
个人后端知识点总结
看了国外一哥们写的谷歌面试大学,感受很多。想起了自己在考研的经历。那时的我和他一样,所有事情都会预先制定计划,然后循序渐进地、一步一步地执行,最终实现自己的目标。这几年虽然之前也制定了很多的规划和安排,但总觉得差了一些东西,有时是不能有始有终,有时是不能全身心投入。
看完这哥们写的文章,我觉得我还是更需要一份决心,去挑战更多的不可能,我承认我现在对目前的工资不是很满意,我希望可以得到更多。那如果有了目标,就应该付出同等或者甚至更多的努力。
整个学习过程切忌眼高手低,浮躁,一定要脚踏实地得学好每个知识点。这里的学习的确都是应对面试的,具体的问题。
好了,也不说太多的废话了,开始我的学习之路。
目录:
- 计算机系统
- 网络
- 数据结构
- 算法
- 设计模式
- JAVA、Springboot、Mybatis,Dubbo
- 分布式系统
- 数据库Mysql,了解TiDB
- Redis
- 消息队列 RocketMQ,RabbitMQ,Kafka
- 并发编程 多进程、多线程、IO多路复用、协程
- 高并发、高可用、高可扩展
- 实战-单点登录
- 实战
- 总结
注:本文内容会不断补充。里面涉及到的文章链接基本上都是我在自己网站上写的。
一、计算机、操作系统
所写过的文章列表:
计算机原理:CPU、寄存器、缓存等等
操作系统:Linux系统、零拷贝、系统命令、问题排查等等
1、CPU是如何执行代码的;
CPU每次执行过程是从RAM中获取指令(fetch),然后进行解析(Decode),然后执行指令(Execute),最后回写到主存中。可参考: 计算机系统介绍
2、缓存的分类和作用以及如何保证缓存一致性;
缓存主要为了解决高速CPU处理速度与缓慢的读取内存数据的矛盾。通常分了多层缓存,L1,L2,L3等。靠CPU越近,速度更快,数据更少。因为有缓存,所以会出现数据一致性的问题,通常会通过MESI协议来控制,但也不是绝对的,可参考: 高并发之缓存
3、寄存器和存储器;
寄存器是CPU的一部分,用来存储指令和数据的,通常容量都比较小。寄存器主要有计数寄存器,基数寄存器,数据寄存器等等。
存储器是一个通称,主要包括内部存储器(RAM,ROM),也有外部存储器,比如U盘,硬盘等等。
操作系统
1、进程、线程,进程和线程的区别;
之前写过的关于进程介绍:
进程是运行中的程序,是系统资源分配的基本单元,进程间的数据不可共享,且上下文切换比较耗费资源。之前写的文章: Linux进程的介绍
线程是进程的一部分,是CPU调度的基本单元,它主要的目的是解决进程切换的资源消耗,此外同一个进程的多个线程之间可以共享变量。在Linux中也被称为轻量级进程,两者的结构都是task_struct,只是线程结构体里多了一个ppid,表示进程id。
线程可以分为用户线程和内核线程,内核线程是由操作系统控制的,目前也是多数采用的方法。
2、虚拟存储?
就是使用内存+外存的方式,提高资源使用率。每个进程都会分配独立的虚拟地址空间,虚拟地址空间包括用户空间和内核空间,系统会只把当前需要的数据加载到内存中,不需要的先放到外存中。如果查询的数据或代码不在,就会抛出缺页异常,系统会负责将对应程序或数据从外存加载进来。虚拟地址空间包括数据段、代码段、堆、栈、段表等等。
3、进程间通信方式?
如果想实现进程的同步或者通信就需要使用对应的中间介质,比如信号量、FIFO、共享内存、管道等等。
4、分页和分段?
分页和分段都是实现非连续分配内存的方法,在出现虚拟存储之前就存在的两种方法。分页和分段都是为了提高内存使用率、实现地址隔离的方法。只是分段是将程序分成多个块,每个块是一个段,每个段的地址是连续的,段之间是可以不连续的。 这种方式就是很容易产生碎片。
分页是对分页的改进,将空间分成更笑得页,物理页叫页帧,逻辑页叫页面。通过页表实现逻辑页面和物理页面得映射。单个页面的大小是比较有讲究的,一般都是4K,设置太大或太小都不好。由于页面相对比较小,因此可能页数比较多,查找比较困难,一般都是通过TLB缓存,或者多级页表来提高查询性能。
5、死锁,产生条件?
死锁的产生条件主要是进程间互斥、持续持有且等待、非抢占、循环等待。https://xie.infoq.cn/article/8423f8eb9ebdcb4b494b81290
线程崩溃了,进程会崩溃吗?
如果线程出现了非法访问,是会导致进程崩溃的。因为进程内的内存,资源信息是共享的,系统这样也是为了保护资源。比如当出现内存非法访问时,进程就会崩溃,就会报段错误。
不过,可以通过自定义信号处理函数来避免进程崩溃。当线程非法访问内存时,会触发一个SIGEGV的信号,进程接到这个信号,可以根据实际信号处理函数来决定做一些额外的工作,比如退出前做一些工作,或者干脆忽略该信号。
JVM就是当线程崩溃时,不会导致线程崩溃。因为其在收到SIGEGV信号后,其会执行自定义的信号处理函数。会恢复进程,并抛出异常。
这里还要提到JVM的钩子函数,ShutdownLook,通过设置钩子函数可以实现优雅停机,即当进程接收到kill信号,比如SIGTERM,可先执行钩子函数,然后再退出。当然,如果是SIGKILL,即我们常用的kill -9 ,则会直接退出。
根据此特点,很多框架都会实现优雅停机,比如springboot,netty等等。
数据I/O
磁盘->磁盘控制器->磁盘驱动->DMA->虚拟文件系统->内核->CPU。我在头条上还发表过关于零拷贝浅谈的文章: Linux零拷贝技术浅谈
文件系统
磁盘文件系统、内存文件系统、网络文件系统。
JAVA多线程,这个之前自己在github上写了关于关于多线程的电子书: 多线程介绍
二、网络
网络相关文章列表: 网络相关系列文章
DNS、TCP、UDP、HTTP、HTTP2 、HTTPS等等
1、TCP协议的拥塞控制和流量控制?
流浪控制的目的时控制发送方的发送速率,避免接收端来不及接收。通常的做法是通过滑动窗口来控制。发送端的发送端口不得大于接收端的滑动窗口。在连接建立时接收端会告诉发送端差窗口大小,rwnd 表示 receiver window。
如果收到了对方的零窗口,且一直再未收到接收端的有效窗口,正常发送方会一直等待。针对该问题,TCP设置了一个定时器。当收到零窗口时,开始计时,到时间了会主动询问对方的滑动窗口大小,如果还是0,则计时器重置,接着上述操作。
此外,还有其他机制取控制发送速率。
1、TCP维持一个变量,它等于最大报文段长度MSS。只要缓存中存放的数据达到MSS字节时,就组装成一个TCP报文段发送出去。
2. 由发送方的应用进程指明要求发送报文段,即TCP支持的推送( push )操作。
3. 发送方的一个计时器期限到了,这时就把已有的缓存数据装入报文段(但长度不能超过MSS)发送出去。
拥赛控制是作用于网络的,它是防止过多的数据注入到网络中,防止网络负载过大。主要的方法有:
慢开始( slow-start )、拥塞避免( congestion avoidance )、快重传( fast retransmit )和快恢复( fast recovery )。
慢开始:发送端维持一个拥塞窗口cwnd(congestion window),刚开始设置为1,发送方发送窗口要小于等于拥塞窗口。每经过一次往返,就将cwnd加倍。它的目的就是控制发送端不要一开始就发送大量的数据到网络中。
拥塞避免:它和慢开始的区别是拥塞窗口不是指数增长,而是每次加1。通常情况下是将慢开始和拥塞避免一起使用。会设置一个门限:ssthresh。
比如我们初始化拥塞窗口cwnd=1 ,门限设置为ssthresh。在cwnd<ssthresh时,使用慢开始算法。当cwnd>ssthresh时,开始采用拥塞避免的算法。
此外,当检测到网络出现拥塞时,会把ssthresh减半,cwnd重新设置为1,然后开始执行慢开始算法。
快速重传:当接收端收到失序的包,就应该立即发送重复确认,如果发送端收到连续三个重复确认,那么就要立即对数据包进行重传。SACK和DACK是两种实现方式。SACK可以知道哪些数据需要重传;DACK可以说明是网络延迟还是就是丢包引起的。
快恢复是当连续收到三个确认之后,将ssthresh门限减小,这是为了避免出现网络拥塞。
然而由于收到连续三个确认,证明此时并没有出现拥塞,所以没必要立即就执行慢开始算法,而是执行拥塞避免算法。

2、TCP的粘包和拆包,Dubbo,Netty等解决方式?
