直从左向右读取,读到右括号。

一个基本例子
class Stack(object):
def __init__(self,size):
self.size = size
self.stack = []
def isEmpty(self):
return True if len(self.stack) == 0 else False
def isFull(self):
return True if len(self.stack) == self.size else False
def push(self,a):
#the last one of list stack is the bottom of Stack
assert(not self.isFull())
self.stack.append(a)
def pop(self):
assert not self.isEmpty()
self.stack.pop()
def get_top(self):
assert not self.isEmpty()
return self.stack[-1]
def clear(self):
while not self.isEmpty():
self.pop()
if __name__ == "__main__":
stack = Stack(3)
stack.push(1)
stack.push(2)
stack.push(3)
stack.clear()
print stack.get_top()
上述代码实现了基本的栈的功能。
这里要说一下Flask框架,因为在Flask中就使用了栈这种数据结构。
Flask中的请求上下文以及应用上下文都存储在栈中,定义如下:
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
具体可见Flask源码,以及我写过的一篇博客 Flask上下文 。
再说一下队列。
队列与栈正好相反,队列是FIFO,即先入先出,下面实现了一个基本队列。
class Full(Exception):
pass
class Empty(Exception):
pass
class Queue:
def __init__(self,maxsize):
self.maxsize = maxsize
self.queue = []
def push(self,obj):
if len(self.queue) >= self.maxsize:
raise Full
else:
self.queue.append(obj)
def isEmpty(self):
return True if len(self.queue) else False
@property
def size(self):
return len(self.queue)
def pop(self):
if len(self.queue) == 0:
raise Empty
else:
return self.queue.pop(0)
def peek(self):
return self.queue[0]
s=Queue(3)
s.push(3)
s.push(4)
s.push(6)
print s.pop()
print s.pop()
print s.pop()
队列是比较常见的一种数据结构,在很多编程语言以及中间件都有使用,比如Java,Python啊, 中间件RocketMQ,Redis等等。甚至Linux,TCP中都有队列的概念。TCP中有半连接队列,全连接队列。Linux中也有消息队列,用于进程间通信的一种方式。
看一下JAVA中的队列:
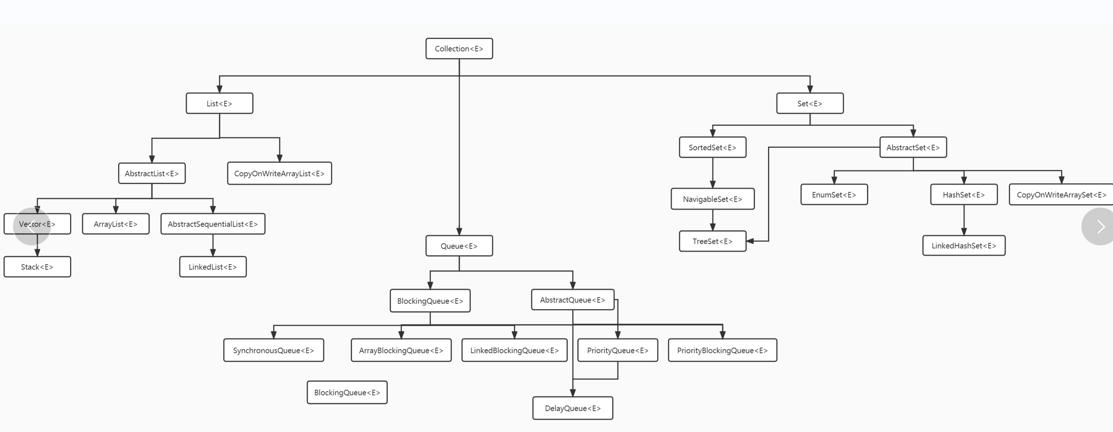
JAVA的队列应用场景更广泛一些,不同的队列支持多种使用场景,尤其是线程池中。
ArrayBlockingQueue:是一个数组结构的有界阻塞队列,此队列按照先进先出原则对元素进行排序。
LinkedBlockingQueue:是一个单向链表实现的阻塞队列,此队列按照先进先出排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool使用了这个队列。
SynchronousQueue :一个不存储元素的阻塞队列,每个插入操作必须等到另外一个线程调用移除操作,否则插入操作一直处理阻塞状态,吞吐量通常要高于LinkedBlockingQueue,Executors.newCachedThreadPool使用这个队列。这个有点像golang中的channel。newCachedThreadPool可以无限创建多个线程(当然有一个上限是Integer。Max_VALUE)。
PriorityBlockingQueue:优先级队列,是基于数组的堆结构,进入队列的元素按照优先级会进行排序。这个实际上就是比较特殊的队列了,或者说并不是队列,而是堆的结构。
上述这几个队列都是应用在线程池中,通过Lock接口的锁来实现线程安全,此外支持阻塞,如果没有数据,则消费者可阻塞等待;如果队列已满,则阻塞等待。阻塞的实现主要是借助于Condition接口。具体可看我之前写的文章:
关于线程池的介绍可以看: Java并发编程之基本使用
说完栈和队列,现在看看如何使用两个栈实现一个队列。