关于TCP的粘包和拆包,在我另一篇文章有介绍: TCP/IP传输层 图解 | 为嘛有 TCP 粘包和拆包
3、TCP的建立三次握手,四次挥手 过程。挥手中TIME_WAIT为什么需要2MSL时间。和CLOSE_WAIT的区别。
之前转载了一篇文章介绍的非常好: https://hbnnforever.cn/article/wechat6.html
之所以采用三次而不是两次,防止之前无效的报文段因为长时间滞留在网络内,又重新到达服务端,如果只有request和ack,那么可能建立的是无效的连接。只有请求端再发一个ACK,才能确保这个是有效的。
在TCP建立的过程中,如果服务端没有Listen,客户端发送请求,是不会建立连接的,服务端会直接回复一个RST,释放连接。如果服务端没有accept,是会成功建立连接的。因为三次握手的过程中,是不需要accept的,accept的作用只是从全连接队列中拿出一条已建立的连接处理。
挥手过程是四次的原因是因为它是一个全双工通信,单个发只会保证某一端不发送,但其仍可以接收,另一端仍可以发送。
当然,四次挥手是完全可以合并为三次挥手的,这要建立在一个前提下:没有数据需要发送,且开启了TCP延迟确认机制。延迟策略:
- 当有响应数据要发送时,ACK 会随着响应数据一起立刻发送给对方;
- 当没有响应数据要发送时,ACK 将会延迟一段时间,以等待是否有响应数据可以一起发送;
- 如果在延迟等待发送 ACK 期间,对方的第二个数据报文又到达了,这时就会立刻发送 ACK
被动方传FIN时,还要把上一个的ack值也带上,从而确认是哪一个。
从TIME_WAIT到CLOSED用2MSL,是因为一是希望所有在此次连接中的报文都消失,等待2MSL,几乎都消失了。另一个就是假如主动方的ACK,被动方没有收到,被动方会重传FIN,这一来一回就是2MSL。 CLOSE_WAIT是被动方的状态。在接收FIN发送ACK之后会进入该状态。
4、统计系统的TCP
netstat -n|awk '/^tcp/ {++S[$NF]} END {for (item in S) print item,S[item]}'
5、HTTP2的区别。https的优势特点
http2的主要目标就是提升性能,为此,其做了很多的改进。
http2增加了二进制分帧层,允许数据以更小的帧发送,可以乱序发送。采用多路复用的形式发送数据,此外还支持服务端主动推送数据,还可以控制请求的优先级。总之,http2的性能得到了一定的提升。
1、二进制帧
Frame 是最小的传输单位,通过二进制编码可以用更少的字节传输,比如 状态码200,之前可能需要三个字节,二进制编码可能只需要1个字节。
2、压缩头
通过静态码表、动态码表以及霍夫曼编码实现头部压缩,以及避免重复传输。一些常见的字符串可以避免重复传输。
3、Stream流
通过stream流实现并发复用连接。每个连接拆成多个stream,不同连接的stream可以是乱序的,且相互独立。完全做到了并发使用。
HTTP2已经非常优秀了,但存在的一个问题是如果TCP丢包了,可能会阻塞等待重传后处理。后续又出来了Http3,基于使用QUIC协议的UDP,不过目前还没有完全普及。
6、连接的半开和半关。
半开指的是TCP连接的一方因为断电或者其他原因出现异常故障,此时不能进行数据传输了。由于本端也无法感知对端,所以连接会一直处于建立ESTABLISHED状态,但是不能通信。
半关指的是连接两端只有一方发送了FIN,另一方并没有发送FIN,这种状态就是半关状态,处于这个状态时,没有关闭的一方时可以继续发送数据的。
7、https握手流程
可以参考: https://zhuanlan.zhihu.com/p/344086342
wireshark抓包:

https连接流程:
1、客户端发送Client Hello,包括支持的协议版本号、支持的加密算法、密码套件、一个随机数(用于后面生成会话密钥);
2、服务端发送Server Hello,包括选择的TLS协议版本号、密码套件,一个随机数(同样是用于生成后面的会话密钥);
3、服务端接着Certificate, Server Key Exchange, Server Hello Done消息,这里面包括CA证书、密码交换算法需要的额外数据(premaster);
4、客户端验证证书;
5、证书验证通过后,客户端发送Client Key Exchange,Change Cipher Spec,Encrypted Handshake Message。
上面也提了,在 “Server Key Exchange” 消息中,服务器对 Server Params 用私钥做了签名,客户端要从证书中获得服务器公钥,验证参数是否来自期望的服务器,这也是身份验证。
身份验证成功之后,得到 Server Params 参数,而 Server Params 参数里包含了 “服务器密钥交换消息” 中生成的临时公钥、secp256r1 椭圆曲线算法,现在客户端使用 secp256r1 算法用这个临时公钥和客户端自己生成的临时私钥相乘计算出预主密钥(premaster secret)。
户端手里已经有了 Client Random、Server Random、Premaster Secret 三个随机参数,调用 PRF 伪随机函数函数生成 48 字节(384 位)主密钥。
“Change Cipher Spec” 消息表示客户端已生成加密密钥,并切换到加密模式。
Encrypted Handshake Message是将之前所有的握手数据做一个摘要,再用最后协商好的对称加密算法对数据做加密,通过 “Encrypted Handshake Message” 消息发送到服务器进行校验,这个对称加密密钥是否成功。
6、服务端进行和第五步客户端同样的操作,生成会话密钥、发送之前参数的摘要加密后的数据,供客户端验证。
注意上述的会话密钥生成方式是ECDHE协商算法。客户端和服务端都会生成一个密钥和公钥,公钥发给对方,私钥保存。
公钥+两个随机数可以生成会话密钥。
三、数据结构
链表、数组、堆栈、字符串、队列、树、图、哈希表、红黑树、跳跃表等等。
剑指offer相关题目的总结: 剑指offer
链表:
- 反转链表。指定位置反转
- 两个链表的第一个公共节点
- 回文链表检测
- 链表环路检测
- 链表的旋转
- 环的入口点
- 链表两数相加
- 链表排序,学会使用归并排序排序链表,注意中间节点的处理。
- 删除重复元素
- 删除倒数第n个节点
- 每K个一组反转;
- 奇偶重排
对于链表要学会使用虚节点、双指针等方式。虚节点通常是要处理首个节点的时候需要使用,比如可能会删除首节点(删除重复元素、删除倒数第n个节点),双指针在中间节点,找环,旋转等等。
链表的典型应用,内存淘汰(Linux,Mysql),JAVA中的LinkedList,LinkedBlockingQueue,AQS,LinkedHashMap等等。
栈和队列:
-
两个栈实现一个队列;
-
两个队列实现一个栈;
字符串:
- 字符串反转
- 回文判断
- 最长回文子串
- 最长不重复子串
- 两个字符串的最长公共子串
哈希表:
两数之和 无序的,且要求O(n)时间复杂度,借助hash表
次数出现过一次的两个数字 如果是出现一次,直接异或计算,剩下的就是出现一次。如果是两个,可以找到两个不同数据的不同的二进制数,拿着这个分别求出两个数据。
次数超过一半的数字 可以用哈希表记录次数。可以排序,取中间的。可以记录众收。进行抵消。
最小的出现的正整数 哈希表存储的是数组元素,遍历不是遍历数组,而是遍历1-n的正整数。
堆:
- 大顶堆和小顶堆的构造
数组:
- 各种排序
- 有序数组删除重复
- 合并两个有序数组
- 两数相加等于数组中某个元素
- 获取所有三元组相加等于目标数,借助排序。将三数之和降为有序的两数之和。
- 最长无重复子串
- 最小的K个数
- 数组全排列 ,无重复数据,有重复数据。
下面是有重复数据的。思想是先排序。 无重复和这个差不多,区别就是在每一层递归时,会设置一个集合来存储使用过的数据
class Solution {
public List<List<Integer>> permuteUnique(int[] arr) {
if (arr == null) return new ArrayList<>();
Arrays.sort(arr);
List<List<Integer>> result = new ArrayList<>();
if (arr.length == 1) {
List<Integer> cr = new ArrayList<>();
cr.add(arr[0]);
result.add(cr);
return result;
}
doPermutationV2(arr, 0, result);
return result;
}
private void doPermutationV2(int[] arr, int start,
List<List<Integer>> result) {
if (start == arr.length - 1) {
result.add(convert(arr));
return;
}
int index = start;
//每一层设置一个set,如果出现了就不走了。
Set<Integer> set = new HashSet<>();
while (index <= arr.length - 1) {
if (set.contains(arr[index])) {
index++;
continue;
}
set.add(arr[index]);
swap(arr, start, index);
doPermutationV2(arr, start + 1, result);
swap(arr, start, index);
index++;
}
}
private List<Integer> convert(int[] arr) {
List<Integer> re = new ArrayList<>();
for (int i = 0; i < arr.length; i++) {
re.add(arr[i]);
}
return re;
}
private void swap(int[] arr,int left,int right){
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}树:
- 二叉树的前序,中序,后序的遍历 可通过递归,最简单,也可通过栈来实现。栈实现的话,每种遍历都方式不同,前序遍历比较简单
- 二叉树的层序遍历 记录每一层的level,同一层的存储到对应level的list。还可以用队列实现,这种方式比较简单。就是把数据压进去,第一行只有root,然后把左右压进去,队列是从队首取。
- 二叉树的最大深度 递归,比较简单。
- 二叉树的最近公共祖先 通过左右子树来判断。左子树是空,就是右子树,右子树是空,就是左子树。如果都不为空,则直接返回root。递归调用。
- 二叉搜索树的最近公共祖先 根据搜索树的特性,即root大于左子树,小于右子树
- 判断是否为平衡二叉树 即左右子树高度差不超过1。一是可以自顶向下,每个root,求出所有子树最大高度,然后再计算高度差,符合再往左右遍历,时间复杂度高;另一种是自下往上,即求出最下面是否是平衡,不是就网上找,也是递归。
- 对称二叉树
- 重建二叉树 利用前序和中序结果重建二叉树。通过前序遍历root,找到在中序遍历中的root的索引,索引左边的就是左子树,右边的就是右子树。然后再根据左子树的数量,确定,在前序队列左子树的右边节点,右边节点的下一个节点就是下一个root。循环操作。
- 二叉树的右视图
- 完全二叉树
- 二叉搜索树转换为链表
- 二叉树的镜像
- 某一路径和,所有路径和等于目标值;
- 二叉树中序遍历的下一个节点;
- 二叉搜索树第K小的数;
- 后续遍历序列,判断是否是二叉搜索树
- 树的子结构
public class Solution {
int[] preOrder;
Map<Integer,Integer> map = new HashMap<>();
public TreeNode reConstructBinaryTree(int[] pre, int[] inOrder) {
if (pre == null || pre.length == 0) return null;
this.preOrder = pre;
for(int i = 0;i<inOrder.length;i++){
map.put(inOrder[i],i);
}
return doBuildTree(0,0,inOrder.length-1);
}
private TreeNode doBuildTree(int root,int left,int right){
if(left > right) return null;
TreeNode node = new TreeNode(this.preOrder[root]);
int indexInOrder = map.get(this.preOrder[root]);
int count = indexInOrder - left + 1;
int leftIndex = root + count ;
node.left = doBuildTree(root+1,left,indexInOrder-1);
node.right = doBuildTree(leftIndex,indexInOrder+1,right);
return node;
}
}- 二叉搜索树的节点之和满足某个值。递归,每次往左右遍历,直接把当前root的值加入到left,right的val上,当遍历到某个节点的val是sum则可返回。
- 验证二叉搜索树。递归调用,中序遍历。递归的本质是从下往上,每层都满足,left<root<right
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return bool布尔型
*/
int cur = Integer.MIN_VALUE;
public boolean isValidBST (TreeNode root) {
// write code here
if(root == null) return true;
if(!isValidBST(root.left)) return false;
if(root.val <= cur) return false;
cur = root.val;
return isValidBST(root.right);
}
}- 将有序数组、有序链表转化为二叉搜索树。通过二分,每次将数组或者链表分成两部分,左边就是左子树,右边就是右子树,一直递归。
- 将二叉搜索树变成双向链表。主要是利用二叉搜索树的中序遍历,中序遍历的二叉搜索树其实已经是有序的了、也就是在每一次递归中序的时候,把前一个指针和当前root链接起来即可。
- 是不是完全二叉树。完全二叉树指的是每一层都是满的,除了叶子节点,叶子节点的null只能出现在左边。可以利用队列实现层序遍历,使用标记位。(不能使用ArrayDeque,不允许有Null)
public boolean isCompleteTree (TreeNode root) {
// write code here
if (root == null) return true;
Queue<TreeNode> deque = new LinkedList<>();
deque.add(root);
boolean flag = false;
while (!deque.isEmpty()) {
TreeNode cur = deque.poll();
if (cur == null) {
flag = true;
} else {
if (flag) return false;
deque.add(cur.left);
deque.add(cur.right);
}
}
return true;
}- 二叉树的镜像 镜像是左边变成右边,右边变成左边。
二叉树要注意使用递归,栈,队列的实现,基本上逃不出这几种方法。
算法
算法的本质是在给定的数据结构中,根据一定的策略使得对于数组的增删改查效率更高。数据结构就是我们常见的几种,其中字符串,数组(包括一维,二维)最为常见。
常见的算法种类包括,查找、排序、贪心、回溯以及动态规划等等。
动态规划:
- 斐波那契数列 a,b= b,a+b
- 青蛙跳台阶 dp[i] = dp[i-1] + dp[i-2]
- 最小花费跳台阶 dp[i] = Math.min(dp[i-1]+cost[i-1],dp[i-2]+cost[i-2]),边界时 dp[0],dp[1]都是0
- 最长公共子序列 最长公共序列不一定是连续的,状态转移方程,dp[i][j] 如果是 nums[i] =nums[j],那么 dp[i][j]=dp[i-1][j-1]+1,如果nums[i]!=nums[j],dp[i][j] = Math.max(dp[i-1][j],dp[i][j-1]).