栈是先进后出,队列是先进先出。push数据就往第一个栈中放入数据,pop数据时,将栈1中的数据都pop出来,并push到栈中,在栈1中先进后出的,到了栈2再经过一次先进后出,就变成了整体的先进先出。下面是具体代码:
class Stack2Queue:
def __init__(self,size1,size2):
self.stack1 = Stack(size1)
self.stack2 = Stack(size2)
def push(self,a):
self.stack1.push(a)
def pop(self):
if not self.stack2.isEmpty():
self.stack2.pop()
else:
while not self.stack1.isEmpty():
self.stack2.push(self.stack1.pop())
用两个栈能实现一个队列,那两个队列也可以实现一个栈。push数据同样是向队列1中push数据,pop数据时,队列1中的数据,除了末尾的一个,全部都放到队列2中,此时队列1就是末尾的一个元素了,现在队列1 pop的数据就是最先进入的元素了。此时还没完,还要把队列2中的数据再返回队列1中,因为还要进行下一次的pop操作。
class Queue2Stack:
def __init__(self,size1,size2):
self.queue1 = Queue(size1)
self.queue2 = Queue(size2)
def push(self,data):
self.queue1.push(data)
def pop(self):
while self.queue1.size!=1:
self.queue2.push(self.queue1.pop())
result = self.queue1.pop()
while not self.queue2.isEmpty():
self.queue1.push(self.queue2.pop())
return result
3、堆
上面说完了栈和队列,再说下堆。
堆是一种特殊的结构,分为最大堆(也叫大根堆)和最小堆(也叫小根堆)。这里就拿最小堆来说了。
在Python中有内置的heapq堆模块,在里面,有这样一个定义:堆是一个数组,且满足一个条件:当前位置k,a[k]<=a[2*k+1] and a[k]<=a[2*k+2]。
有了上面的条件,那对于一个列表,我们可以很轻松滴将其转换为最小堆。具体代码:
def heapify(array,index):
"""
as for every index,we compare parent and two children:left and right
the parent is the index.
the heapify is for minheap
"""
leftchild = lambda x:2*x + 1
rightchild = lambda x:2*x + 2
end = len(array) - 1
while True:
if index > end:
break
left = leftchild(index)
if left > end:
break
right = rightchild(index)
# get the more smaller.
child = right if right <= end and array[right] < array[left] else left
print child,array[left],array[right]
#if the smaller of the children is smaller than arrray[index],no need to exchange any more
if array[child] >= array[index]:
break
else:
#should recurise until break.
array[child],array[index] = array[index],array[child]
index = child
def list_2_heapq(array):
length = len(array)
for index in range((length-1)/2,-1,-1):
heapify(array,index)
array=[3,6,5,7,4,8,1]
list_2_heapq(array)
我在上面代码中也都写了注释,应该很好理解。heapify是一个很重要的函数,它用来比较父节点和左右两个子节点的值的,满足一定条件是要交换的。
比如现在有一个现成的堆,我现在要插入一个元素,那肯定要放到正确的位置。就从根节点开始比较呗,如果我比两个子节点都小,就把子节点最小的那个和这个节点交换。并把当前位置下移动刚才交换元素的位置。再进行上述操作,直到达到最小堆的底部。
堆可以用来解决TopK的问题,最大K个值或者最大K个值。
在Java中的,优先级队列就使用了堆的结构。Timer、ScheduleTheadPool都有使用。其会根据延迟时间来排序。具体可以看DelayQueue,DelayWorkerQueue,PriorityQueue等源码。
参考资料:
微信分享/微信扫码阅读