- 最长公共子串 必须是连续的子串。dp[i][j]表示的是以i和j为结尾的最长子串。如果 str1[i]和str2[j]不等,那么dp[i][j]就是0,如果相等dp[i][j]=dp[i-1][j-1]+str1[i]。
- 最长上升子序列 dp[i]指的是以nums[i]为结尾的最长子序列长度。对于i从1到len-1,每一个i进行一次遍历 ,从0到 i-1,如果nums[j]<nums[i],那么dp[i]长度就是dp[i]+1。
- 最长回文子串。 动态转移方程dp[i[j] = dp[i+1][j-1] && str.charAt[i] == str.chatAt[j] j-i>2; str.charAt[i] == str.chatAt[j] j - i=2 。 i到j表示的是在字符串中的 位置下标i,j。
- 兑换零钱 dp表示的是目标金额的状态。dp[i] = Math.min(dp[i],dp[i-nums[index]+1)。每一个金额i都要遍历一遍数组。
- 矩阵的最小路径和 由于只能向右或者向下。所以比较简单。 dp[i][j],和 dp[i-1][j] ,dp[i][j-1]有关。
- 打家劫舍。两种题,一个是不能相邻,另外一个在1的基础上是首尾也是相邻。 首尾不能相邻就是将从0到n-1分成 0到n-2以及1到n-1,求两个序列的最小值。每个序列的求法就是第一种劫舍的方法。dp[i] = Math.max(dp[i-1],dp[i-2]+nums[i])
- 剪绳子 。将长度为n的绳子剪成m段,使乘积最大。长度为i的绳子,与小于他的绳子的关系是 ,比如某个长度为j,那么dp[i] = dp[j] * (i-j)。j需要从1开始遍历一直遍历到小于i。
if(target <= 1) return target;
int[] dp = new int[target+1];
dp[0] = 1;
for(int i=1;i<=target;i++){
for (int j=1;j<=i;j++){
dp[i] = Math.max(dp[i],j * dp[i-j]);
}
}
return dp[target];动态方程主要还是要找对需要转移的状态,以及状态转移方程和边界条件。
递归:
1、全排列
- ip地址恢复; 每一层的长度是1到3,然后从第一段开始遍历,到第四段结束。
- 字符串全排列;需要用当前位置和字符串每一个元素交换,然后递归,最后再交换回来。结束时就是index等于字符串长度。
- 含有重复数字数组全排列;和第二个类似,区别是需要进行排序,然后再递归内部的循环中,如果值相等就不交换。
- 括号的所有合法组成;遍历条件是左括号和右括号的数量都不超过n个。然后添加括号。
- 矩阵的路径 二维数组,遍历行和列,i,j,如果已经经过了就不允许走了。当前元素要等
- 岛屿数量 陆地值为1,双层遍历,每一个值,如果是陆地,就开始递归,dfs内部就是走一遍,不做什么。
- 岛屿的最大面积 和岛屿数量类似,他是每个dfs都求出最大面积,dfs内部是1+上下左右的dfs的面积。然后每次取最大面积,最后返回。
排序算法:
之前写的文章: https://hbnnforever.cn/article/sortalogthriom.html
设计模式
之前写的关于设计模式的各种文章: 设计模式系列文章
1、设计模式介绍
学过计算机软件的多多少少得都会听过设计模式,其主要得目的就是提高我们系统设计和代码质量,增加我们系统可扩展性。不过我认为我们在学习的时候不必过多地注重生搬硬套,不能做本本主义,而是要灵活去应用。此外,23种设计模式并不是每一种都是很适合我们实际系统开发。如果要用到一个设计模式,要搞懂,我要用它去解决什么问题。比如单例模式,我就希望全局只有一个实例存在;你要使用观察者模式,我就是要将生产和消费解耦;使用代理模式,我就是要屏蔽我内部实现类,用代理类实现一些额外的控制等。通过模板模式可以实现复用,通过抽象类模板方法的定义,为所有子类提供通用的处理流程。下面是我之前画的脑图,并没有画出全部的设计模式。
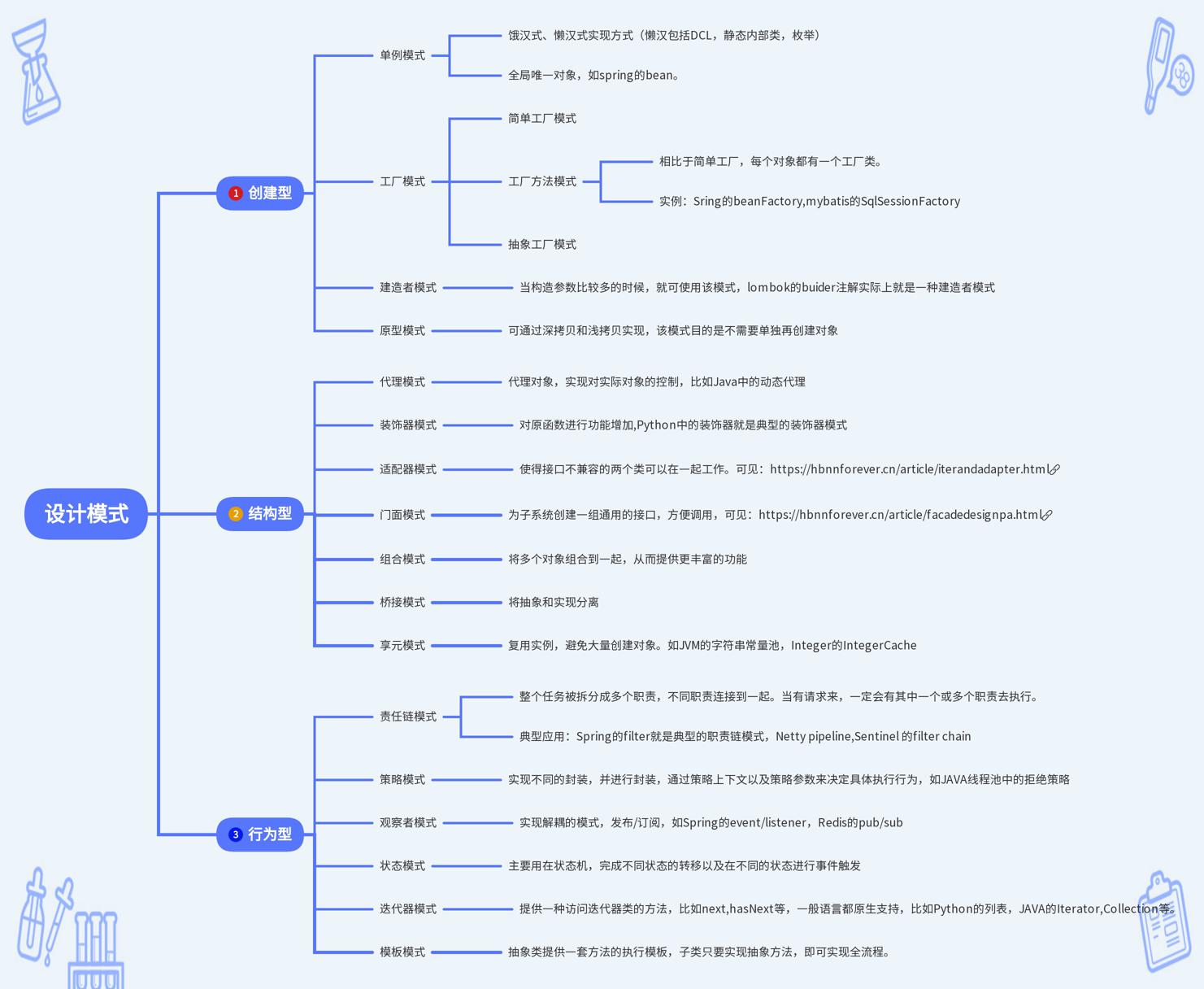
2、springboot中使用的设计模式
单例模式、代理模式、观察者模式、装饰器模式、适配器模式、工厂模式、策略模式、模板模式、责任链模式
单例模式:这个没啥好说得,IoC容器中的Bean都是单例的。
工厂模式:通过BeanFactory获取bean。
代理模式:springboot中提供了动态代理,AOP是springboot重要的概念,提供了切面编程能力,在AOP增强的地方会创建代理(卧槽,咋看着像装饰器模式,但其最重要的区别它可能和目标类本身业务无关)。具体可看之前写的文章: JAVA代理及Dubbo与Springboot的应用 。
装饰器模式:springboot中带有Wrapper和Decorator的类。
模板模式:抽象类中使用了模板模式。
观察者模式:通过事件Event的发布和listen,实现了观察者模式。
策略模式:在Bean实例化过程中需要使用InstantiationStrategy,springboot提供了simple和cglib两个策略的实现。此外,在Resource资源房访问中也实现了策略模式。此外,spring的资源访问Resource也实现了策略模式.
适配器模式:HandlerAdapter就是典型的适配器模式,对于不同的controller使用不同的handler处理。
责任链模式:Spring中的filter就是一种责任链模式,构成了一个chain,在真正到达目的请求之前,会经过一系列的doFilter。
mybatis使用了建造者模式(SqlSessionFactoryBuilder),工厂模式(SqlSessionFactory)、代理模式(Connection对象),模板模式、装饰器模式等。
3、laravel中使用的设计模式
单例模式、简单工厂模式、工厂模式、观察者模式、门面模式、模板模式;
单例模式:应该是最常见的了。
最重要的几个单个例:
$app->singleton(
Illuminate\Contracts\Http\Kernel::class,
App\Http\Kernel::class
);
$app->singleton(
Illuminate\Contracts\Console\Kernel::class,
App\Console\Kernel::class
);
$app->singleton(
Illuminate\Contracts\Debug\ExceptionHandler::class,
App\Exceptions\Handler::class
);
观察者模式:比较著名的就是laravel种的event,listener。当发生时间时,listener会自动感知,并执行后续一系列操作。观察者模式的主要作用就是解耦,减少生产方和消费方的耦合,其实就是类似于消息的发布-订阅。
门面模式:这个在laravel种真的是被大量的使用。常用的有Auth,DB,Queue,View,Redis,
Mail,Route等等很多很多。
简单工厂模式:在创建DB的底层连接器时用到了。底层额数据库可以是Mysql,SQLite,PostgreSQL等等。
switch ($config['driver']) {
case 'mysql':
return new MySqlConnector;
case 'pgsql':
return new PostgresConnector;
case 'sqlite':
return new SQLiteConnector;
case 'sqlsrv':
return new SqlServerConnector;
}
各个connector都extends Connector implements ConnectorInterface工厂模式:在Queue中,不同的driver对应不同的Connector,不同的Connector连接到不同的队列。如RedisConnector对应connect RedisQueue。其中driver是根据我们配置文件获得。在启动时我们的门面会整合各种connectors,在实际使用中会根据配置选择某一个。
模板模式:在各种abstract类中,都可以看到模板方式的使用。
3、下面单例模式是否有问题。如何实现一个线程安全的单例模式;
public class SingleProxy {
privite static Signle signle;
public Signle getSignle(){
if(null == signle){
synchronized (this){
if(null == signle){
signle = new Signle();
}
}
}
return signle;
}
public class Signle {
}
}解决方案:通过volatile或者类实现。volatile可以保证变量的可见性,避免指令重排。使用类即在初始化的过程中会增加一把初始化锁,保证在初始化过程中对其他线程是不可见的。
volatile:
public class SingleProxy {
privite static volatile Signle signle;
public Signle getSignle(){
if(null == signle){
synchronized (this){
if(null == signle){
signle = new Signle();
}
}
}
return signle;
}
public class Signle {
}
}类实现:
public class SingleProxy {
private static class ClassInstan {
public static Signle signle = new Signle();
}
public Signle getSignle(){
return ClassInstan.signle;
}
public class Signle {
}4、单例模式的懒汉和俄汉了解吗?
懒汉就是一种懒加载的方法,在执行类加载时并不创建实例,不是线程安全的,但可以通过上述说的方式实现线程安全。
饿汉在类加载时就完成了实例的初始化操作,是线程安全的。也正由于类加载就完成了初始化,相对懒汉,比较浪费内存。
JAVA
JDK(io,集合,并发,反射等)、JVM、springboot原理、mybatis原理等等。
反射: JAVA反射机制
集合: Java集合深度学习
哈希表,可以通过O(1)的时间复杂度进行访问。底层通过数实现。key会通过hash算出索引下标。
哈希表突出特点就是会出现冲突,如果冲突了可以有多种解决方案。如链地址法,这是最常见的,HashMap,Redis的哈希表等都是采用这种方法。还要线性地址法,即发现冲突就往后挪,直到没有冲突,比如ThreadLocal中的内部类ThreadLocalMap就是采用这种方式。 另外一种解决冲突的方法则是再hash,即通过多次hash取模。
HashMap为什么是线程不安全的?
1、数据丢失
在多个线程同时添加值,且两个线程hash出来的key是一致的,且对应的bucket是Null的话,可能会导致某个线程添加的key丢失了。
2、1.7存在死循环问题
jdk1.7采用的是头插法,在扩容的时候会反转链表中的节点顺序,如果多个线程同时进行扩容的话,容易出现死循环。一个比较好的解释文章: 为什么HashMap是线程不安全的
3、modCount更改也不是原子性
modCount在JAVA的很多集合中都有使用,其目的是记录集合被修改的次数,用于在迭代集合的时候,如果不同次遍历时记录的修改次数不一致,证明有修改,就会触发fail-fast机制,快速失败,提示有并发修改。
Hashmap的容量为什么是2的次幂?
最重要的原因就是为了保证hash的均匀分布。
其计算在数组的位置时,使用了 hash &(n-1),其中n就是数组的长度,当n是2的幂次时,正好n-1是全1,与运算可以尽量保留hash值得本身数据,如果不是2的幂次,n-1之后的二进制有些位置就是0,与运算可能会导致不同hash值最后计算的位置是相同,增大了hash冲突的可能性。
其次,采用2的次幂的另外一个原因是增加计算速度。我们知道,通常情况下,我们在计算key在数组中的bucket时,会进行取模运算,即拿hash % 数组长度。这种计算方式相当于位运算还是慢的。使用2的次幂,可以直接 n-1进行位运算。
线程锁: 线程的琐事
ConcurrentHashMap做了哪些改进,保证了线程安全?
三大法宝: volatile + CAS +synchronized (这里只说JDK1.8)
ConcurrentHashMap中很多属性都是volatile修饰的,从而确保可见性,比如Node的value,next节点,table数组,nextTable数组,sizeCtl等。sizeCtl是用来表示是否正在进行扩容操作。
CAS,当对应key为空时,会采用CAS操作写入。
如果对应位置有值,会通过synchronized锁加入链表或者红黑树。
其他变化:
1、rehash过程是分块,可以多个线程共同完成;
2、在添加元素时,使用了一个for循环。当对应hash的位置是空的,直接通过CAS加入;如果不是空的,则要看是否正在扩容,如果正在扩容,需要帮着做扩容;如果扩容结束了,可以通过sychronized锁向链表或者红黑树中加入元素。
3、获取元素时,如果对应bucket有冲突元素,就要看看是否在扩容,如果没有扩容直接遍历链表。如果当前值为-1,则表示是一个ForwardingNode,会到nextTable上遍历查找;当前值如果是-2,表示是红黑树,则要到TreeBin的find方法去找。
JAVA io。这个地方我是在介绍IO多路复用时写了很多,先贴出一篇最早写的。 Java的NIO及Netty
JVM虚拟机 : https://hbnnforever.cn/article/jvmknowledge.html JMM内存模型
AQS:
1、以下源码是AQS在唤醒线程时的逻辑,为什么会从后往前遍历?
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}这个主要是因为在入队时,CAS操作因为执行失败或者并发时并未执行完,会导致节点的next是null。可以看下入队的源码:
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}它先执行的是node.prev = pred,随后执行CAS,如果此时并没有成功执行(或未执行完)CAS,则next就是空的。所以,如果从后往前遍历就不会出现了。
此外,在进行取消时,首先断开的也是next节点,然后再断开pre节点。
2、waitStatus的几个状态,作用。
waitStatus主要是为了提供给后继节点使用的。当加入队列时,会将waitStatus=0的前驱节点设置为SIGNAL(-1),表示后续需要前驱节点去唤醒后继节点。
waitStatus的几个值: CANCELLED(1),SIGNAL(-1),CONDITION(-2),PROPGRATE(-3)。CONDITION证明该列已经进入CONDITION条件队列;PROPGRATE主要用于共享锁释放时能够唤醒后继节点(源于之前的bug,并发时可能会导致无法唤醒后继线程)。
当调用Condition的await时会封装一个CONTIDION状态的node,并将其加入到条件队列中,条件队列是个单链表,且没有dummyNode。
3、为什么同步队列是双向链表。后继节点用于唤醒后继节点,前节点会见前驱节点的waitStatus设置为SIGNAL,用于告诉前驱节点,随后要把我唤醒,我先挂起了。
JAVA的SPI机制以及Dubbo的优化 : JAVA类加载机制以及SPI
Spring:
1、请求响应的流程;
https://hbnnforever.cn/article/springbootrequestresp.html
2、启动流程;
1、准备环境;
2、创建应用上下文ConfigurableApplicationContext;
3、刷新应用上下文refresh,这个步骤非常重要,做了很多工作。 解析配置、注册bean,启动Web容器等。
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();4、事件处理。实现BeanPostProcessor方法的类。
5、发布启动和就绪事件
3、Spring Bean的作用域;
包括单例、proptype,request,session等。
4、Bean的生命周期;
容器化启动->前置处理器->初始化->后置处理器->销毁。https://github.com/Homiss/Java-interview-questions/blob/master/%E6%A1%86%E6%9E%B6/Spring%20%E9%9D%A2%E8%AF%95%E9%A2%98.md
5、Spring如何解决循环依赖
Spring只能解决单例的循环依赖,对于使用构造器或者prototype类型的Bean,是无法解决循环依赖的。
通过三级缓存。第一级存储的是对外使用的bean对象。第二级缓存存储的是半成品的bean,可能还未初始化。第三级别缓存存储的是objectFactory。
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);A依赖B,B依赖A,实例创建过程(doCreateBean):
- A调用doCreateBean开始进行实例化,此时还没有进行属性填充和实例化;
- 创建A的objectFactory,并将其添加到三级缓存singletonFactories中;
- 此时需要注入对象B,发现B在一级,二级,三级缓存中都不存在,就会执行doCreateBean;
- B进行实例化操作,此时也没有进行属性填充和实例化;
- 创建B的objectFactory,并将其添加到三级缓存singletonFactories中;
- B开始注入A,发现A在三级缓存中存在,并将其放进二级缓存中,同时删除三级缓存;
- 将A注入到对象B中,此时A还未进行属性填充和实例化;
- B对象完成属性填充和实例化,并将B放入一级缓存中;
- 对象A继续完成属性填充,从一级缓存中得到完成品对象B,完成属性填充和初始化操作;
Bean获取的调用链路:
AbstractBeanFactory.doGetBean ->
DefaultSingletonBeanRegistry.getSingleton ->
AbstractAutowireCapableBeanFactory.createBean ->
AbstractAutowireCapableBeanFactory.doCreateBean ->
DefaultSingletonBeanRegistry.addSingleton为什么要设计成三级缓存呢?二级缓存能否解决循环依赖的问题?
实际上通过二级缓存同样可以解决循环依赖,三级缓存只是为了延迟代理对象的创建,这样符合spring的设计原则。正常来讲,创建对象Bean时,完成属性填充和初始化之后,才去创建代理对象。但出现循环依赖的情况下,就需要提前创建代理对象。刚开始是创建对象的objectFactory,只有有其他对象注入该Bean的时候,才真正执行objectFactory.get()对象获取对应的代理对象。如果没有循环依赖就不需要提前创建代理对象。
循环依赖文章: Spring 解决循环依赖必须要三级缓存吗? Spring循环依赖三级缓存是否可以去掉第三级缓存?
循环依赖面试题: https://blog.csdn.net/BigBug_500/article/details/109050337
5、Spring的IoC;
https://hbnnforever.cn/article/springbootioc.html
6、Spring的AOP;
https://hbnnforever.cn/article/springaoppractice.html
7、Spring的事务;
Spring的事务是完全使用Spring AOP实现的。支持不同的事务传播机制、不同的事务隔离级别(只限于单个connection上,不会更改数据库本身的隔离级别)
8、springboot的自动装配机制
通过自动装配,解决了spring繁琐的配置华。实现原理使用SPI机制,通过定义接口规范,并扫描classpath路径下META-INF/spring.factories,并将EnableAutoConfiguration实现类加载到容器中。较好的文章: springboot如何实现自动装配的
Mybatis
Mybatis执行流程
在启动时利用MybatisSqlSessionFactoryBean调用SelSessionFactoryBuilder创建SqlSessionFactory,SqlSessionFactory创建SqlSession,SqlSession会调用Exectutor,Executor会调用handler。
Connection会在真正执行sql语句的时候才会创建(如果是连接池的方式,不需要每次都创建新的)。
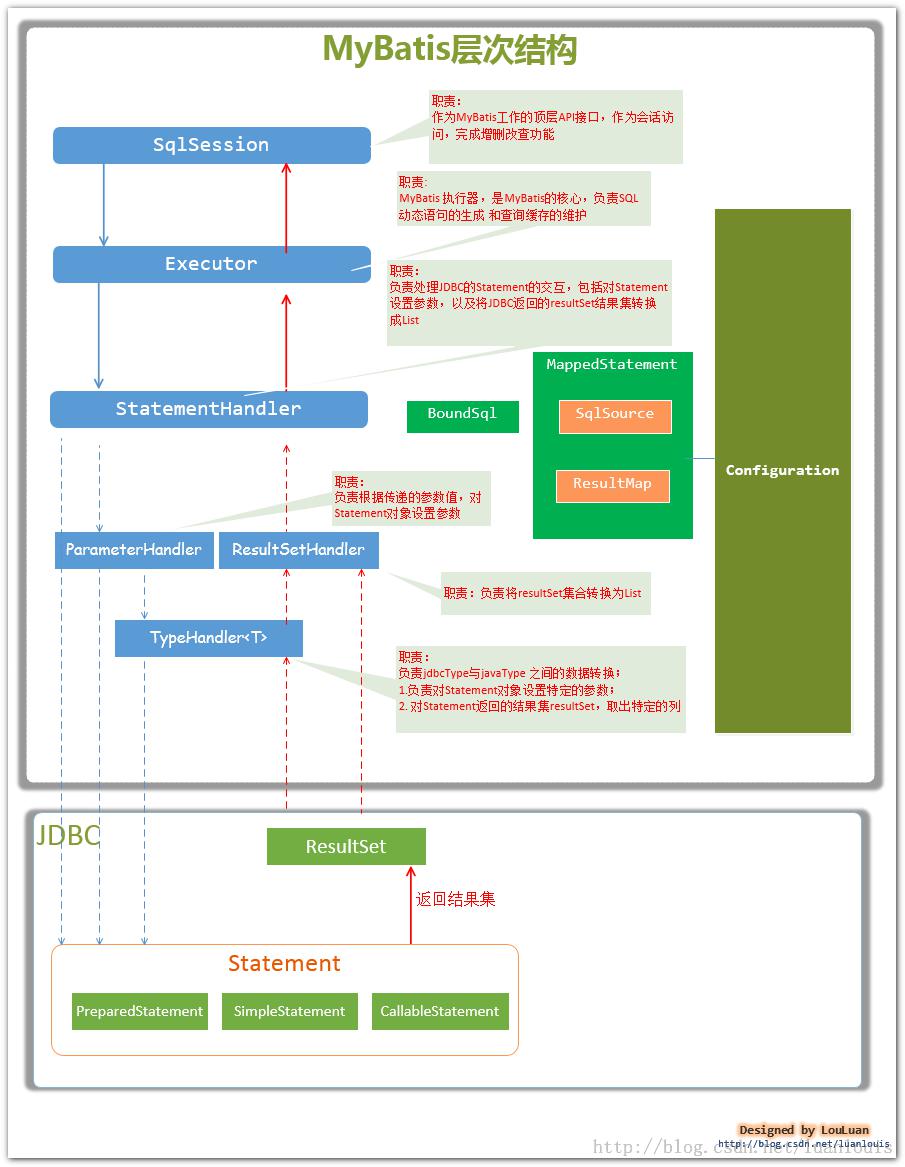
动态sql原理
动态sql的拼接依赖于SqlNode,SqlSource最终获得BoundSql,即最终的sql语句。
在启动时,SqlSessionFactoryBean会使用XMLConfigBuilder解析配置文件。
五、分布式系统
分布式理论、分布式应用、分布式一致性算法、分布式事务、分布式锁、Dubbo、注册中心、负载均衡等等。
共识算法: 分布式一致性共识算法
负载均衡: 负载均衡
分布式事务: 分布式事务介绍
分布式锁: 分布式详解
分布式id: 分布式唯一id生成
六、数据库
分库分表、索引、锁、优化、分布式ID等等
1、Mysql基础数据类型;存储空间、类型特点等等: Mysql基本类型
2、事务;事务的特性、锁、嵌套事务、分布式事务等等: Mysql事务和锁
数据库内部的XA 2pc事务,redo log和binlog,保证主从数据库的一致性。XID保证一个事务。
3、索引;索引结构、索引类型等等。 Mysql索引
索引失效: 隐士转换(字符串转换成数字,注意如果字段是整数,参数是字符串的话,只是会转换参数,所以索引是有效的),最左匹配原则(模糊,联合索引),使用函数计算,表达式。 or 如果有一列没有索引,也不会走索引。
not 查询。Mysql会根据数据情况来决定是否走索引,如果使用了覆盖索引,就会用到索引,只是扫描的是索引树。如果是select * from not in ,那么就会全表扫描。例子:
service_number是普通的索引。
mysql> explain select service_number from t_jm_blue_invoice_detail where service_number not in ("Ddw3335")\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_jm_blue_invoice_detail
partitions: NULL
type: index //表示使用了索引,但需要扫描整个索引
possible_keys: idx_oid
key: idx_oid
key_len: 138
ref: NULL
rows: 554
filtered: 100.00
Extra: Using where; Using index //Using index表明使用了覆盖索引。Using where表示扫描整个索引了
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
mysql> explain select * from t_jm_blue_invoice_detail where service_number not in ("Ddw3335")\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_jm_blue_invoice_detail
partitions: NULL
type: ALL //全表扫描了
possible_keys: idx_oid
key: NULL
key_len: NULL
ref: NULL
rows: 554
filtered: 100.00
Extra: Using where //全表扫描了。
1 row in set, 1 warning (0.00 sec)
另外再说一下,就是Using index condition表示的是索引下推。
4、查询优化、性能优化; 存储、查询、操作系统、磁盘等等。 Mysql开发规范 慢sql查询和性能优化
索引的创建:不要建立冗余的索引,尽量使用联合索引从而节省空间,索引列的区分度是否高,索引要not null。
查询:
避免出现上述提到的索引失效的场景。
尽量使用Preparedstatment,他不仅可以防止SQL注入之外,还可以提升性能;
尽量避免嵌套语句的使用。
尽量查询尽可能少的列,避免回表扫描
Buffer Pool 空闲页、脏页、LRU链表(young,old区域)。注意内部使用的内存淘汰机制。 BufferPool机制详解
未来真正的趋势是分布式数据库,比如TIDB等。
七、Redis
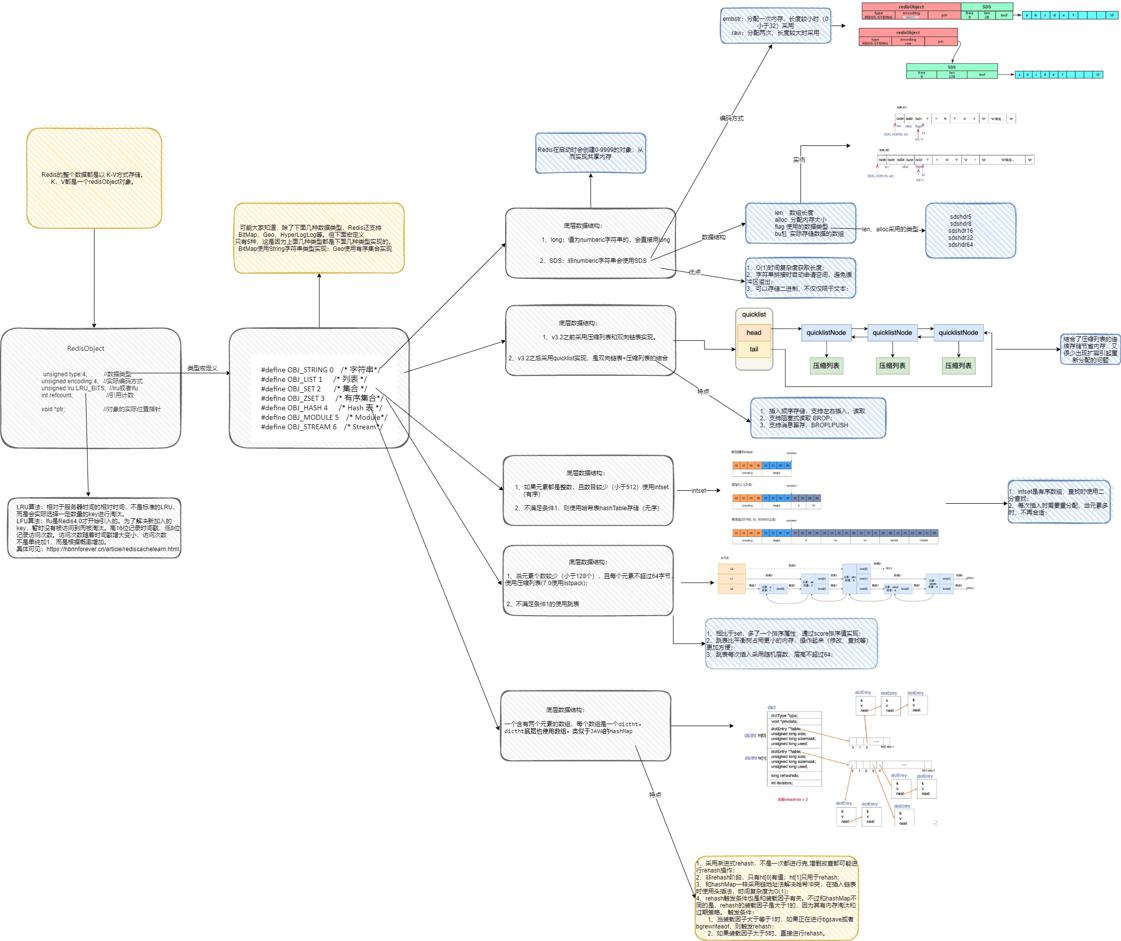
- Redis数据结构;自己画了一张脑图,但好像看得不是特别清晰呢。
- Redis持久化、事务、管道、LUA、分布式锁;
支持AOF和RDB
AOF会fork子进程进程,在创建子进程以及复制页表时会阻塞,此外如果是同步刷盘也会阻塞。
会将数据先写到AOF缓冲区,随后调用write写入内核缓冲区PageCache,至于什么时候刷盘还要取决于配置的刷盘机制,机制包括Always,每秒(默认),以及No,No就说明由操作系统自行控制,Redis不调用fsync函数。
如果在持久化的过程有新命令,就将其加入到重写缓冲区,随后会将重写缓冲区的数据写入到AOF文件中。
AOF还支持重写策略,避免数据过大(64M),重写的思想是将对一个命令的多次操作合并位一个操作,尤其是一些覆盖的操作,基本上是采用最新的命令。这样就避免AOF文件过大。
AOF的缺点就是可能文件过大,还有一种持久化方式是快照RDB。
类似于Mysql的row模式,只保存当前数据。他会以快照的形式存储,即执行一次会将所有内存的数据以快照的方式保存下来,可通过save,bgsave(非阻塞,通过fork子进程实现)的命令执行。
其优点就是文件更小,更容易恢复,但由于是保存所有数据,因此在执行时比较耗时。
目前可以配置混合持久化,RDB和AOF。可以先使用RDB保存,随后再有命令,就以追加的形式以AOF的方式存储。
避免大key的使用,大key会影响持久化,此外大key操作起来比较耗时。
- Redis消息队列、缓存(redis6);
- Redis并发,多路复用,多线程;
- Redis-cluster集群相关所有知识;
主从复制: 全量复制、长链接传播、增量复制。
涉及到replation buffer, replacation backlog buffer,前者是用于全量复制期间,新产生的命令。后者是用于增量复制时,查找到服务器写的offset和从服务器读offset的差异,从而进行增量复制。
全量复制之后,会保留该长链接,有新命令可以异步传播。
Redis缓存淘汰: Redis缓存
Redis的高并发; Redis高并发
Redis的高可用: Redis集群
- Redis通信协议;Redis客户端的实现,诸如连接,连接池等等。JAVA,Python,Golang(hredis的完善);
八、消息队列
Rocketmq、Kafka、Rabbitmq等
消息队列文章: 消息队列系列文章
RocketMq作为一款为电商业务而生的系统,比较不错,目前也是小米在用的。支持半事务、支持顺序消息、支持定时和延迟消息、消息轨迹、消费端可并发消费、支持tag级别。
Kafka主要还是用于日志收集,不对外提供定时功能,虽然内部有定时,但只是内部使用,通过时间轮实现的。
Rabbitmq,阅后即焚,不支持消费组,但支持消息优先级(通过不同的队列实现)、主要采用Push模式(容易出现性能瓶颈)、Erlang开发,不是特别友好。
九、并发编程
NIO、Netty、多路复用、多进程、多线程、协程、异步IO等等。
这个地方,我花了很多的经历。自己在gitbook上尝试着写了电子书,并同步到github上了: 多任务编程思想
Netty几大问问题点:
1、BIO、NIO和AIO模型的区别
2、同步与异步、阻塞与非阻塞的区别
3、select、poll、epoll的机制及其区别
4、Netty底层操作与Java NIO操作对应关系如何
5、Netty的线程模型是怎样的,与Redis线程模型有区别吗
多Reactor多线程模型,Redis是单Reactor单线程模型。
6、说说Reactor响应式编程是怎么回事
7、Netty的粘包/拆包是怎么处理的,有哪些实现
根据定长、特殊字符等处理粘包。
8、Netty的protobuf编解码机制是怎样的
9、Netty如何实现断线自动重连
- 客户端启动连接服务端时,如果网络或服务端有问题,客户端连接失败,可以重连,重连的逻辑加在客户端。
-
系统运行过程中网络故障或服务端故障,导致客户端与服务端断开连接了也需要重连,可以在客户端处理数据的Handler的
channelInactive方法中进行重连。
10、Netty如何支持单机百万连接
高性能的处理机制,见下面。
11、说下Netty零拷贝的原理
实现上调用的是fileChannel的transferto,底层调用的是sendfile系统调用,来实现文件的零拷贝传输。这个之前在零拷贝浅谈中有所介绍。
12、说下Netty如何实现长连接心跳保活机制
首先可以利用TCP层的KeepAlive,会检查TCP连接是否正常(Netty可以设置SO_KEEPALIVE)。其次在应用层面可以实现心跳连接保活机制,比如可以利用IdleStateHandler实现心跳保活机制。
Netty的客户端和服务端都会定时发送心跳消息给对方。
13、Netty的内存池是怎么实现的
14、Netty是如何解决NIO底层epoll空轮询导致CPU 100%的Bug
通过设置空旋转的次数,达到一定阈值后会重建selector。
15、Netty高并发高性能体现在哪些方面
高效的多Reactor多线程模型
异步非阻塞
串行无锁化 。如果不是当前线程绑定的NioEventLoop,则将任务添加到队列中,随后由当前线程去消费。
零拷贝
内存池
高效的并发编程。使用了JAVA的高效并发编程技巧。volatile,CAS等等。
高效的序列化框架。 采用了Google的ProtoBuf序列化。
十、高并发、高可用、高可扩展
文章:
高并发主要能解决瞬时系统高流量的情况。通过优化代码、scale-up,scale-out,负载均衡,缓存、消息队列等等不同手段来解决。
高可用:集群冗余备份、分布式、同城双活、异地多活、集群容错机制,高可用离不开故障自动切换。包括基础网络专线业务异常的切换、应用Server的故障切换等等。
高可扩展:对修改关闭,对扩展开放这是SOLID中比较重要的原则。通过模块化、微服务拆分、设计高内聚低耦合的分布式系统,借助SOLID、设计模式等手段来实现。
微信分享/微信扫码阅读

